package io.micronaut.http.server.netty.websocket;
import io.micronaut.websocket.WebSocketBroadcaster;
import io.micronaut.websocket.WebSocketSession;
import io.micronaut.websocket.annotation.*;
import java.util.function.Predicate;
@ServerWebSocket("/chat/{topic}/{username}") (1)
public class ChatServerWebSocket {
private WebSocketBroadcaster broadcaster;
public ChatServerWebSocket(WebSocketBroadcaster broadcaster) {
this.broadcaster = broadcaster;
}
@OnOpen (2)
public void onOpen(String topic, String username, WebSocketSession session) {
String msg = "[" + username + "] Joined!";
broadcaster.broadcastSync(msg, isValid(topic, session));
}
@OnMessage (3)
public void onMessage(
String topic,
String username,
String message,
WebSocketSession session) {
String msg = "[" + username + "] " + message;
broadcaster.broadcastSync(msg, isValid(topic, session)); (4)
}
@OnClose (5)
public void onClose(
String topic,
String username,
WebSocketSession session) {
String msg = "[" + username + "] Disconnected!";
broadcaster.broadcastSync(msg, isValid(topic, session));
}
private Predicate<WebSocketSession> isValid(String topic, WebSocketSession session) {
return s -> s != session && topic.equalsIgnoreCase(s.getUriVariables().get("topic", String.class, null));
}
}Table of Contents
Micronaut
Natively Cloud Native
Version: 1.0.0
1 Introduction
Micronaut is a modern, JVM-based, full stack microservices framework designed for building modular, easily testable microservice applications.
Micronaut is developed by the creators of the Grails framework and takes inspiration from lessons learnt over the years building real-world applications from monoliths to microservices using Spring, Spring Boot and Grails.
Micronaut aims to provide all the tools necessary to build full-featured microservice applications, including:
-
Dependency Injection and Inversion of Control (IoC)
-
Sensible Defaults and Auto-Configuration
-
Configuration and Configuration Sharing
-
Service Discovery
-
HTTP Routing
-
HTTP Client with client-side load-balancing
At the same time Micronaut aims to avoid the downsides of frameworks like Spring, Spring Boot and Grails by providing:
-
Fast startup time
-
Reduced memory footprint
-
Minimal use of reflection
-
Minimal use of proxies
-
Easy unit testing
Historically, frameworks such as Spring and Grails were not designed to run in scenarios such as server-less functions, Android apps, or low memory-footprint microservices. In contrast, Micronaut is designed to be suitable for all of these scenarios.
This goal is achieved through the use of Java’s annotation processors, which are usable on any JVM language that supports them, as well as an HTTP Server and Client built on Netty. In order to provide a similar programming model to Spring and Grails, these annotation processors precompile the necessary metadata in order to perform DI, define AOP proxies and configure your application to run in a microservices environment.
Many of the APIs within Micronaut are heavily inspired by Spring and Grails. This is by design, and aids in bringing developers up to speed quickly.
1.1 What's New?
Apart from issues resolved and minor enhancements since the last release of Micronaut, this section covers significant new features.
Improvements from RC3 to GA
GraalVM support has been updated to use Docker instead of a ./build-native-image script allowing usage of other platforms.
The official GraalVM Docker images are used, so to build a native image you can simply execute docker build . -t myimage in the root of your project.
Support for GraalVM Native Images
Micronaut now includes experimental support for compiling down to GraalVM native images using the nativeimage tool shipped as part of Graal (1.0.0 RC6 and above).
This is possible due to to Micronaut’s reflection-free approach to Dependency Injection and AOP.
See the section on GraalVM support in the user guide for more information.
Swagger / OpenAPI Documentation Support
Micronaut now includes the ability to generate Swagger (OpenAPI) YAML at compile time using the language neutral visitor API and the interfaces defined by the io.micronaut.inject.ast package.
See the section on OpenAPI / Swagger Support in the user guide for more information.
Native WebSocket Support
Built-in support for WebSocket for both the client and the server has been added. The following example is a simple server chat implementation:
WebSocket Chat Example
See the section on WebSocket Support in the user guide for more information.
CLI Commands for WebSockets
The Micronaut CLI now includes two new commands for generating WebSocket clients and servers.
$ mn create-websocket-server MyChat
| Rendered template WebsocketServer.java to destination src/main/java/example/MyChatServer.java
$ mn create-websocket-client MyChat
| Rendered template WebsocketClient.java to destination src/main/java/example/MyChatClient.javaCompilation Time Validation
The validation module can now be added to the annotationProcessor classpath and which will result in additional compile time checks, ensuring that users are using the framework correctly. For example, the following route method:
@Get("/hello/{name}")
public Single<String> hello(@NotBlank String na) {
return Single.just("Hello " + na + "!");
}Will produce the following error at compile time:
hello-world-java/src/main/java/example/HelloController.java:34: error: The route declares a uri variable named [name], but no corresponding method argument is present
public Single<String> hello(@NotBlank String na) {
^This lessens the need for IDE support designed specifically for Micronaut.
Experimental JMX Support for Endpoints
Experimental support for exposing management endpoints over JMX has been added via the jmx module. See the section on JMX Support for more information on how to use this feaure.
Multitenancy support
Latest release includes Multitenancy integration into the framework. Features includes tenant resolution, propagation and integration with GORM which supports discriminator, table and schema multitenancy modes.
Token Propagation
Latest release includes Token Propagation capabilities into the security module of the the framework. It enables the propagation of valid tokens to outgoing requests triggered by the original request in a transparent way.
Ldap Authentication
Latest release supports authentication with LDAP out of the box. Moreover, the LDAP authentication in Micronaut supports configuration of one or more LDAP servers to authenticate with.
Documentation Improvements
The documentation you are reading has been improved with a new configuration reference button at the top that contains a reference produced at compile time of all the available configuration options in Micronaut.
Dependency Upgrades
The following dependency upgrades occurred in this release:
-
Netty
4.1.29→4.1.30 -
RxJava
2.2.0→2.2.2 -
Hibernate Core
5.3.4→5.3.6.Final -
Jackson
2.9.6→2.9.7 -
Reactor
3.1.8→3.2.0 -
SnakeYAML
1.20→1.23 -
Jaeger
0.30.4→0.31.0 -
Brave '5.2.0` →
5.4.2 -
Zipkin Reporter
2.7.7→2.7.9 -
Spring
5.0.8→5.1.0
Amazon Route 53 Service Discovery and AWS Systems Manager Parameter Store Support
Use Amazon Route 53 Service Discovery directly for service discovery instead of running an instance of tools like Consul. You can also use AWS Systems Manager Parameter Store for shared configuration between nodes.
2 Quick Start
The following sections will walk you through a Quick start on how to use Micronaut to setup a basic "Hello World" application.
Before getting started ensure you have a Java 8 or above SDK installed and it is recommended having a suitable IDE such as IntelliJ IDEA.
To follow the Quick Start it is also recommended that you have the Micronaut CLI installed.
2.1 Build/Install the CLI
The best way to install Micronaut on Unix systems is with SDKMAN which greatly simplifies installing and managing multiple Micronaut versions.
2.1.1 Install with Sdkman
Before updating make sure you have latest version of SDKMAN installed. If not, run
$ sdk updateIn order to install Micronaut, run following command:
$ sdk install micronautYou can also specify the version to the sdk install command.
$ sdk install micronaut 1.0.0You can find more information about SDKMAN usage on the SDKMAN Docs
You should now be able to run the Micronaut CLI.
$ mn
| Starting interactive mode...
| Enter a command name to run. Use TAB for completion:
mn>2.1.2 Install through Binary on Windows
-
Download the latest binary from Micronaut Website
-
Extract the binary to appropriate location (For example:
C:/micronaut) -
Create an environment variable
MICRONAUT_HOMEwhich points to the installation directory i.e.C:/micronaut -
Update the
PATHenvironment variable, append%MICRONAUT_HOME%\bin.
You should now be able to run the Micronaut CLI from the command prompt as follows:
$ mn
| Starting interactive mode...
| Enter a command name to run. Use TAB for completion:
mn>2.1.3 Building from Source
Clone the repository:
$ git clone https://github.com/micronaut-projects/micronaut-core.gitcd into the micronaut-core directory and run the following command:
$ ./gradlew cli:fatJarThis will create the farJar for CLI.
In your shell profile (~/.bash_profile if you are using the Bash shell), export the MICRONAUT_HOME directory and add the CLI path to your PATH:
bash_profile/.bashrc
export MICRONAUT_HOME=~/path/to/micronaut-core
export PATH="$PATH:$MICRONAUT_HOME/cli/build/bin"Reload your terminal or source your shell profile with source:
> source ~/.bash_profileYou should now be able to run the Micronaut CLI.
$ mn
| Starting interactive mode...
| Enter a command name to run. Use TAB for completion:
mn>
You can also point SDKMAN to local installation for dev purpose using following command sdk install micronaut dev /path/to/checkout/cli/build
|
2.2 Creating a Server Application
Although not required to use Micronaut, the Micronaut CLI is the quickest way to create a new server application.
Using the CLI you can create a new Micronaut application in either Groovy, Java or Kotlin (the default is Java).
The following command creates a new "Hello World" server application in Java with a Gradle build:
$ mn create-app hello-world
You can supply --build maven if you wish to create a Maven based build instead
|
The previous command will create a new Java application in a directory called hello-world featuring a Gradle a build. The application can be run with ./gradlew run:
$ ./gradlew run
> Task :run
[main] INFO io.micronaut.runtime.Micronaut - Startup completed in 972ms. Server Running: http://localhost:28933By default the Micronaut HTTP server is configured to run on port 8080.
See the section Running Server on a Specific Port in the user guide for more options.
In order to create a service that responds to "Hello World" you first need a controller. The following is an example of a controller written in Java and located in src/main/java/example/helloworld:
src/main/java/example/helloworld/HelloController.java
import io.micronaut.http.MediaType;
import io.micronaut.http.annotation.*;
@Controller("/hello") (1)
public class HelloController {
@Get(produces = MediaType.TEXT_PLAIN) (2)
public String index() {
return "Hello World"; (3)
}
}| 1 | The class is defined as a controller with the @Controller annotation mapped to the path /hello |
| 2 | The @Get annotation is used to map the index method to all requests that use an HTTP GET |
| 3 | A String "Hello World" is returned as the result |
If you start the application and send a request to the /hello URI then the text "Hello World" is returned:
$ curl http://localhost:8080/hello
Hello World2.3 Setting up an IDE
The application created in the previous section contains a "main class" located in src/main/java that looks like the following:
package hello.world;
import io.micronaut.runtime.Micronaut;
public class Application {
public static void main(String[] args) {
Micronaut.run(Application.class);
}
}This is the class that is run when running the application via Gradle or via deployment. You can also run the main class directly within your IDE if it is configured correctly.
Configuring IntelliJ IDEA
To import a Micronaut project into IntelliJ IDEA simply open the build.gradle or pom.xml file and follow the instructions to import the project.
For IntelliJ IDEA if you plan to use the IntelliJ compiler then you should enable annotation processing under the "Build, Execution, Deployment → Compiler → Annotation Processors" by ticking the "Enable annotation processing" checkbox:
Once you have enabled annotation processing in IntelliJ you can run the application and tests directly within the IDE without the need of an external build tool such as Gradle or Maven.
Configuring Eclipse IDE
If you wish to use Eclipse IDE, it is recommended you import your Micronaut project into Eclipse using either Gradle BuildShip for Gradle or M2Eclipse for Maven.
As of this writing, the latest stable version of Eclipse has incomplete support for Java annotation processors, this has been resolved in Eclipse 4.9 M2 and above, which you will need to download.
Eclipse and Gradle
Once you have setup Eclipse 4.9 M2 or above with Gradle BuildShip first run the gradle eclipse task from the root of your project then import the project by selecting File → Import then choosing Gradle → Existing Gradle Project and navigating to the root directory of your project (where the build.gradle is located).
Eclipse and Maven
For Eclipse 4.9 M2 and above with Maven you need the following Eclipse plugins:
Once installed you need to import the project by selecting File → Import then choosing Maven → Existing Maven Project and navigating to the root directory of your project (where the pom.xml is located).
You should then enable annotation processing by opening Eclipse → Preferences and navigating to Maven → Annotation Processing and selecting the option Automatically configure JDT APT.
2.4 Creating a Client
As mentioned previously, Micronaut includes both an HTTP server and an HTTP client. A low-level HTTP client is provided out of the box which you can use to test the HelloController created in the previous section.
For example, the following test is written using Spock Framework:
Testing Hello World
import io.micronaut.context.ApplicationContext
import io.micronaut.http.HttpRequest
import io.micronaut.http.client.HttpClient
import io.micronaut.runtime.server.EmbeddedServer
import spock.lang.*
class HelloControllerSpec extends Specification {
@Shared @AutoCleanup EmbeddedServer embeddedServer =
ApplicationContext.run(EmbeddedServer) (1)
@Shared @AutoCleanup HttpClient client = HttpClient.create(embeddedServer.URL) (2)
void "test hello world response"() {
expect:
client.toBlocking() (3)
.retrieve(HttpRequest.GET('/hello')) == "Hello World" (4)
}
}| 1 | The EmbeddedServer is configured as a shared and automatically cleaned up test field |
| 2 | A HttpClient instance shared field is also defined |
| 3 | The test using the toBlocking() method to make a blocking call |
| 4 | The retrieve method returns the response of the controller as a String |
In addition to a low-level client, Micronaut features a declarative, compile-time HTTP client, powered by the Client annotation.
To create a client, simply create an interface annotated with @Client. For example:
src/main/java/hello/world/HelloClient.java
import io.micronaut.http.annotation.Get;
import io.micronaut.http.client.annotation.Client;
import io.reactivex.Single;
@Client("/hello") (1)
public interface HelloClient {
@Get (2)
Single<String> hello(); (3)
}| 1 | The @Client annotation is used with value that is a relative path to the current server |
| 2 | The same @Get annotation used on the server is used to define the client mapping |
| 3 | A RxJava Single is returned with the value read from the server |
To test the HelloClient simply retrieve it from the ApplicationContext associated with the server:
Testing HelloClient
import io.micronaut.runtime.server.EmbeddedServer
import spock.lang.*
class HelloClientSpec extends Specification {
@Shared @AutoCleanup EmbeddedServer embeddedServer =
ApplicationContext.run(EmbeddedServer) (1)
@Shared HelloClient client = embeddedServer
.applicationContext
.getBean(HelloClient) (2)
void "test hello world response"() {
expect:
client.hello().blockingGet() == "Hello World" (3)
}
}| 1 | The EmbeddedServer is run |
| 2 | The HelloClient is retrieved from the ApplicationContext |
| 3 | The client is invoked using RxJava’s blockingGet method |
The Client annotation produces an implementation automatically for you at compile time without the need to use proxies or runtime reflection.
The Client annotation is very flexible. See the section on the Micronaut HTTP Client for more information.
2.5 Deploying the Application
To deploy a Micronaut application you create a runnable JAR file by running ./gradlew assemble or ./mvnw package.
The constructed JAR file can then be executed with java -jar. For example:
$ java -jar build/libs/hello-world-all.jarThe runnable JAR can also easily be packaged within a Docker container or deployed to any Cloud infrastructure that supports runnable JAR files.
3 Inversion of Control
When most developers think of Inversion of Control (also known as Dependency Injection and referred to as such from this point onwards) the Spring Framework comes to mind.
Micronaut takes heavy inspiration from Spring, and in fact, the core developers of Micronaut are former SpringSource/Pivotal engineers now working for OCI.
Unlike Spring which relies exclusively on runtime reflection and proxies, Micronaut, on the other hand, uses compile time data to implement dependency injection.
This is a similar approach taken by tools such as Google’s Dagger, which is designed primarily with Android in mind. Micronaut, on the other hand, is designed for building server-side microservices and provides many of the same tools and utilities as Spring does but without using reflection or caching excessive amounts of reflection metadata.
The goals of the Micronaut IoC container are summarized as:
-
Use reflection as a last resort
-
Avoid proxies
-
Optimize start-up time
-
Reduce memory footprint
-
Provide clear, understandable error handling
Note that the IoC part of Micronaut can be used completely independently of Micronaut itself for whatever application type you may wish to build. To do so all you need to do is configure your build appropriately to include the micronaut-inject-java dependency as an annotation processor. For example with Gradle:
Configuring Gradle
plugins {
id "net.ltgt.apt" version "0.18" // <1>
}
...
dependencies {
annotationProcessor "io.micronaut:micronaut-inject-java:1.0.0" // <2>
compile "io.micronaut:micronaut-inject:1.0.0"
...
}| 1 | Apply the Annotation Processing plugin |
| 2 | Include the minimal dependencies required to perform dependency injection |
For the Groovy language you should include micronaut-inject-groovy in the compileOnly scope.
|
The entry point for IoC is then the ApplicationContext interface, which includes a run method. The following example demonstrates using it:
Running the
ApplicationContexttry (ApplicationContext context = ApplicationContext.run()) { (1)
MyBean myBean = context.getBean(MyBean.class); (2)
// do something with your bean
}| 1 | Run the ApplicationContext |
| 2 | Retrieve a bean that has been dependency injected |
| The example uses Java’s try-with-resources syntax to ensure the ApplicationContext is cleanly shutdown when the application exits. |
3.1 Defining Beans
Micronaut implements the JSR-330 (javax.inject) - Dependency Injection for Java specification hence to use Micronaut you simply use the annotations provided by javax.inject.
The following is a simple example:
import javax.inject.*
interface Engine { (1)
int getCylinders()
String start()
}
@Singleton (2)
class V8Engine implements Engine {
int cylinders = 8
String start() {
"Starting V8"
}
}
@Singleton
class Vehicle {
final Engine engine
Vehicle(Engine engine) { (3)
this.engine = engine
}
String start() {
engine.start()
}
}| 1 | A common Engine interface is defined |
| 2 | A V8Engine implementation is defined and marked with Singleton scope |
| 3 | The Engine is injected via constructor injection |
To perform dependency injection simply run the BeanContext using the run() method and lookup a bean using getBean(Class), as per the following example:
import io.micronaut.context.*
...
Vehicle vehicle = BeanContext.run()
.getBean(Vehicle)
println( vehicle.start() )Micronaut will automatically discover dependency injection metadata on the classpath and wire the beans together according to injection points you define.
Micronaut supports the following types of dependency injection:
-
Constructor injection (must be one public constructor or a single contructor annotated with
@Inject) -
Field injection
-
JavaBean property injection
-
Method parameter injection
3.2 How Does it Work?
At this point, you may be wondering how Micronaut performs the above dependency injection without requiring reflection.
The key is a set of AST transformations (for Groovy) and annotation processors (for Java) that generate classes that implement the BeanDefinition interface.
The ASM byte-code library is used to generate classes and because Micronaut knows ahead of time the injection points, there is no need to scan all of the methods, fields, constructors, etc. at runtime like other frameworks such as Spring do.
Also since reflection is not used in the construction of the bean, the JVM can inline and optimize the code far better resulting in better runtime performance and reduced memory consumption. This is particularly important for non-singleton scopes where the application performance depends on bean creation performance.
In addition, with Micronaut your application startup time and memory consumption is not bound to the size of your codebase in the same way as a framework that uses reflection. Reflection based IoC frameworks load and cache reflection data for every single field, method, and constructor in your code. Thus as your code grows in size so do your memory requirements, whilst with Micronaut this is not the case.
3.3 The BeanContext
The BeanContext is a container object for all your bean definitions (it also implements BeanDefinitionRegistry).
It is also the point of initialization for Micronaut. Generally speaking however, you don’t have to interact directly with the BeanContext API and can simply use javax.inject annotations and the annotations defined within io.micronaut.context.annotation package for your dependency injection needs.
3.4 Injectable Container Types
In addition to being able to inject beans Micronaut natively supports injecting the following types:
| Type | Description | Example |
|---|---|---|
An |
|
|
An |
|
|
A lazy |
|
|
A native array of beans of a given type |
|
|
A |
|
3.5 Bean Qualifiers
If you have multiple possible implementations for a given interface that you want to inject, you need to use a qualifier.
Once again Micronaut leverages JSR-330 and the Qualifier and Named annotations to support this use case.
Qualifying By Name
To qualify by name you can use the Named annotation. For example, consider the following classes:
import javax.inject.*
interface Engine { (1)
int getCylinders()
String start()
}
@Singleton
class V6Engine implements Engine { (2)
int cylinders = 6
String start() {
"Starting V6"
}
}
@Singleton
class V8Engine implements Engine { (3)
int cylinders = 8
String start() {
"Starting V8"
}
}
@Singleton
class Vehicle {
final Engine engine
@Inject Vehicle(@Named('v8') Engine engine) { (4)
this.engine = engine
}
String start() {
engine.start() (5)
}
}| 1 | The Engine interface defines the common contract |
| 2 | The V6Engine class is the first implementation |
| 3 | The V8Engine class is the second implementation |
| 4 | The Named annotation is used to indicate the V8Engine implementation is required |
| 5 | Calling the start method prints: "Starting V8" |
You can also declare @Named at the class level of a bean to explicitly define the name of the bean.
Qualifying By Annotation
In addition to being able to qualify by name, you can build your own qualifiers using the Qualifier annotation. For example, consider the following annotation:
import javax.inject.Qualifier
import java.lang.annotation.Retention
import static java.lang.annotation.RetentionPolicy.RUNTIME
@Qualifier
@Retention(RUNTIME)
@interface V8 {
}The above annotation is itself annotated with the @Qualifier annotation to designate it as a qualifier. You can then use the annotation at any injection point in your code. For example:
@Inject Vehicle(@V8 Engine engine) {
this.engine = engine
}Primary and Secondary Beans
Primary is a qualifier that indicates that a bean is the primary bean that should be selected in the case of multiple possible interface implementations.
Consider the following example:
public interface ColorPicker {
String color()
}Given a common interface called ColorPicker that is implemented by multiple classes.
The Primary Bean
import io.micronaut.context.annotation.Primary;
import io.micronaut.context.annotation.Requires;
import javax.inject.Singleton;
@Primary
@Singleton
public class Green implements ColorPicker {
@Override
public String color() {
return "green";
}
}The Green bean is a ColorPicker, but is annotated with @Primary.
Another Bean of the Same Type
import io.micronaut.context.annotation.Requires;
import javax.inject.Singleton;
@Singleton
public class Blue implements ColorPicker {
@Override
public String color() {
return "blue";
}
}The Blue bean is also a ColorPicker and hence you have two possible candidates when injecting the ColorPicker interface. Since Green is the primary it will always be favoured.
@Controller("/test")
public class TestController {
protected final ColorPicker colorPicker;
public TestController(ColorPicker colorPicker) { (1)
this.colorPicker = colorPicker;
}
@Get
public String index() {
return colorPicker.color();
}
}| 1 | Although there are two ColorPicker beans, Green gets injected due to the @Primary annotation. |
If multiple possible candidates are present and no @Primary is defined then a NonUniqueBeanException will be thrown.
In addition to @Primary, there is also a Secondary annotation which causes the opposite effect and allows de-prioritizing a bean.
3.6 Scopes
Micronaut features an extensible bean scoping mechanism based on JSR-303. The following default scopes are supported:
3.6.1 Built-In Scopes
| Type | Description |
|---|---|
Singleton scope indicates only one instance of the bean should exist |
|
Context scope indicates that the bean should be created at the same time as the |
|
Prototype scope indicates that a new instance of the bean is created each time it is injected |
|
Infrastructure is a |
|
|
|
|
Additional scopes can be added by defining a @Singleton bean that implements the CustomScope interface.
Note that with Micronaut when starting a ApplicationContext by default @Singleton scoped beans are created lazily and on demand. This is by design and to optimize startup time.
If this is presents are problem for your use case you have the option of using the @Context annotation which binds the lifecycle of your object to the lifecycle of the ApplicationContext. In other words when the ApplicationContext is started your bean will be created.
Alternatively you can annotate any @Singleton scoped bean with @Parallel which allows parallel initialization of your bean without impacting overall startup time.
| If your bean fails to initialize in parallel then the application will be automatically shutdown. |
3.6.2 Refreshable Scope
The Refreshable scope is a custom scope that allows a bean’s state to be refreshed via:
-
/refreshendpoint. -
Publication of a RefreshEvent.
The following example, illustrates the @Refreshable scope behavior.
@Refreshable (1)
static class WeatherService {
String forecast
@PostConstruct
void init() {
forecast = "Scattered Clouds ${new Date().format('dd/MMM/yy HH:ss.SSS')}" (2)
}
String latestForecast() {
return forecast
}
}| 1 | The WeatherService is annotated with @Refreshable scope which stores an instance until a refresh event is triggered |
| 2 | The value of the forecast property is set to a fixed value when the bean is created and won’t change until the bean is refreshed |
If you invoke the latestForecast() twice, you will see identical responses such as "Scattered Clouds 01/Feb/18 10:29.199".
When the /refresh endpoint is invoked or a RefreshEvent is published then the instance is invalidated and a new instance is created the next time the object is requested. For example:
applicationContext.publishEvent(new RefreshEvent())3.6.3 Scopes on Meta Annotations
Scopes can be defined on Meta annotations that you can then apply to your classes. Consider the following example meta annotation:
Driver.java Annotation
import static java.lang.annotation.RetentionPolicy.RUNTIME;
import io.micronaut.context.annotation.Requires;
import javax.inject.Singleton;
import java.lang.annotation.Documented;
import java.lang.annotation.Retention;
@Requires(classes = Car.class ) (1)
@Singleton (2)
@Documented
@Retention(RUNTIME)
public @interface Driver {
}| 1 | The scope declares a requirement on a Car class using Requires |
| 2 | The annotation is declared as @Singleton |
In the example above the @Singleton annotation is applied to the @Driver annotation which results in every class that is annotated with @Driver being regarded as singleton.
Note that in this case it is not possible to alter the scope when the annotation is applied. For example, the following will not override the scope declared by @Driver and is invalid:
Declaring Another Scope
@Driver
@Prototype
class Foo {}If you wish for the scope to be overridable you should instead using the DefaultScope annotation on @Driver which allows a default scope to be specified if none other is present:
Using @DefaultScope
@Requires(classes = Car.class )
@DefaultScope(Singleton.class) (1)
@Documented
@Retention(RUNTIME)
public @interface Driver {
}| 1 | DefaultScope is used to declare which scope to be used if non is present |
3.7 Bean Factories
In many cases, you may want to make available as a bean a class that is not part of your codebase such as those provided by third-party libraries. In this case, you cannot annotate the already compiled class. Instead, you should implement a Factory.
A factory is a class annotated with the Factory annotation that provides 1 or more methods annotated with the Bean annotation.
The return types of methods annotated with @Bean are the bean types. This is best illustrated by an example:
import io.micronaut.context.annotation.*
import javax.inject.*
@Singleton
class CrankShaft {
}
class V8Engine implements Engine {
final int cylinders = 8
final CrankShaft crankShaft
V8Engine(CrankShaft crankShaft) {
this.crankShaft = crankShaft
}
String start() {
"Starting V8"
}
}
@Factory
class EngineFactory {
@Bean
@Singleton
Engine v8Engine(CrankShaft crankShaft) {
new V8Engine(crankShaft)
}
}In this case, the V8Engine is built by the EngineFactory class' v8Engine method. Note that you can inject parameters into the method and these parameters will be resolved as beans.
A factory can also have multiple methods annotated with @Bean each one returning a distinct bean type.
If you take this approach, then you should not invoke other methods annotated with @Bean internally within the class. Instead, inject the types via parameters.
|
3.8 Conditional Beans
At times you may want a bean to load conditionally based on various potential factors including the classpath, the configuration, the presence of other beans etc.
The Requires annotation provides the ability to define one or many conditions on a bean.
Consider the following example:
Using @Requires
@Singleton
@Requires(beans = DataSource.class)
@Requires(property = "datasource.url")
public class JdbcBookService implements BookService {
DataSource dataSource;
public JdbcBookService(DataSource dataSource) {
this.dataSource = dataSource;
}
}The above bean defines two requirements. The first indicates that a DataSource bean must be present for the bean to load. The second requirement ensures that the datasource.url property is set before loading the JdbcBookService bean.
Kotlin currently does not support repeatable annotations. Use the @Requirements annotation when multiple requires are needed. For example, @Requirements(Requires(…), Requires(…)). See https://youtrack.jetbrains.com/issue/KT-12794 to track this feature.
|
If you have multiple requirements that you find you may need to repeat on multiple beans then you can define a meta-annotation with the requirements:
Using a @Requires meta-annotation
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.PACKAGE, ElementType.TYPE})
@Requires(beans = DataSource.class)
@Requires(property = "datasource.url")
public @interface RequiresJdbc {
}In the above example an annotation called RequiresJdbc is defined that can then be used on the JdbcBookService instead:
Using a @Requires meta-annotation
@RequiresJdbc
public class JdbcBookService implements BookService {
...
}If you have multiple beans that need to fulfill a given requirement before loading then you may want to consider a bean configuration group, as explained in the next section.
Configuration Requirements
The @Requires annotation is very flexible and can be used for a variety of use cases. The following table summarizes some of the possibilities:
| Requirement | Example |
|---|---|
Require the presence of one ore more classes |
|
Require the absence of one ore more classes |
|
Require the presence one or more beans |
|
Require the absence of one or more beans |
|
Require the environment to be applied |
|
Require the environment to not be applied |
|
Require the presence of another configuration package |
|
Require the absence of another configuration package |
|
Require particular SDK version |
|
Requires classes annotated with the given annotations to be available to the application via package scanning |
|
Require a property with an optional value |
|
Require a property to not be part of the configuration |
|
Additional Notes on Property Requirements.
Adding a requirement on a property has some additional functionality. You can require the property to be a certain value, not be a certain value, and use a default in those checks if its not set.
@Requires(property="foo") (1)
@Requires(property="foo", value="John") (2)
@Requires(property="foo", value="John", defaultValue="John") (3)
@Requires(property="foo", notEquals="Sally") (4)| 1 | Requires the property to be "yes", "YES", "true", "TRUE", "y" or "Y" |
| 2 | Requires the property to be "John" |
| 3 | Requires the property to be "John" or not set |
| 4 | Requires the property to not be "Sally" or not set |
Debugging Conditional Beans
If you have multiple conditions and complex requirements it may become difficult to understand why a particular bean has not been loaded.
To help resolve issues with conditional beans you can enable debug logging for the io.micronaut.context.condition package which will log the reasons why beans were not loaded.
logback.xml
<logger name="io.micronaut.context.condition" level="DEBUG"/>3.9 Bean Replacement
One significant difference between Micronaut’s Dependency Injection system and Spring is the way beans can be replaced.
In a Spring application, beans have names and can effectively be overridden simply by creating a bean with the same name, regardless of the type of the bean. Spring also has the notion of bean registration order, hence in Spring Boot you have @AutoConfigureBefore and @AutoConfigureAfter the control how beans override each other.
This strategy leads to difficult to debug problems, for example:
-
Bean loading order changes, leading to unexpected results
-
A bean with the same name overrides another bean with a different type
To avoid these problems, Micronaut’s DI has no concept of bean names or load order. Beans have a type and a Qualifier. You cannot override a bean of a completely different type with another.
A useful benefit of Spring’s approach is that it allows overriding existing beans to customize behaviour. In order to support the same ability, Micronaut’s DI provides an explicit @Replaces annotation, which integrates nicely with support for Conditional Beans and clearly documents and expresses the intention of the developer.
Any existing bean can be replaced by another bean that declares @Replaces. For example, consider the following class:
JdbcBookService.java
@Singleton
@Requires(beans = DataSource.class)
public class JdbcBookService implements BookService {
DataSource dataSource;
public JdbcBookService(DataSource dataSource) {
this.dataSource = dataSource;
}
}You can define a class in src/test/java that replaces this class just for your tests:
Using @Replaces
@Replaces(JdbcBookService.class) (1)
@Singleton
public class MockBookService implements BookService {
Map<String, Book> bookMap = new LinkedHashMap<>();
@Override
public Book findBook(String title) {
return bookMap.get(title);
}
}| 1 | The MockBookService declares that it replaces JdbcBookService |
The @Replaces annotation also supports a factory argument. That argument allows the replacement of factory beans in their entirety or specific types created by the factory.
For example, it may be desired to replace all or part of the given factory class:
BookFactory.java
@Factory
public class BookFactory {
@Singleton
Book novel() {
return new Book("A Great Novel");
}
@Singleton
TextBook textBook() {
return new TextBook("Learning 101");
}
}| To replace a factory in its entirety, it is necessary that your factory methods match the return types of all of the methods in the replaced factory. |
In this example, the BookFactory#textBook() will not be replaced because this factory does not have a factory method that returns a TextBook.
CustomBookFactory.java
@Factory
@Replaces(factory = BookFactory.class)
public class CustomBookFactory {
@Singleton
Book otherNovel() {
return new Book("An OK Novel");
}
}It may be the case that you don’t wish for the factory methods to be replaced, except for a select few. For that use case, you can apply the @Replaces annotation on the method and denote the factory that it should apply to.
TextBookFactory.java
@Factory
public class TextBookFactory {
@Singleton
@Replaces(value = TextBook.class, factory = BookFactory.class)
TextBook textBook() {
return new TextBook("Learning 305");
}
}The BookFactory#novel() method will not be replaced because the TextBook class is defined in the annotation.
3.10 Bean Configurations
A bean @Configuration is a grouping of multiple bean definitions within a package.
The @Configuration annotation is applied at the package level and informs Micronaut that the beans defined with the package form a logical grouping.
The @Configuration annotation is typically applied to package-info class. For example:
package-info.groovy
@Configuration
package my.package
import io.micronaut.context.annotation.ConfigurationWhere this grouping becomes useful is when the bean configuration is made conditional via the @Requires annotation. For example:
package-info.groovy
@Configuration
@Requires(beans = javax.sql.DataSource)
package my.packageIn the above example, all bean definitions within the annotated package will only be loaded and made available if a javax.sql.DataSource bean is present. This allows you to implement conditional auto-configuration of bean definitions.
3.11 Life-Cycle Methods
If you wish for a particular method to be invoked when a bean is constructed then you can use the javax.annotation.PostConstruct annotation:
import javax.annotation.PostConstruct (1)
import javax.inject.Singleton
@Singleton
class V8Engine implements Engine {
int cylinders = 8
boolean initialized = false (2)
String start() {
if(!initialized) throw new IllegalStateException("Engine not initialized!")
return "Starting V8"
}
@PostConstruct (3)
void initialize() {
this.initialized = true
}
}| 1 | The PostConstruct annotation is imported |
| 2 | A field is defined that requires initialization |
| 3 | A method is annotated with @PostConstruct and will be invoked once the object is constructed and fully injected. |
3.12 Context Events
Micronaut supports a general event system through the context. The ApplicationEventPublisher API is used to publish events and the ApplicationEventListener API is used to listen to events. The event system is not limited to the events that Micronaut publishes and can be used for custom events created by the users.
Publishing Events
The ApplicationEventPublisher API supports events of any type, however all events that Micronaut publishes extend ApplicationEvent.
To publish an event, obtain an instance of ApplicationEventPublisher either directly from the context or through dependency injection, and execute the publishEvent method with your event object.
@Singleton
public class MyBean {
@Inject ApplicationEventPublisher eventPublisher;
void doSomething() {
eventPublisher.publishEvent(...);
}
}
Publishing an event is synchronous by default! The publishEvent method will not return until all listeners have been executed. Move this work off to a thread pool if it is time intensive.
|
Listening for Events
To listen to an event, register a bean that implements ApplicationEventListener where the generic type is the type of event the listener should be executed for.
Listening for Events with
ApplicationEventListener@Singleton
public class DoOnStartup implements ApplicationEventListener<ServiceStartedEvent> {
@Override
void onApplicationEvent(ServiceStartedEvent event) {
...
}
}| The supports method can be overridden to further clarify events that should be processed. |
Alternatively you can use the @EventListener annotation if you do not wish to specifically implement an interface:
Listening for Events with
@EventListenerimport io.micronaut.runtime.event.annotation.EventListener;
...
@Singleton
public class DoOnStartup {
@EventListener
void onStartup(ServiceStartedEvent event) {
...
}
}If your listener performs work that could take a while then you can use the @Async annotation to run the operation on a separate thread:
Asynchronously listening for Events with
@EventListenerimport io.micronaut.runtime.event.annotation.EventListener;
import io.micronaut.scheduling.annotation.Async;
...
@Singleton
public class DoOnStartup {
@EventListener
@Async
void onStartup(ServiceStartedEvent event) {
...
}
}The event listener will by default run on the scheduled executor. You can configure this thread pool as required in application.yml:
Configuring Scheduled Task Thread Pool
micronaut:
executors:
scheduled:
type: scheduled
core-pool-size: 303.13 Bean Events
You can hook into the creation of beans using one of the following interfaces:
-
BeanInitializedEventListener - allows modifying or replacing of a bean after the properties have been set but prior to
@PostConstructevent hooks. -
BeanCreatedEventListener - allows modifying or replacing of a bean after the bean is fully initialized and all
@PostConstructhooks called.
The BeanInitializedEventListener interface is commonly used in combination with Factory beans. Consider the following example:
import javax.inject.*
class V8Engine implements Engine {
final int cylinders = 8
double rodLength (1)
String start() {
return "Starting V${cylinders} [rodLength=$rodLength]"
}
}
@Factory
class EngineFactory {
private V8Engine engine
double rodLength = 5.7
@PostConstruct
void initialize() {
engine = new V8Engine(rodLength: rodLength) (2)
}
@Bean
@Singleton
Engine v8Engine() {
return engine (3)
}
}
@Singleton
class EngineInitializer implements BeanInitializedEventListener<EngineFactory> { (4)
@Override
EngineFactory onInitialized(BeanInitializingEvent<EngineFactory> event) {
EngineFactory engineFactory = event.bean
engineFactory.rodLength = 6.6 (5)
return event.bean
}
}| 1 | The V8Engine class defines a rodLength property |
| 2 | The EngineFactory initializes the value of rodLength and creates the instance |
| 3 | The created instance is returned as a Bean |
| 4 | The BeanInitializedEventListener interface is implemented to listen for the initialization of the factory |
| 5 | Within the onInitialized method the rodLength is overridden prior to the engine being created by the factory bean. |
The BeanCreatedEventListener interface is more typically used to decorate or enhance a fully initialized bean by creating a proxy for example.
3.14 Bean Annotation Metadata
The methods provided by Java’s AnnotatedElement API in general don’t provide the ability to introspect annotations without loading the annotations themselves, nor do they provide any ability to introspect annotation stereotypes (Often called meta-annotations, an annotation stereotype is where an annotation is annotated with another annotation, essentially inheriting its behaviour).
To solve this problem many frameworks produce runtime metadata or perform expensive reflection to analyze the annotations of a class.
Micronaut instead produces this annotation metadata at compile time, avoiding expensive reflection and saving on memory.
The BeanContext API can be used to obtain a reference to a BeanDefinition which implements the AnnotationMetadata interface.
For example the following code will obtain all bean definitions annotated with a particular stereotype:
Lookup Bean Definitions by Stereotype
BeanContext beanContext = ... // obtain the bean context
Collection<BeanDefinition> definitions =
beanContext.getBeanDefinitions(Qualifiers.byStereotype(Controller.class))
for(BeanDefinition definition : definitions) {
AnnotationValue<Controller> controllerAnn = definition.getAnnotation(Controller.class);
// do something with the annotation
}The above example will find all BeanDefinition annotated with @Controller regardless whether @Controller is used directly or inherited via an annotation stereotype.
Note that the getAnnotation method and the variations of the method return a AnnotationValue type and not a Java annotation. This is by design, and you should generally try to work with this API when reading annotation values, the reason being that synthesizing a proxy implementation is worse from a performance and memory consumption perspective.
If you absolutely require a reference to an annotation instance you can use the synthesize method, which will create a runtime proxy that implements the annotation interface:
Synthesizing Annotation Instances
Controller controllerAnn = definition.synthesize(Controller.class);This approach is not recommended however, as it requires reflection and increases memory consumption due to the use of runtime created proxies and should be used as a last resort (for example if you need to an instance of the annotation to integrate with a third party library).
Aliasing / Mapping Annotations
There are times when you may want to alias the value one of annotation member to the value of annotation annotation member. To do this you can use the @AliasFor annotation to alias the value of one member to the value of another.
A common use case is for example when an annotation defines value() member, but also supports other members. For example the @Client annotation:
The @Client Annotation
public @interface Client {
/**
* @return The URL or service ID of the remote service
*/
@AliasFor(member = "id") (1)
String value() default "";
/**
* @return The ID of the client
*/
@AliasFor(member = "value") (2)
String id() default "";
}| 1 | The value member also sets the id member |
| 2 | The id member also sets the value member |
With these aliases in place, regardless whether you define @Client("foo") or @Client(id="foo") both the value and id members are always set, making it much easier to parse and deal with the annotation.
If you do not have control over the annotation then another approach is to use a AnnotationMapper. To create a AnnotationMapper you must following the following steps:
-
Implement the AnnotationMapper interface
-
Define a
META-INF/services/io.micronaut.inject.annotation.AnnotationMapperfile referencing the implementation class -
Add the JAR file containing the implementation to the
annotationProcessorclasspath (kaptfor Kotlin)
Because AnnotationMapper implementations need to be on the annotation processor classpath they should generally be in a project that includes few external dependencies to avoid polluting the annotation processor classpath.
|
As an example the the AnnotationMapper that maps the javax.annotation.security.PermitAll standard Java annotation to the internal Micronaut Secured annotation looks like the following:
PermitAllAnnotationMapper Mapper Example
@Internal
public class PermitAllAnnotationMapper implements TypedAnnotationMapper<PermitAll> { (1)
@Override
public Class<PermitAll> annotationType() {
return PermitAll.class;
}
@Override
public List<AnnotationValue<?>> map(AnnotationValue<PermitAll> annotation, VisitorContext visitorContext) { (2)
List<AnnotationValue<?>> annotationValues = new ArrayList<>(1);
annotationValues.add(
AnnotationValue.builder(Secured.class) (3)
.value(SecurityRule.IS_ANONYMOUS) (4)
.build()
);
return annotationValues;
}
}| 1 | The annotation type to be mapped is specified as a generic type argument. |
| 2 | The map method receives a AnnotationValue with the values for the annotation. |
| 3 | One or more annotations can be returned, in this case @Secured. |
| 4 | Annotations values can be provided. |
| The example above implements the TypedAnnotationMapper interface which requires the annotation class itself to be on the annotation processor classpath. If that is undesirable (such as for projects that mix annotations with runtime code) then you should use NamedAnnotationMapper instead. |
3.15 Micronaut Beans And Spring
The MicronautBeanProcessor
class is a BeanFactoryPostProcessor which will add Micronaut beans to a
Spring Application Context. An instance of MicronautBeanProcessor should
be added to the Spring Application Context. MicronautBeanProcessor requires
a constructor parameter which represents a list of the types of
Micronaut beans which should be added the Spring Application Context. The
processor may be used in any Spring application. As an example, a Grails 3
application could take advantage of MicronautBeanProcessor to add all of the
Micronaut HTTP Client beans to the Spring Application Context with something
like the folowing:
// grails-app/conf/spring/resources.groovy
import io.micronaut.spring.beans.MicronautBeanProcessor
import io.micronaut.http.client.annotation.Client
beans = {
httpClientBeanProcessor MicronautBeanProcessor, Client
}Multiple types may be specified:
// grails-app/conf/spring/resources.groovy
import io.micronaut.spring.beans.MicronautBeanProcessor
import io.micronaut.http.client.annotation.Client
import com.sample.Widget
beans = {
httpClientBeanProcessor MicronautBeanProcessor, [Client, Widget]
}In a non-Grails application something similar may be specified using any of Spring’s bean definition styles:
@Configuration
class ByAnnotationTypeConfig {
@Bean
MicronautBeanProcessor beanProcessor() {
new MicronautBeanProcessor(Prototype, Singleton)
}
}3.16 Android Support
Since Micronaut dependency injection is based on annotation processors and doesn’t rely on reflection, it can be used on Android when using the Android plugin 3.0.0 or above.
This allows you to use the same application framework for both your Android client and server implementation.
Configuring Your Android Build
To get started you must add the Micronaut annotation processors to the processor classpath using the annotationProcessor dependency configuration.
The Micronaut micronaut-inject-java dependency should be included in both the annotationProcessor and compileOnly scopes of your Android build configuration:
Example Android build.gradle
dependencies {
...
annotationProcessor "io.micronaut:micronaut-inject-java:1.0.0"
compileOnly "io.micronaut:micronaut-inject-java:1.0.0"
...
}If you use lint as part of your build you may also need to disable the invalid packages check since Android includes a hard coded check that regards the javax.inject package as invalid unless you are using Dagger:
Configure lint within build.gradle
android {
...
lintOptions {
lintOptions { warning 'InvalidPackage' }
}
}You can find more information on configuring annotations processors in the Android documentation.
Micronaut inject-java dependency uses Android Java 8 support features.
|
Enabling Dependency Injection
Once you have configured the classpath correctly, the next step is start the ApplicationContext.
The following example demonstrates creating a subclass of android.app.Application for that purpose:
Example Android Application Class
import android.app.Activity;
import android.app.Application;
import android.os.Bundle;
import io.micronaut.context.ApplicationContext;
import io.micronaut.context.env.Environment;
public class BaseApplication extends Application { (1)
private ApplicationContext ctx;
public BaseApplication() {
super();
}
@Override
public void onCreate() {
super.onCreate();
ctx = ApplicationContext.run(MainActivity.class, Environment.ANDROID); (2)
registerActivityLifecycleCallbacks(new ActivityLifecycleCallbacks() { (3)
@Override
public void onActivityCreated(Activity activity, Bundle bundle) {
ctx.inject(activity);
}
... // shortened for brevity, it is not necessary to implement other methods
});
}
@Override
public void onTerminate() {
super.onTerminate();
if(ctx != null && ctx.isRunning()) { (4)
ctx.stop();
}
}
}| 1 | Extend the android.app.Application class |
| 2 | Run the ApplicationContext with the ANDROID environment |
| 3 | To allow dependency injection of Android Activity instances register a ActivityLifecycleCallbacks instance |
| 4 | Stop the ApplicationContext when the application terminates |
4 Application Configuration
Configuration in Micronaut takes inspiration from both Spring Boot and Grails, integrating configuration properties from multiple sources directly into the core IoC container.
Configuration can by default be provided in either Java properties, YAML, JSON or Groovy files. The convention is to search for a file called application.yml, application.properties, application.json or application.groovy.
In addition, just like Spring and Grails, Micronaut allows overriding any property via system properties or environment variables.
Each source of configuration is modeled with the PropertySource interface and the mechanism is extensible allowing the implementation of additional PropertySourceLoader implementations.
4.1 The Environment
The application environment is modelled by the Environment interface, which allows specifying one or many unique environment names when creating an ApplicationContext.
Initializing the Environment
ApplicationContext applicationContext = ApplicationContext.run("test", "android");
Environment environment = applicationContext.getEnvironment();
assertTrue(environment.getActiveNames().contains("test"));
assertTrue(environment.getActiveNames().contains("android"));The active environment names serve the purpose of allowing loading different configuration files depending on the environment and also using the @Requires annotation to conditionally load beans or bean @Configuration packages.
In addition, Micronaut will attempt to detect the current environments. For example within a Spock or JUnit test the TEST environment will be automatically active.
Additional active environments can be specified using the micronaut.environments system property or the MICRONAUT_ENVIRONMENTS environment variable. These can be specified as a comma separated list. For example:
Specifying environments
$ java -Dmicronaut.environments=foo,bar -jar myapp.jarThe above activates environments called foo and bar.
Finally, the Cloud environment names are also detected. See the section on Cloud Configuration for more information.
4.2 Externalized Configuration with PropertySources
Additional PropertySource instances can be added to the environment prior to initializing the ApplicationContext.
Initializing the Environment
ApplicationContext applicationContext = ApplicationContext.run(
PropertySource.of(
"test",
CollectionUtils.mapOf(
"micronaut.server.host", "foo",
"micronaut.server.port", 8080
)
),
"test", "android");
Environment environment = applicationContext.getEnvironment();
assertEquals(
environment.getProperty("micronaut.server.host", String.class).orElse("localhost"),
"foo"
);The PropertySource.of method can be used to create a ProperySource from a map of values.
Alternatively one can register a PropertySourceLoader by creating a META-INF/services/io.micronaut.context.env.PropertySourceLoader containing a reference to the class name of the PropertySourceLoader.
Included PropertySource Loaders
Micronaut by default contains PropertySourceLoader implementations that load properties from the given locations and priority:
-
Command line arguments
-
Properties from
SPRING_APPLICATION_JSON(for Spring compatibility) -
Properties from
MICRONAUT_APPLICATION_JSON -
Java System Properties
-
OS environment variables
-
Enviroment-specific properties from
application-{environment}.{extension}(Either.properties,.json,.ymlor.groovyproperty formats supported) -
Application-specific properties from
application.{extension}(Either.properties,.json,.ymlor.groovyproperty formats supported)
To use custom properties from local files, you can either call your application with -Dmicronaut.config.files=myfile.yml or set the environment variable MICRONAUT_CONFIG_FILES=myfile.yml. The value can be a comma-separated list.
|
Property Value Placeholders
Micronaut includes a property placeholder syntax which can be used to reference configuration properties both within configuration values and with any Micronaut annotation (see @Value and the section on Configuration Injection).
| Programmatic usage is also possible via the PropertyPlaceholderResolver interface. |
The basic syntax is to wrap a reference to a property in ${…}. For example in application.yml:
Defining Property Placeholders
myapp:
endpoint: http://${micronaut.server.host}:${micronaut.server.port}/fooThe above example embeds references to the micronaut.server.host and micronaut.server.port properties.
You can specify default values by defining a value after the : character. For example:
Using Default Values
myapp:
endpoint: http://${micronaut.server.host:localhost}:${micronaut.server.port:8080}/fooThe above example will default to localhost and port 8080 if no value is found (rather than throwing an exception). Note that if default value itself contains a : character, you should escape it using back ticks:
Using Backticks
myapp:
endpoint: ${server.address:`http://localhost:8080`}/fooThe above example tries to read a server.address property otherwise fallbacks back to http://localhost:8080, since the address has a : character we have to escape it with back ticks.
Property Value Binding
Note that these property references should always be in kebab case (lowercase and hyphen-separated) when placing references in code or in placeholder values. In other words you should use for example micronaut.server.default-charset and not micronaut.server.defaultCharset.
Micronaut still allows specifying the latter in configuration, but normalizes the properties into kebab case form to optimize memory consumption and reduce complexity when resolving properties. The following table summarizes how properties are normalized from different sources:
| Configuration Value | Resulting Properties | Property Source |
|---|---|---|
|
|
Properties, YAML etc. |
|
|
Properties, YAML etc. |
|
|
Properties, YAML etc. |
|
|
Environment Variable |
|
|
Environment Variable |
Environment variables are given special treatment to allow the definition of environment variables to be more flexible.
Using Random Properties
You can use random values by using the following properties. These can be used in configuration files as variables like the following.
micronaut:
application:
name: myapplication
instance:
id: ${random.shortuuid}| Property | Value |
|---|---|
random.port |
An available random port number |
random.int |
Random int |
random.integer |
Random int |
random.long |
Random long |
random.float |
Random float |
random.shortuuid |
Random UUID of only 10 chars in length (Note: As this isn’t full UUID, collision COULD occur) |
random.uuid |
Random UUID with dashes |
random.uuid2 |
Random UUID without dashes |
4.3 Configuration Injection
You can inject configuration values into beans with Micronaut using the @Value annotation.
Using the @Value Annotation
Consider the following example:
@Value Example
import io.micronaut.context.annotation.Value
import javax.inject.Singleton
@Singleton
class EngineImpl implements Engine {
@Value('${my.engine.cylinders:6}') (1)
protected int cylinders
@Override
int getCylinders() {
this.cylinders
}
String start() { (2)
"Starting V${cylinders} Engine"
}
}| 1 | The @Value annotation accepts a string that can have embedded placeholder values (the default value can be provided by specifying a value after the colon : character). |
| 2 | The injected value can then be used within code. |
Note that @Value can also be used to inject a static value, for example the following will inject the number 10:
Static @Value Example
@Value("10")
int number;However it is definitely more useful when used to compose injected values combining static content and placeholders. For example to setup a URL:
Placeholders with @Value
@Value("http://${my.host}:${my.port}")
URL url;In the above example the URL is constructed from 2 placeholder properties that must be present in configuration: my.host and my.port.
Remember that to specify a default value in a placeholder expression, you should use the colon : character, however if the default you are trying to specify has a colon then you should escape the value with back ticks. For example:
Placeholders with @Value
@Value("${my.url:`http://foo.com`}")
URL url;Note that there is nothing special about @Value itself regarding the resolution of property value placeholders.
Due to Micronaut’s extensive support for annotation metadata you can in fact use property placeholder expressions on any annotation. For example, to make the path of a @Controller configurable you can do:
@Controller("${hello.controller.path:/hello}")
class HelloController {
...
}In the above case if hello.controller.path is specified in configuration then the controller will be mapped to the path specified otherwise it will be mapped to /hello.
You can also make the target server for @Client configurable (although service discovery approaches are often better), for example:
@Client("${my.server.url:`http://localhost:8080`}")
interface HelloClient {
...
}In the above example the property my.server.url can be used to configure the client otherwise the client will fallback to a localhost address.
Using the @Property Annotation
Recall that the @Value annotation receives a String value which is a mix of static content and placeholder expressions. This can lead to confusion if you attempt to do the following:
Incorrect usage of
@Value@Value("my.url")
String url;In the above case the value my.url will be injected and set to the url field and not the value of the my.url property from your application configuration, this is because @Value only resolves placeholders within the value specified to it.
If you wish to inject a specific property name then you may be better off using @Property:
Using
@Property@Property(name = "my.url")
String url;The above will instead inject the value of the my.url property resolved from application configuration. You can also use this feature to resolve sub maps. For example, consider the following configuration:
Example
application.yml configurationdatasources:
default:
name: 'mydb'
jpa:
default:
properties:
hibernate:
hbm2ddl:
auto: update
show_sql: trueIf you wish to resolve a flattened map containing only the properties starting with hibernate then you can do so with @Property, for example:
Using
@Property@Property(name = "jpa.default.properties")
Map<String, String> jpaProperties;The injected map will contain the keys hibernate.hbm2ddl.auto and hibernate.show_sql and their values.
| The @MapFormat annotation can be used to customize the injected map depending whether you want nested keys, flat keys and it allows customization of the key style via the StringConvention enum. |
4.4 Configuration Properties
You can create type safe configuration by creating classes that are annotated with @ConfigurationProperties.
Micronaut will produce a reflection-free @ConfigurationProperties bean and will also at compile time calculate the property paths to evaluate, greatly improving the speed and efficiency of loading @ConfigurationProperties.
An example of a configuration class can be seen below:
@ConfigurationProperties Example
import io.micronaut.context.annotation.ConfigurationProperties
import javax.validation.constraints.Min
import javax.validation.constraints.NotBlank
@ConfigurationProperties('my.engine') (1)
class EngineConfig {
@NotBlank (2)
String manufacturer = "Ford" (3)
@Min(1L)
int cylinders
CrankShaft crankShaft = new CrankShaft()
@ConfigurationProperties('crank-shaft')
static class CrankShaft { (4)
Optional<Double> rodLength = Optional.empty() (5)
}
}| 1 | The @ConfigurationProperties annotation takes the configuration prefix |
| 2 | You can use javax.validation to validate the configuration |
| 3 | Default values can be assigned to the property |
| 4 | Static inner classes can provided nested configuration |
| 5 | Optional configuration values can be wrapped in a java.util.Optional |
Once you have prepared a type safe configuration it can simply be injected into your objects like any other bean:
@ConfigurationProperties Dependency Injection
@Singleton
class EngineImpl implements Engine {
final EngineConfig config
EngineImpl(EngineConfig config) { (1)
this.config = config
}
@Override
int getCylinders() {
config.cylinders
}
String start() { (2)
"${config.manufacturer} Engine Starting V${config.cylinders} [rodLength=${config.crankShaft.rodLength.orElse(6.0d)}]"
}
}| 1 | Inject the EngineConfig bean |
| 2 | Use the configuration properties |
Configuration values can then be supplied from one of the PropertySource instances. For example:
Supply Configuration
ApplicationContext applicationContext = ApplicationContext.run(
['my.engine.cylinders': '8'],
"test"
)
Vehicle vehicle = applicationContext
.getBean(Vehicle)
println(vehicle.start())The above example prints: "Ford Engine Starting V8 [rodLength=6.0]"
Note for more complex configurations you can structure @ConfigurationProperties beans through inheritance.
For example creating a subclass of EngineConfig with @ConfigurationProperties('bar') will resolve all properties under the path my.engine.bar.
Property Type Conversion
When resolving properties Micronaut will use the ConversionService bean to convert properties. You can register additional converters for types not supported by micronaut by defining beans that implement the TypeConverter interface.
Micronaut features some built-in conversions that are useful, which are detailed below.
Duration Conversion
Durations can be specified by appending the unit with a number. Supported units are s, ms, m etc. The following table summarizes examples:
| Configuration Value | Resulting Value |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
Duration of 15 minutes using ISO-8601 format |
For example to configure the default HTTP client read timeout:
Using Duration Values
micronaut:
http:
client:
read-timeout: 15sList / Array Conversion
Lists and arrays can be specified in Java properties files as comma-separated values or in YAML using native YAML lists. The generic types are used to convert the values. For example in YAML:
Specifying lists or arrays in YAML
my:
app:
integers:
- 1
- 2
urls:
- http://foo.com
- http://bar.comOr in Java properties file format:
Specifying lists or arrays in Java properties comma-separated
my.app.integers=1,2
my.app.urls=http://foo.com,http://bar.comAlternatively you can use an index:
Specifying lists or arrays in Java properties using index
my.app.integers[0]=1
my.app.integers[1]=2For the above example configurations you can define properties to bind to with the target type supplied via generics:
List<Integer> integers;
List<URL> urls;Readable Bytes
You can annotate any setter parameter with @ReadableBytes to allow the value to be set using a shorthand syntax for specifying bytes, kilobytes etc. For example the following is taken from HttpClientConfiguration:
Using
@ReadableBytespublic void setMaxContentLength(@ReadableBytes int maxContentLength) {
this.maxContentLength = maxContentLength;
}With the above in place you can set micronaut.http.client.max-content-length using the following values:
| Configuration Value | Resulting Value |
|---|---|
|
10 megabytes |
|
10 kilobytes |
|
10 gigabytes |
|
A raw byte length |
Formatting Dates
The @Format annotation can be used on any setter to allow the date format to be specified when binding javax.time date objects.
Using
@Format for Datespublic void setMyDate(@Format("yy-mm-dd") LocalDate date) {
this.myDate = date;
}Configuration Builder
Many existing frameworks and tools already use builder-style classes to construct configuration.
To support the ability for a builder style class to be populated with configuration values, the @ConfigurationBuilder annotation can be used. ConfigurationBuilder can be added to a field or method in a class annotated with @ConfigurationProperties.
Since there is no consistent way to define builders in the Java world, one or more method prefixes can be specified in the annotation to support builder methods like withXxx or setXxx. If the builder methods have no prefix, assign an empty string to the parameter.
A configuration prefix can also be specified to tell Micronaut where to look for configuration values. By default, the builder methods will use the configuration prefix defined at the class level @ConfigurationProperties annotation.
For example:
@ConfigurationBuilder Example
import io.micronaut.context.annotation.ConfigurationBuilder
import io.micronaut.context.annotation.ConfigurationProperties
@ConfigurationProperties('my.engine') (1)
class EngineConfig {
@ConfigurationBuilder(prefixes = "with") (2)
EngineImpl.Builder builder = EngineImpl.builder()
@ConfigurationBuilder(prefixes = "with", configurationPrefix = "crank-shaft") (3)
CrankShaft.Builder crankShaft = CrankShaft.builder()
}| 1 | The @ConfigurationProperties annotation takes the configuration prefix |
| 2 | The first builder can be configured with the class configuration prefix |
| 3 | The second builder can be configured with the class configuration prefix + the configurationPrefix value. |
By default, only builder methods that take a single argument are supported. To support methods with no arguments, set the allowZeroArgs parameter of the annotation to true.
|
Just like in the previous example, we can construct an EngineImpl. Since we are using a builder, a factory class can be used to build the engine from the builder.
Factory Bean
import io.micronaut.context.annotation.Bean
import io.micronaut.context.annotation.Factory
import javax.inject.Singleton
@Factory
class EngineFactory {
@Bean
@Singleton
EngineImpl buildEngine(EngineConfig engineConfig) {
engineConfig.builder.build(engineConfig.crankShaft)
}
}The engine that was returned can then be injected anywhere an engine is depended on.
Configuration values can be supplied from one of the PropertySource instances. For example:
Supply Configuration
ApplicationContext applicationContext = ApplicationContext.run(
['my.engine.cylinders':'4',
'my.engine.manufacturer': 'Subaru',
'my.engine.crank-shaft.rod-length': 4],
"test"
)
Vehicle vehicle = applicationContext
.getBean(Vehicle)
println(vehicle.start())The above example prints: "Subaru Engine Starting V4 [rodLength=4.0]"
MapFormat
For some use cases it may be desirable to accept a map of arbitrary configuration properties that can be supplied to a bean, especially if the bean represents a third-party API where not all of the possible configuration properties are known by the developer. For example, a datasource may accept a map of configuration properties specific to a particular database driver, allowing the user to specify any desired options in the map without coding every single property explicitly.
For this purpose, the MapFormat annotation allows you to bind a map to a single configuration property, and specify whether to accept a flat map of keys to values, or a nested map (where the values may be additional maps].
@MapFormat Example
import io.micronaut.core.convert.format.MapFormat
@ConfigurationProperties('my.engine')
class EngineConfig {
@Min(1L)
int cylinders
@MapFormat(transformation = MapFormat.MapTransformation.FLAT) (1)
Map<Integer, String> sensors
}| 1 | Note the transformation argument to the annotation; possible values are MapTransformation.FLAT (for flat maps) and MapTransformation.NESTED (for nested maps) |
EngineImpl
@Singleton
class EngineImpl implements Engine {
@Inject EngineConfig config
@Override
Map getSensors() {
config.sensors
}
String start() {
"Engine Starting V${config.cylinders} [sensors=${sensors.size()}]"
}
}Now a map of properties can be supplied to the my.engine.sensors configuration property.
Use Map Configuration
ApplicationContext applicationContext = ApplicationContext.run(
['my.engine.cylinders': '8', 'my.engine.sensors': [0: 'thermostat', 1: 'fuel pressure']],
"test"
)
Vehicle vehicle = applicationContext
.getBean(Vehicle)
println(vehicle.start())The above example prints: "Engine Starting V8 [sensors=2]"
4.5 Custom Type Converters
Micronaut features a built in type conversion mechanism that is extensible. To add additional type converters you register beans of type TypeConverter.
The following example shows how to use one of the built-in converters (Map to an Object) or create your own.
Consider the following ConfigurationProperties:
@ConfigurationProperties(MyConfigurationProperties.PREFIX)
class MyConfigurationProperties {
public static final String PREFIX = "myapp"
protected LocalDate updatedAt
LocalDate getUpdatedAt() {
return this.updatedAt
}
}The type MyConfigurationProperties features a property called updatedAt which is of type LocalDate.
Now let’s say you want to allow binding to this property from a map via configuration:
ApplicationContext ctx = ApplicationContext.run(
"myapp.updatedAt": [day: 28, month: 10, year: 1982] (1)
)This won’t work by default, since there is no built in conversion from Map to LocalDate. To resolve this you can define a custom TypeConverter:
import io.micronaut.core.convert.*
import java.time.*
import javax.inject.Singleton
@Singleton
class MapToLocalDateConverter implements TypeConverter<Map, LocalDate> { (1)
@Override
Optional<LocalDate> convert(Map object, Class<LocalDate> targetType, ConversionContext context) {
Optional<Integer> day = ConversionService.SHARED.convert(object.get("day"), Integer.class)
Optional<Integer> month = ConversionService.SHARED.convert(object.get("month"), Integer.class)
Optional<Integer> year = ConversionService.SHARED.convert(object.get("year"), Integer.class)
if (day.isPresent() && month.isPresent() && year.isPresent()) {
try {
return Optional.of(LocalDate.of(year.get(), month.get(), day.get())) (2)
} catch (DateTimeException e) {
context.reject(object, e) (3)
return Optional.empty()
}
}
return Optional.empty()
}
}| 1 | The class implements TypeConverter which takes two generic arguments. The type you are converting from and the type you are converting to |
| 2 | The implementation delegate to the default shared conversion service to convert the parts of the map that make the day, month and year into a LocalDate |
| 3 | If an exception occurs you can call reject(..) which propagates additional information to the container if something goes wrong during binding |
4.6 Using @EachProperty to Drive Configuration
The @ConfigurationProperties annotation is great for a single configuration class, but sometimes you want multiple instances each with their own distinct configuration. That is where EachProperty comes in.
The @EachProperty annotation will create a ConfigurationProperties bean for each sub-property within the given property. As an example consider the following class:
Using @EachProperty
import io.micronaut.context.annotation.Parameter;
import io.micronaut.context.annotation.EachProperty;
@EachProperty("test.datasource") (1)
public class DataSourceConfiguration {
private final String name;
private URI url = new URI("localhost");
public DataSourceConfiguration(@Parameter String name) (2)
throws URISyntaxException {
this.name = name;
}
public String getName() {
return name;
}
public URI getUrl() { (3)
return url;
}
public void setUrl(URI url) {
this.url = url;
}
}| 1 | The @EachProperty annotation defines the property name that should be handled. |
| 2 | The @Parameter annotation can be used to inject the name of the sub-property that defines the name of the bean (which is also the bean qualifier) |
| 3 | Each property of the bean is bound to configuration. |
The above DataSourceConfiguration defines a url property to configure one or many hypothetical data sources of some sort. The URLs themselves can be configured using any of the PropertySource instances evaluated to Micronaut:
Providing Configuration to @EachProperty
ApplicationContext applicationContext = ApplicationContext.run(PropertySource.of(
"test",
CollectionUtils.mapOf(
"test.datasource.one.url", "jdbc:mysql://localhost/one",
"test.datasource.two.url", "jdbc:mysql://localhost/two")
));In the above example two data sources (called one and two) are defined under the test.datasource prefix defined earlier in the @EachProperty annotation. Each of these configuration entries triggers the creation of a new DataSourceConfiguration bean such that the following test succeeds:
Evaluating Beans Built by @EachProperty
Collection<DataSourceConfiguration> beansOfType = applicationContext.getBeansOfType(DataSourceConfiguration.class);
assertEquals(beansOfType.size(), 2); (1)
DataSourceConfiguration firstConfig = applicationContext.getBean(
DataSourceConfiguration.class,
Qualifiers.byName("one") (2)
);
assertEquals(
firstConfig.getUrl(),
new URI("jdbc:mysql://localhost/one")
);| 1 | All beans of type DataSourceConfiguration can be retrieved using getBeansOfType |
| 2 | Individual beans can be achieved by using the byName qualifier. |
4.7 Using @EachBean to Drive Configuration
The @EachProperty is a great way to drive dynamic configuration, but typically you want to inject that configuration into another bean that depends on it. Injecting a single instance with a hard coded qualifier is not a great solution, hence @EachProperty is typically used in combination with @EachBean:
Using @EachBean
@Factory (1)
public class DataSourceFactory {
@EachBean(DataSourceConfiguration.class) (2)
DataSource dataSource(DataSourceConfiguration configuration) { (3)
URI url = configuration.getUrl();
return new DataSource(url);
}
}| 1 | The above example defines a bean Factory that will create instances of javax.sql.DataSource. |
| 2 | The @EachBean annotation is used to indicate that a new DataSource bean should be created for each DataSourceConfiguration defined in the previous section. |
| 3 | The DataSourceConfiguration instance is injected as a method argument and used to drive the configuration of each javax.sql.DataSource |
Note that @EachBean requires that the parent bean has a @Named qualifier, since the qualifier is inherited by each bean created by @EachBean.
In other words, to retrieve the DataSource created by test.datasource.one you can do:
Using a Qualifier
DataSource firstDataSource = applicationContext.getBean(
DataSource.class,
Qualifiers.byName("one")
);4.8 JMX Support
Micronaut currently has basic support for JMX. At this time, the support is experimental and subject to change. To get started, simply add a dependency on the configuration.
compile "io.micronaut.configuration:micronaut-jmx"The configuration will create a bean for the management bean server based on configuration.
| Property | Type | Description |
|---|---|---|
|
java.lang.String |
Sets the agent id. |
|
java.lang.String |
Sets the domain to create a new server with. |
|
boolean |
Sets if the server should be kept in the factory. Default true. |
|
boolean |
Sets to ignore the exception if the agent is not found. Default false. |
|
boolean |
Sets if endpoints should be registered. Default true. |
Endpoints
If the management dependency is also on the classpath, management beans will be created for all endpoints by default.
5 Aspect Oriented Programming
Aspect-Oriented Programming (AOP) historically has had many incarnations and some very complicated implementations. Generally AOP can be thought of as a way to define cross cutting concerns (logging, transactions, tracing etc.) separate from application code in the form of aspects that define advice.
There are typically two forms of advice:
-
Around Advice - decorates a method or class
-
Introduction Advice - introduces new behaviour to a class.
In modern Java applications declaring advice typically takes the form of an annotation. The most well-known annotation advice in the Java world is probably @Transactional which is used to demarcate transaction boundries in Spring and Grails applications.
The disadvantage of traditional approaches to AOP is the heavy reliance on runtime proxy creation and reflection, which slows application performance, makes debugging harder and increases memory consumption.
Micronaut tries to address these concerns by providing a simple compile time AOP API that does not use reflection.
5.1 Around Advice
The most common type of advice you may want to apply is "Around" advice, which essentially allows you decorate a methods behaviour.
Writing Around Advice
The first step to defining Around advice is to implement a MethodInterceptor. For example the following interceptor disallows parameters with null values:
MethodInterceptor Example
import io.micronaut.aop.*;
import io.micronaut.core.type.MutableArgumentValue;
import javax.inject.Singleton;
import java.util.*;
@Singleton
public class NotNullInterceptor implements MethodInterceptor<Object, Object> { (1)
@Override
public Object intercept(MethodInvocationContext<Object, Object> context) {
Optional<Map.Entry<String, MutableArgumentValue<?>>> nullParam = context.getParameters()
.entrySet()
.stream()
.filter(entry -> {
MutableArgumentValue<?> argumentValue = entry.getValue();
return Objects.isNull(argumentValue.getValue());
})
.findFirst(); (2)
if (nullParam.isPresent()) {
throw new IllegalArgumentException("Null parameter [" + nullParam.get().getKey() + "] not allowed"); (3)
} else {
return context.proceed(); (4)
}
}
}| 1 | An interceptor implements the MethodInterceptor interface |
| 2 | The passed MethodInvocationContext is used to find the first parameter that is null |
| 3 | If a null parameter is found an exception is thrown |
| 4 | Otherwise proceed() is called to proceed with the method invocation. |
| Micronaut AOP interceptors use no reflection which improves performance and reducing stack trace sizes, thus improving debugging. |
To put the new MethodInterceptor to work the next step is to define an annotation that will trigger the MethodInterceptor:
Around Advice Annotation Example
import io.micronaut.context.annotation.Type;
import io.micronaut.aop.Around;
import java.lang.annotation.*;
import static java.lang.annotation.RetentionPolicy.RUNTIME;
@Documented
@Retention(RUNTIME) (1)
@Target({ElementType.TYPE, ElementType.METHOD}) (2)
@Around (3)
@Type(NotNullInterceptor.class) (4)
public @interface NotNull {
}| 1 | The retention policy of the annotation should be RUNTIME |
| 2 | Generally you want to be able to apply advice at the class or method level so the target types are TYPE and METHOD |
| 3 | The Around annotation is added to tell Micronaut that the annotation is Around advice |
| 4 | The @Type annotation is used to configure which type implements the advice (in this case the previously defined NotNullInterceptor) |
With the interceptor and annotation implemented you can then simply apply the annotation to the target classes:
Around Advice Usage Example
@Singleton
public class NotNullExample {
@NotNull
void doWork(String taskName) {
System.out.println("Doing job: " + taskName);
}
}Whenever the type NotNullExample is injected into any class a compile time generated proxy will instead by injected that decorates the appropriate method calls with the @NotNull advice defined earlier. You can verify that the advice works by writing a test. The following test uses a JUnit ExpectedException rule to verify the appropriate exception is thrown when an argument is null:
Around Advice Test
@Rule
public ExpectedException thrown = ExpectedException.none();
@Test
public void testNotNull() {
ApplicationContext applicationContext = ApplicationContext.run();
NotNullExample exampleBean = applicationContext.getBean(NotNullExample.class);
thrown.expect(IllegalArgumentException.class);
thrown.expectMessage("Null parameter [taskName] not allowed");
exampleBean.doWork(null);
}| Since Micronaut is compile time, generally the advice should be packaged in a dependent JAR file that is on the classpath when the above test is compiled and should not be in the same codebase since you don’t want the test compiling before the advice itself is compiled. |
Customizing Proxy Generation
The default behaviour of the Around annotation is to generate a proxy at compile time that is a subclass of the class being proxied. In other words, in the previous example a compile time subclass of the NotNullExample class will be produced where methods that are proxied are decorated with interceptor handling and the original behaviour is invoked via a call to super.
This behaviour is more efficient as only one instance of the bean is required, however depending on the use case you are trying to implement you may wish to alter this behaviour and the @Around annotation supports various attributes that allow you to alter this behaviour including:
-
proxyTarget(defaults tofalse) - If set totrueinstead of a subclass that callssuper, the proxy will delegate to the original bean instance -
hotswap(defaults tofalse) - Same asproxyTarget=true, but in addition the proxy will implement HotSwappableInterceptedProxy which wraps each method call in aReentrantReadWriteLockand allows swapping the target instance at runtime. -
lazy(defaults tofalse) - By default Micronaut will eagerly intialize the proxy target when the proxy is created. If set totruethe proxy target will instead be resolved lazily for each method call.
5.2 Introduction Advice
Introduction advice is distinct from Around advice in that it involves providing an implementation instead of decorating.
Examples of introduction advice include things like GORM or Spring Data that will both automatically implement persistence logic for you.
Micronaut’s Client annotation is another example of introduction advice where Micronaut will, at compile time, implement HTTP client interfaces for you.
The way you implement Introduction advice is very similar to how you implement Around advice.
You start off by defining an annotation that will power the introduction advice. As an example, say you want to implement advice that will return a stubbed value for every method in an interface (a common requirement in testing frameworks). Consider the following @Stub annotation:
Introduction Advice Annotation Example
import static java.lang.annotation.RetentionPolicy.RUNTIME;
import io.micronaut.aop.Introduction;
import io.micronaut.context.annotation.Bean;
import io.micronaut.context.annotation.Type;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
@Introduction (1)
@Type(StubIntroduction.class) (2)
@Bean (3)
@Documented
@Retention(RUNTIME)
@Target({ElementType.TYPE, ElementType.ANNOTATION_TYPE, ElementType.METHOD})
public @interface Stub {
String value() default "";
}| 1 | The introduction advice is annotated with Introduction |
| 2 | The Type annotation is used to refer to the implementor of the advise. In this case StubIntroduction |
| 3 | The Bean annotation is added so that all types annotated with @Stub become beans |
The StubIntroduction class referred to in the previous example must then implement the MethodInterceptor interface, just like around advice.
The following is an example implementation:
StubIntroduction.java
import io.micronaut.aop.*;
import javax.inject.Singleton;
@Singleton
public class StubIntroduction implements MethodInterceptor<Object,Object> { (1)
@Override
public Object intercept(MethodInvocationContext<Object, Object> context) {
return context.getValue( (2)
Stub.class,
context.getReturnType().getType()
).orElse(null); (3)
}
}| 1 | The class is annotated with @Singleton and implements the MethodInterceptor interface |
| 2 | The value of the @Stub annotation is read from the context and an attempt made to convert the value to the return type |
| 3 | Otherwise null is returned |
To now use this introduction advice in an application you simply annotate your abstract classes or interfaces with @Stub:
StubExample.java
@Stub
public interface StubExample {
@Stub("10")
int getNumber();
LocalDateTime getDate();
}All abstract methods will delegate to the StubIntroduction class to be implemented.
The following test demonstrates the behaviour or StubIntroduction:
Testing Introduction Advice
StubExample stubExample = applicationContext.getBean(StubExample.class);
assertEquals(10, stubExample.getNumber());
assertNull(stubExample.getDate());Note that if the introduction advice cannot implement the method the proceed method of the MethodInvocationContext should be called. This gives the opportunity for other introduction advice interceptors to implement the method, otherwise a UnsupportedOperationException will be thrown if no advice can implement the method.
In addition, if multiple introduction advice are present you may wish to override the getOrder() method of MethodInterceptor to control the priority of advise.
The following sections cover core advice types that are built into Micronaut and provided by the framework.
5.3 Method Adapter Advice
There are sometimes cases where you want to introduce a new bean based on the presence of an annotation on a method. An example of this case is the @EventListener annotation which for each method annotated with @EventListener produces an implementation of ApplicationEventListener that invokes the annotated method.
For example the following snippet will run the logic contained within the method when the ApplicationContext starts up:
import io.micronaut.context.event.StartupEvent;
import io.micronaut.runtime.event.annotation.EventListener;
...
@EventListener
void onStartup(StartupEvent event) {
// startup logic here
}The presence of the @EventListener annotation causes Micronaut to create a new class that implements the ApplicationEventListener and invokes the onStartup method defined in the bean above.
The actual implementation of the @EventListener is trivial, it simply uses the @Adapter annotation to specify which SAM (single abstract method) type it adapts:
import io.micronaut.aop.Adapter;
import io.micronaut.context.event.ApplicationEventListener;
import java.lang.annotation.*;
import static java.lang.annotation.RetentionPolicy.RUNTIME;
@Documented
@Retention(RUNTIME)
@Target({ElementType.ANNOTATION_TYPE, ElementType.METHOD})
@Adapter(ApplicationEventListener.class) (1)
public @interface EventListener {
}| 1 | The @Adapter annotation is used to indicate which SAM type to adapt. In this case ApplicationEventListener. |
| Micronaut will also automatically align the generic types for the SAM interface if they are specified. |
Using this mechanism you can define custom annotations that use the @Adapter annotation and a SAM interface to automatically implement beans for you at compile time.
5.4 Validation Advice
Validation advice is one of the most common advice types you are likely to want to incorporate into your application.
Validation advice is built on JSR 380, also known as Bean Validation 2.0.
JSR 380 is a specification of the Java API for bean validation which ensures that the
properties of a bean meet specific criteria, using javax.validation annotations such as @NotNull, @Min, and @Max.
Hibernate Validator project is a reference implementation for JSR 380. Micronaut ships with a built-in configuration to use Hibernate Validator.
To get started, first add the Hibernate Validator configuration to your application:
build.gradle
compile "io.micronaut.configuration:micronaut-hibernate-validator"Then simply add the Validated annotation to any class that requires validation. For example, consider this trivial service that retrieves books by title:
BookService.java
import io.micronaut.validation.Validated;
import javax.inject.Singleton;
import javax.validation.constraints.NotBlank;
import java.util.*;
@Singleton
@Validated (1)
public class BookService {
private Map<String, String> authorsByTitle = new LinkedHashMap<>();
public String getAuthor(@NotBlank String title) { (2)
return authorsByTitle.get(title);
}
public void addBook(@NotBlank String author, @NotBlank String title) {
authorsByTitle.put(title, author);
}
}| 1 | The Validated annotation is defined at the class level |
| 2 | The javax.validation.NotBlank constraint is used to ensure parameters passed cannot be blank |
You can verify the behaviour of the class by writing a test. The following test is written in Groovy and Spock:
Testing Validation
void "test validate book service"() {
given:
BookService bookService = applicationContext.getBean(BookService)
when:"An invalid title is passed"
bookService.getAuthor("")
then:"A constraint violation occurred"
def e = thrown(ConstraintViolationException)
e.message == 'getAuthor.title: must not be blank'
}5.5 Cache Advice
Similar to Spring and Grails, Micronaut provides a set of caching annotations within the io.micronaut.cache package.
The CacheManager interface allows different cache implementations to be plugged in as necessary.
The SyncCache interface provides a synchronous API for caching, whilst the AsyncCache API allows non-blocking operation.
Cache Annotations
The following cache annotations are supported:
-
@Cacheable - Indicates a method is cacheable within the given cache name
-
@CachePut - Indicates that the return value of a method invocation should be cached. Unlike
@Cacheablethe original operation is never skipped. -
@CacheInvalidate - Indicates the invocation of a method should cause the invalidation of one or many caches.
By using one of the annotations the CacheInterceptor is activated which in the case of @Cacheable will cache the return result of the method.
If the return type of the method is a non-blocking type (either CompletableFuture or an instance of org.reactivestreams.Publisher) the emitted result will be cached.
In addition if the underlying Cache implementation supports non-blocking cache operations then cache values will be read from the cache without blocking, resulting in the ability to implement completely non-blocking cache operations.
Configuring Caches
By default Caffeine is used for cache definitions which can be configured via application configuration. For example with application.yml:
Cache Configuration Example
micronaut:
caches:
myCache:
maximumSize: 20The above example will configure a cache called "myCache" with a maximum size of 20.
To configure a weigher to be used with the maximumWeight configuration, create a bean that implements io.micronaut.caffeine.cache.Weigher. To associate a given weigher with only a specific cache, annotate the bean with @Named(<cache name>). Weighers without a named qualifier will apply to all caches that don’t have a named weigher. If no beans are found, a default implementation will be used.
| Property | Type | Description |
|---|---|---|
|
java.nio.charset.Charset |
The charset used to serialize and deserialize values |
|
java.lang.Integer |
The initial cache capacity. |
|
java.lang.Long |
Specifies the maximum number of entries the cache may contain |
|
java.lang.Long |
Specifies the maximum weight of entries |
|
java.time.Duration |
The cache expiration duration after writing into it. |
|
java.time.Duration |
The cache expiration duration after accessing it |
|
boolean |
Set whether test mode is enabled. Default value (false). |
Caching with Redis
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features redis-lettuce |
If you wish to use Redis to cache results then you need to have the Lettuce configuration dependency on your classpath. Lettuce is a non-blocking, reactive Redis client implementation and Micronaut provides an implementation that allows cached results to be read reactively.
To enable Lettuce, add the redis-lettuce dependency to your application:
Lettuce Configuration build.gradle
dependencies {
...
compile "io.micronaut.configuration:micronaut-redis-lettuce"
...
}Then within your application configuration configure the Redis URL and Redis caches:
Cache Configuration Example
micronaut:
redis:
uri: redis://localhost
caches:
myCache:
expireAfterWrite: "1h" # expire one hour after write| Property | Type | Description |
|---|---|---|
|
java.lang.String |
|
|
java.lang.Class |
|
|
java.lang.Class |
5.6 Retry Advice
In distributed systems and Microservice environments, failure is something you have to plan for and it is pretty common to want to attempt to retry an operation if it fails. If first you don’t succeed try again!
With this in mind Micronaut comes with a Retryable annotation out of the box that is integrated into the container.
Simple Retry
The simplest form of retry is just to add the @Retryable annotation to any type or method. The default behaviour of @Retryable is to retry 3 times with a delay of 1 second between each retry.
For example:
Simply Retry Example
@Retryable
public List<Book> listBooks() {
...
}With the above example if the listBooks() method throws an exception it will be retried until the maximum number of attempts is reached.
The multiplier value of the @Retryable annotation can be used to configure a multiplier used to calculate the delay between retries, thus allowing exponential retry support.
Note also that the @Retryable annotation can be applied on interfaces and the behaviour will be inherited through annotation metadata. The implication of this is that @Retryable can be used in combination with Introduction Advice such as the HTTP Client annotation.
To customize retry behaviour you can set the attempts and delay members, For example to configure 5 attempts with a 2 second delay:
Setting Retry Attempts
@Retryable( attempts = "5",
delay = "2s" )
public Book findBook(String title) {
...
}Notice how both attempts and delay are defined as strings. This is to support configurability through annotation metadata. For example you can allow the retry policy to be configured using property placeholder resolution:
Setting Retry via Configuration
@Retryable( attempts = "${book.retry.attempts:3}",
delay = "${book.retry.delay:1s}" )
public Book getBook(String title) {
...
}With the above in place if book.retry.attempts is specified in configuration it wil be bound the value of the attempts member of the @Retryable annotation via annotation metadata.
Reactive Retry
@Retryable advice can also be applied to methods that return reactive types, such as an RxJava Flowable. For example:
Applying Retry Policy to Reactive Types
@Retryable
public Flowable<Book> streamBooks() {
...
}In this case @Retryable advice will apply the retry policy to the reactive type.
Circuit Breaker
In a Microservice environment retry is useful, but in some cases excessive retries can overwhelm the system as clients repeatedly re-attempt failing operations.
The Circuit Breaker pattern is designed to resolve this issue by essentially allowing a certain number of failing requests and then opening a circuit that remains open for a period before allowing any additional retry attempts.
The CircuitBreaker annotation is a variation of the @Retryable annotation that supports a reset member that indicates how long the circuit should remain open before it is reset (the default is 20 seconds).
Applying CircuitBreaker Advice
@CircuitBreaker(reset = "30s")
public List<Book> findBooks() {
...
}The above example will retry to findBooks method 3 times and then open the circuit for 30 seconds, rethrowing the original exception and preventing potential downstream traffic such as HTTP requests and I/O operations flooding the system.
Bean Creation Retry
As mentioned previously, @Retryable advice is integrated right at the container level. This is useful as it is common problem in Microservices and environments like Docker where there may be a delay in services becoming available.
The following snippet is taken from the Neo4j driver support and demonstrates how bean creation can be wrapped in retry support:
@Factory (1)
public class Neo4jDriverFactory {
...
@Retryable(ServiceUnavailableException.class) (2)
@Bean(preDestroy = "close")
public Driver buildDriver() {
...
}
}| 1 | A factory bean is created that defines methods that create beans |
| 2 | The @Retryable annotation is used to catch ServiceUnavailableException and retry creating the driver before failing startup. |
Retry Events
You can register RetryEventListener instances as beans in order to listen for RetryEvent events that are published every time an operation is retried.
In addition, you can register event listeners for CircuitOpenEvent, when a circuit breaker circuit is opened, or CircuitClosedEvent for when a circuit is closed.
5.7 Scheduled Tasks
Like Spring and Grails, Micronaut features a Scheduled annotation that can be used for scheduling background tasks.
Using the @Scheduled Annotation
The Scheduled annotation can be added to any method of a bean and you should set either the fixedRate, fixedDelay or cron members.
Remember that the scope of the bean has an impact on behaviour. a @Singleton bean will share state (the fields of the instance) each time the scheduled method is executed, while for a @Prototype bean a new instance is created for each execution.
|
Scheduling at a Fixed Rate
To schedule a task at a fixed rate, use the fixedRate member. For example:
Fixed Rate Example
@Scheduled(fixedRate = "5m")
void everyFiveMinutes() {
System.out.println("Executing everyFiveMinutes()");
}The task above will execute every 5 minutes.
Scheduling with a Fixed Delay
To schedule a task so that is runs 5 minutes after the termination of the previous task use the fixedDelay member. For example:
Fixed Delay Example
@Scheduled(fixedDelay = "5m")
void fiveMinutesAfterLastExecution() {
System.out.println("Executing fiveMinutesAfterLastExecution()");
}Scheduling a Cron Task
To schedule a Cron task use the cron member:
Cron Example
@Scheduled(cron = "0 15 10 ? * MON" )
void everyMondayAtTenFifteenAm() {
System.out.println("Executing everyMondayAtTenFifteenAm()");
}The above example will run the task every Monday morning at 10:15AM.
Programmatically Scheduling Tasks
If you wish to programmatically schedule tasks, then you can use the TaskScheduler bean which can be injected as follows:
@Inject @Named(TaskExecutors.SCHEDULED) TaskScheduler taskScheduler;Configuring Scheduled Tasks with Annotation Metadata
If you wish to make your application’s tasks configurable then you can use annotation metadata and property placeholder configuration to do so. For example:
Allowing Tasks to be Configured
@Scheduled( fixedRate = "${my.task.rate:5m}",
initialDelay = "${my.task.delay:1m}" )
void configuredTask() {
System.out.println("Executing configuredTask()");
}The above example allows the task execution frequency to be configured with the property my.task.rate and the initial delay to be configured with the property my.task.delay.
Configuring the Scheduled Task Thread Pool
Tasks executed by @Scheduled are by default run on a ScheduledExecutorService that is configured to have twice the number of threads as available processors.
You can configure this thread pool as desired using application.yml, for example:
Configuring Scheduled Task Thread Pool
micronaut:
executors:
scheduled:
type: scheduled
core-pool-size: 30| Property | Type | Description |
|---|---|---|
|
java.lang.Integer |
|
|
Sets the executor type. Default value (SCHEDULED). |
|
|
java.lang.Integer |
Sets the parallelism for WORK_STEALING. Default value (Number of processors available to the Java virtual machine). |
|
java.lang.Integer |
Sets the core pool size for SCHEDULED. Default value (2 * Number of processors available to the Java virtual machine). |
|
java.lang.Class |
Sets the thread factory class. |
|
java.lang.Integer |
Sets the number of threads for FIXED. Default value (2 * Number of processors available to the Java virtual machine). |
Handling Exceptions
By default Micronaut includes a DefaultTaskExceptionHandler bean that implements the TaskExceptionHandler and simply logs the exception if an error occurs invoking a scheduled task.
If you have custom requirements you can replace this bean with a custom implementation (for example if you wish to send an email or shutdown context to fail fast). To do so simply write your own TaskExceptionHandler and annotated it with @Replaces(DefaultTaskExceptionHandler.class).
5.8 Bridging Spring AOP
Although Micronaut’s design is based on a compile time approach and does not rely on Spring dependency injection, there is still a lot of value in the Spring ecosystem that does not depend directly on the Spring container.
You may wish to use existing Spring projects within Micronaut and configure beans to be used within Micronaut.
You may also wish to leverage existing AOP advice from Spring. One example of this is Spring’s support for declarative transactions with @Transactional.
Micronaut provides support for Spring based transaction management without requiring Spring itself. You simply need to add the spring module to your application dependencies:
build.gradle
compile "io.micronaut:micronaut-spring"
If you use Micronaut’s Hibernate support you already get this dependency and a HibernateTransactionManager is configured for you.
|
This is done by defining a Micronaut @Transactional annotation that uses @AliasFor in a manner that every time you set a value with @Transactional it aliases the value to equivalent value in Spring’s version of @Transactional.
The benefit here is you can use Micronaut’s compile-time, reflection free AOP to declare programmatic Spring transactions. For example:
Using @Transactional
import io.micronaut.spring.tx.annotation.*;
...
@Transactional
public Book saveBook(String title) {
...
}| Micronaut’s version of @Transactional is also annotated with @Blocking ensuring that all methods annotated with use the I/O thread pool when executing within the HTTP server |
6 The HTTP Server
|
Using the CLI
If you are creating your project using the Micronaut CLI’s |
Micronaut includes both non-blocking HTTP server and client APIs based on Netty.
The design of the HTTP server in Micronaut is optimized for interchanging messages between Microservices, typically in JSON, and is not intended as a full server-side MVC framework. For example, there is currently no support for server-side views or features typical of a traditional server-side MVC framework.
The goal of the HTTP server is to make it as easy as possible to expose APIs that can be consumed by HTTP clients, whatever language they may be written in. To use the HTTP server you must have the http-server-netty dependency on your classpath. For example in build.gradle:
build.gradle
compile "io.micronaut:micronaut-http-server-netty"A "Hello World" server application written in Java can be seen below:
Micronaut Server Hello World
import io.micronaut.http.MediaType;
import io.micronaut.http.annotation.*;
@Controller("/hello") (1)
public class HelloController {
@Get(produces = MediaType.TEXT_PLAIN) (2)
public String index() {
return "Hello World"; (3)
}
}| 1 | The class is defined as a controller with the @Controller annotation mapped to the path /hello |
| 2 | The scope of the @Controller is singleton |
| 3 | By defining method called index, by convention the method is exposed via the /hello URI |
6.1 Running the Embedded Server
To run the server simply create an Application class with a static void main method. For example:
Micronaut Application Class
import io.micronaut.runtime.Micronaut;
public class Application {
public static void main(String[] args) {
Micronaut.run(Application.class);
}
}To run the application from a unit test you can use the EmbeddedServer interface. The following test is written in Groovy with Spock:
Micronaut Spock Test
import io.micronaut.context.ApplicationContext
import io.micronaut.http.HttpRequest
import io.micronaut.http.client.HttpClient
import io.micronaut.runtime.server.EmbeddedServer
import spock.lang.*
class HelloControllerSpec extends Specification {
@Shared @AutoCleanup EmbeddedServer embeddedServer =
ApplicationContext.run(EmbeddedServer) (1)
@Shared @AutoCleanup HttpClient client = HttpClient.create(embeddedServer.URL) (2)
void "test hello world response"() {
expect:
client.toBlocking() (3)
.retrieve(HttpRequest.GET('/hello')) == "Hello World" (4)
}
}| 1 | The EmbeddedServer is run and Spock’s @AutoCleanup annotation ensures the server is stopped after the specification completes. |
| 2 | The EmbeddedServer interface provides the URL of the server under test which runs on a random port. |
6.2 Running Server on a Specific Port
By default the server runs on port 8080. However, you can set the server to run on a specific port:
micronaut:
server:
port: 8086
This is also possible to be configured from an environment variable: MICRONAUT_SERVER_PORT=8086
|
To run on a random port:
micronaut:
server:
port: -16.3 HTTP Routing
The @Controller annotation used in the previous section is one of several annotations that allow you to control the construction of HTTP routes.
URI Paths
The value of the @Controller annotation is a RFC-6570 URI template you can therefore embed URI variables within the path using the syntax defined by the URI template specification.
| Many other frameworks, including Spring, implement the URI template specification |
The actual implementation is handled by the UriMatchTemplate class, which extends UriTemplate.
You can use this class explicitly within your application to build URIs. For example:
Using a UriTemplate
UriMatchTemplate template = UriMatchTemplate.of("/hello/{name}");
assertTrue(template.match("/hello/John").isPresent()); (1)
assertEquals(template.expand( (2)
Collections.singletonMap("name", "John")
), "/hello/John");| 1 | The match method can be used to match a path |
| 2 | The expand method can be used to expand a template into a URI. |
If you have a requirement to build paths to include in your responses you can use UriTemplate to do so.
URI Path Variables
URI variables can be referenced via method arguments. For example:
URI Variables Example
import io.micronaut.http.annotation.*;
@Controller("/issues") (1)
public class IssuesController {
@Get("/{number}") (2)
String issue(Integer number) {
return "Issue # " + number + "!"; (3)
}
}| 1 | The @Controller annotation is specified without an argument resulting in a base URI of /issues |
| 2 | The Get annotation is used to map the method to an HTTP GET with a URI variable embedded in the URI called number |
| 3 | The value of the URI variable is referenced in the implementation |
Micronaut will map the URI /issues/{number} for the above controller. We can assert this is the case by writing a unit test, this time in Java and JUnit:
Testing URI Variables
import io.micronaut.context.ApplicationContext;
import io.micronaut.http.client.HttpClient;
import org.junit.*;
import io.micronaut.runtime.server.EmbeddedServer;
import static org.junit.Assert.*;
public class IssuesControllerTest {
private static EmbeddedServer server;
private static HttpClient client;
@BeforeClass (1)
public static void setupServer() {
server = ApplicationContext.run(EmbeddedServer.class);
client = server
.getApplicationContext()
.createBean(HttpClient.class, server.getURL());
}
@AfterClass (1)
public static void stopServer() {
if(server != null) {
server.stop();
}
if(client != null) {
client.stop();
}
}
@Test
public void testIssue() throws Exception {
String body = client.toBlocking().retrieve("/issues/12"); (2)
assertNotNull(body);
assertEquals( (3)
body,
"Issue # 12!"
);
}
}| 1 | For JUnit you can write methods to start and stop the server for the scope of the test |
| 2 | The tests sends a request to the URI /issues/12 |
| 3 | And then asserts the response is "Issue # 12" |
If you invoke the previous endpoint without the required URI variable or with an invalid type, Micronaut responds with the appropriate HTTP failure codes as illustrated in the following Spock tests that use the HTTP client.
Testing for Response Errors
void "/issues/show/{number} with an invalid Integer number responds 400"() {
when:
client.toBlocking().exchange("/issues/hello")
then:
HttpClientResponseException e = thrown(HttpClientResponseException)
e.status.code == 400
}
void "/issues/show/{number} without number responds 404"() {
when:
client.toBlocking().exchange("/issues/")
then:
HttpClientResponseException e = thrown(HttpClientResponseException)
e.status.code == 404
}Note that the URI template in the previous example requires that the number variable is specified. You can specify optional URI templates with the syntax: /issues{/number} and by annotating the number parameter with @Nullable.
The following table provides some examples of URI templates and what they match:
| Template | Description | Matching URI |
|---|---|---|
|
Simple match |
|
|
A variable of 2 characters max |
|
|
An optional URI variable |
|
|
An optional URI variable with regex |
|
|
Optional query parameters |
|
|
Regex path match with extension |
|
URI Reserved Character Matching
By default URI variables as defined by the RFC-6570 URI template spec cannot include reserved characters such as /, ? etc.
If you wish to match or expand entire paths then this can be problematic. As per section 3.2.3 of the specification, you can use reserved expansion or matching using the + operator.
For example the URI /books/{+path} will match both /books/foo and /books/foo/bar since the + indicates that the variable path should include reserved characters (in this case /).
Routing Annotations
Building Routes Programmatically
If you prefer to not use annotations and declare all of your routes in code then never fear, Micronaut has a flexible RouteBuilder API that makes it a breeze to define routes programmatically.
To start off with you should subclass DefaultRouteBuilder and then simply inject the controller you wish to route to into the method and define your routes:
RouteBuilder Example
import io.micronaut.context.ExecutionHandleLocator;
import io.micronaut.web.router.DefaultRouteBuilder;
import javax.inject.*;
@Singleton
public class MyRoutes extends DefaultRouteBuilder { (1)
public MyRoutes(ExecutionHandleLocator executionHandleLocator, UriNamingStrategy uriNamingStrategy) {
super(executionHandleLocator, uriNamingStrategy);
}
@Inject
void issuesRoutes(IssuesController issuesController) { (2)
GET("/show/{name}", issuesController, "issue", Integer.class); (3)
}
}| 1 | Route definitions should subclass DefaultRouteBuilder |
| 2 | Use @Inject to inject a method with the controllers you want to route to |
| 3 | Use methods such as GET to route to controller methods |
Unfortunately due to type erasure a Java method lambda reference cannot be used with the API. For Groovy there is a GroovyRouteBuilder class which can be subclassed that allows passing Groovy method references.
|
Route Compile Time Validation
Micronaut supports validating route arguments at compile time with the validation library. To get started simply add the validation dependency to your build:
build.gradle
annotationProcessor "io.micronaut:micronaut-validation" // Java only
kapt "io.micronaut:micronaut-validation" // Kotlin only
compile "io.micronaut:micronaut-validation"With the correct dependency on your classpath, route arguments will automatically be checked at compile time. The compilation will fail if any of the following conditions are met:
-
The URI template contains a variable that is optional, but the method parameter is not annotated with
@Nullableor is anjava.util.Optional.
An optional variable is one that will allow the route to match a URI even if the value is not present. For example /foo{/bar} will match requests to /foo and /foo/abc. The non optional variant would be /foo/{bar}. See the URI Path Variables section for more information.
-
The URI template contains a variable that is missing from the method arguments.
To disable route compile time validation, set the system property -Dmicronaut.route.validation=false. For Java and Kotlin users using Gradle, the same effect can be achieved by removing the validation dependency from the annotationProcessor/kapt scope.
|
6.4 Simple Request Binding
The examples in the previous section demonstrates how Micronaut allows you to bind method parameters from URI path variables.
Binding Annotations
You can customize the name of the variable bound with the @QueryValue annotation which accepts a value which is the name of the URI variable or request parameter to bind from.
Also, in order to bind all request URI variables or request parameters to a command object, you can define URI route variable as ?pojo*. For example:
Binding Request parameters to POJO
import io.micronaut.http.HttpStatus;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Get;
import io.micronaut.validation.Validated;
import javax.annotation.Nullable;
import javax.validation.Valid;
@Controller("/api")
@Validated
public class BookmarkController {
@Get("/bookmarks/list{?paginationCommand*}")
public HttpStatus list(@Valid @Nullable PaginationCommand paginationCommand) {
return HttpStatus.OK;
}In addition, there are other annotations within the io.micronaut.http.annotation package to bind from different sources.
The following table summarizes the annotations, their purpose and provides an example:
| Annotation | Description | Example |
|---|---|---|
Allows to specify the parameter the body of the request should bind to |
|
|
Binds a parameter from a Cookie |
|
|
Binds a parameter from an HTTP header |
|
|
Bindings from a request URI variable or request parameter |
|
When a value is not specified to any binding annotation then the parameter name is used. In other words the following two methods are equivalent and both bind from a cookie called myCookie:
String hello(@CookieValue("myCookie") String myCookie) {
...
}
String hello(@CookieValue String myCookie) {
...
}Since Java doesn’t allow hyphens in variable names in the case of headers the following two definitions are equivalent:
public String hello(@Header("Content-Type") String contentType) {
...
}
public String hello(@Header String contentType) {
...
}Bindable Types
Generally any type that can be converted from a String representation to a Java type via the ConversionService API can be bound to.
This includes most common Java types, however additional TypeConverter instances can be registered simply be creating @Singleton beans of type TypeConverter.
The handling of Optional deserves special mention. Consider for example the following example:
public String hello(@Header String contentType) {
...
}In this case if the HTTP header Content-Type is not present in the request the route is considered invalid, since it cannot be satisfied and a HTTP 400 BAD REQUEST is returned.
If you wish for the Content-Type header to be optional, you can instead write:
public String hello(@Header Optional<String> contentType) {
...
}An empty Optional will be passed if the header is absent from the request.
Additionally, any DateTime that conforms to RFC-1123 can be bound to a parameter, alternatively the format can be customized with the Format annotation:
public String hello(@Header ZonedDateTime date) {
...
}
public String hello(@Format('dd/MM/yyy') @Header ZonedDateTime date) {
...
}Variables resolution
Micronaut will try to populate method arguments in the following order:
-
URI variables like
/{id}. -
If the request is a
GETrequest from query parameters (ie.?foo=bar). -
If there is a
@Bodyand request allows the body, bind the body to it. -
if the request can have a body and no
@Bodyis defined then try parse the body (either JSON or form data) and bind the method arguments from the body. -
Finally, if the method arguments cannot be populated return
400 BAD REQUEST.
6.5 The HttpRequest and HttpResponse
If you need more control over request processing then you can instead write a method that receives the complete HttpRequest.
In fact, there are several higher level interfaces that can be bound to method parameters of controllers. These include:
| Interface | Description | Example |
|---|---|---|
The full |
|
|
All HTTP headers present in the request |
|
|
All HTTP parameters (either from URI variables or request parameters) present in the request |
|
|
All the Cookies present in the request |
|
In addition, for full control over the emitted HTTP response you can use the static factory methods of the HttpResponse class which return a MutableHttpResponse.
The following example implements the previous MessageController example using the HttpRequest and HttpResponse objects:
Request and Response Example
import io.micronaut.http.*;
import io.micronaut.http.annotation.*;
import static io.micronaut.http.HttpResponse.*; (1)
@Controller("/request")
public class MessageController {
@Get("/hello") (2)
HttpResponse<String> hello(HttpRequest<?> request) {
String name = request.getParameters()
.getFirst("name")
.orElse("Nobody"); (3)
return ok("Hello " + name + "!!")
.header("X-My-Header", "Foo"); (4)
}
}| 1 | The factory methods of the HttpResponse are statically imported |
| 2 | The method is mapped to the URI /hello and accepts a HttpRequest |
| 3 | The HttpRequest is used to obtain the value of a query parameter called name. |
| 4 | The HttpResponse.ok(T) method is used to return a MutableHttpResponse with a text body. A header called X-My-Header is also added to the response object. |
6.6 Response Content-Type
A Micronaut’s controller action produces application-json by default.
Nonetheless you can change the Content-Type of the response with the @Produces annotation.
@Controller("/test")
public class TestController {
@Get
public HttpResponse index() {
return HttpResponse.ok().body("{\"msg\":\"This is JSON\"}");
}
@Produces(MediaType.TEXT_HTML) (1)
@Get("/html")
public String html() {
return "<html><title><h1>HTML</h1></title><body></body></html>";
}
}| 1 | Annotate a controller’s action with @Produces to change the response content type. |
6.7 Accepted Request Content-Type
A Micronaut’s controller action consumes application-json by default. Nonetheless, you can support other Content-Type with the @Consumes annotation.
@Controller("/test")
public class TestController {
@Consumes([MediaType.APPLICATION_FORM_URLENCODED, MediaType.APPLICATION_JSON]) (1)
@Post("/multiple-consumes")
public HttpResponse multipleConsumes() {
return HttpResponse.ok();
}
@Post (2)
public HttpResponse index() {
return HttpResponse.ok();
}
}| 1 | @Consumes annotation takes a String[] of supported media types for an incoming request. |
| 2 | By default, a controller’s action consumes request with Content-Type of type application-json. |
Customizing Processed Content Types
Normally the JSON parsing only happens if the content type is application-json. The other MediaTypeCodec classes behave in a similar manner that they have pre-defined content types they can process. To extend the list of media types that a given codec should process, you can provide configuration that will be stored in CodecConfiguration:
micronaut:
codec:
json:
additionalTypes:
- text/javascript
- ...Currently supported configuration prefixes are json, json-stream, text, and text-stream.
6.8 Reactive HTTP Request Processing
As mentioned previously, Micronaut is built on Netty which is designed around an Event loop model and non-blocking I/O.
Although it is recommended to following a non-blocking approach, in particular when making remote calls to other microservices, Micronaut acknowledges the fact that in real world scenarios developers encounter situations where the need arises to interface with blocking APIs and in order to facilitate this features blocking operation detection.
If your controller method returns a non-blocking type such as an RxJava Observable or a CompletableFuture then Micronaut will use the Event loop thread to subscribe to the result.
If however you return any other type then Micronaut will execute your @Controller method in a preconfigured I/O thread pool.
This thread pool by default is a caching, unbound thread pool. However, you may wish to configure the nature of the thread pool. For example the following configuration will configure the I/O thread pool as a fixed thread pool with 75 threads (similar to what a traditional blocking server such as Tomcat uses in the thread per connection model):
micronaut.executors.io.type=fixed
micronaut.executors.io.nThreads=756.8.1 Using the @Body Annotation
To parse the request body, you first need to indicate to Micronaut the parameter which will receive the data. This is done with the Body annotation.
The following example implements a simple echo server that echos the body sent in the request:
Using the @Body annotation
import io.reactivex.Flowable;
import io.reactivex.Single;
import io.micronaut.http.*;
import io.micronaut.http.annotation.*;
import javax.validation.constraints.Size;
@Controller("/receive")
public class MessageController {
@Post(value = "/echo", consumes = MediaType.TEXT_PLAIN) (1)
String echo(@Size(max = 1024) @Body String text) { (2)
return text; (3)
}
}| 1 | The Post annotation is used with a MediaType of text/plain (the default is application/json). |
| 2 | The Body annotation is used with a javax.validation.constraints.Size that limits the size of the body to at most 1MB |
| 3 | The body is returned as the result of the method |
Note that reading the request body is done in a non-blocking manner in that the request contents are read as the data becomes available and accumulated into the String passed to the method.
The micronaut.server.maxRequestSize setting in application.yml will limit the size of the data (the default maximum request size is 10MB) if no @Size constraint is specified.
|
Regardless of the limit, for a large amount of data accumulating the data into a String in-memory may lead to memory strain on the server. A better approach is to include a Reactive library in your project (such as RxJava 2.x, Reactor or Akka) that supports the Reactive streams implementation and stream the data it becomes available:
Using RxJava 2 to Read the request body
@Post(value = "/echo-flow", consumes = MediaType.TEXT_PLAIN) (1)
Single<MutableHttpResponse<String>> echoFlow(@Body Flowable<String> text) { (2)
return text.collect(StringBuffer::new, StringBuffer::append) (3)
.map(buffer ->
HttpResponse.ok(buffer.toString())
);
}| 1 | In this case the method is altered to receive and return an RxJava 2.x Flowable type |
| 2 | A Single is returned so that Micronaut will only emit the response once the operation completes without blocking. |
| 3 | The collect method is used to accumulate the data in this simulated example, but it could for example write the data to logging service, database or whatever chunk by chunk |
6.8.2 Reactive Responses
The previous section introduced the notion of Reactive programming using RxJava 2.x and Micronaut.
Micronaut supports returning common reactive types such as Single or Observable (or the Mono type from Reactor 3.x), an instance of Publisher or CompletableFuture from any controller method.
The argument that is designated the body of the request using the Body annotation can also be a reactive type or a CompletableFuture.
Micronaut also uses these types to influence which thread pool to execute the method on. If the request is considered non-blocking (because it returns a non-blocking type) then the Netty event loop thread will be used to execute the method.
If the method is considered blocking then the method is executed on the I/O thread pool, which Micronaut creates at startup.
| See the section on Configuring Thread Pools for information on the thread pools that Micronaut sets up and how to configure them. |
To summarize, the following table illustrates some common response types and their handling:
| Type | Description | Example Signature |
|---|---|---|
Any type that implements the Publisher interface |
|
|
A Java |
|
|
An HttpResponse and optional response body |
|
|
Any implementation of |
|
|
T |
Any simple POJO type |
|
When returning a Reactive type, the type of reactive type has an impact on the response returned. For example, when returning a Flowable, Micronaut can not know the size of the response, so Transfer-Encoding type of Chunked is used. Whilst for types that emit a single result such as Single the Content-Length header will be populated.
|
6.9 JSON Binding with Jackson
The most common data interchange format nowadays is JSON.
In fact, the defaults in the Controller annotation specify that the controllers in Micronaut consume and produce JSON by default.
In order to do so in a non-blocking manner Micronaut builds on the Jackson Asynchronous JSON parsing API and Netty such that the reading of incoming JSON is done in a non-blocking manner.
Binding using Reactive Frameworks
From a developer perspective however, you can generally just work with Plain Old Java Objects (POJOs) and can optionally use a Reactive framework such as RxJava or Reactor. The following is an example of a controller that reads and saves an incoming POJO in a non-blocking way from JSON:
Using RxJava 2 to Read the JSON
@Controller("/people")
public class PersonController {
Map<String, Person> inMemoryDatastore = new LinkedHashMap<>();
@Post
public Single<HttpResponse<Person>> save(@Body Single<Person> person) { (1)
return person.map(p -> {
inMemoryDatastore.put(p.getFirstName(), p); (2)
return HttpResponse.created(p); (3)
}
);
}
}| 1 | The method receives a RxJava Single which emits the POJO once the JSON has been read |
| 2 | The map method is used to store the instance in Map |
| 3 | An HttpResponse is returned |
Using CURL from the command line you can POST JSON to the /people URI for the server to receive it:
Using CURL to Post JSON
$ curl -X POST localhost:8080/people -d '{"firstName":"Fred","lastName":"Flintstone","age":45}'
Binding Using CompletableFuture
The same method as the previous example can also be written with the CompletableFuture API instead:
Using CompletableFuture to Read the JSON
public CompletableFuture<HttpResponse<Person>> save(@Body CompletableFuture<Person> person) {
return person.thenApply(p -> {
inMemoryDatastore.put(p.getFirstName(), p);
return HttpResponse.created(p);
}
);
}The above example uses the thenApply method to achieve the same as the previous example.
Binding using POJOs
Note however, that if your method does not do any blocking I/O then you can just as easily write:
Binding JSON POJOs
public HttpResponse<Person> save(@Body Person person) {
inMemoryDatastore.put(person.getFirstName(), person);
return HttpResponse.created(person);
}Micronaut will still using non-blocking I/O to read the JSON and only execute your method once the data has been read.
In other words, as a rule reactive types should be used when you plan to do further downstream I/O operations in which case they can greatly simplify composing operations.
| The output produced by Jackson can be customized in a variety of manners, from defining Jackson modules to using Jackson’s annotations |
Jackson Configuration
The Jackson ObjectMapper can be configured through normal configuration with the JacksonConfiguration class.
All jackson configuration keys start with jackson.
dateFormat |
String |
The date format |
locale |
String |
Uses Locale.forLanguageTag. Example: |
timeZone |
String |
Uses TimeZone.getTimeZone. Example: 'PST` |
serializationInclusion |
String |
One of JsonInclude.Include |
Features
All features can be configured with their name as the key and a boolean to indicate enabled or disabled.
serialization |
Map |
|
deserialization |
Map |
|
mapper |
Map |
|
parser |
Map |
|
generator |
Map |
Example:
jackson:
serialization:
indentOutput: true
writeDatesAsTimestamps: false
deserialization:
useBigIntegerForInts: true
failOnUnknownProperties: falseBeans
In addition to configuration, beans can be registered to customize Jackson. All beans that extend any of the following classes will be registered with the object mapper.
6.10 Data Validation
It is easy to validate incoming data with Micronaut’s controllers with the Validation Advice.
First, add the Hibernate Validator configuration to your application:
build.gradle
compile "io.micronaut.configuration:micronaut-hibernate-validator"We can validate parameters using javax.validation annotations and the Validated annotation at the class level.
import io.micronaut.http.HttpResponse;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Get;
import io.micronaut.validation.Validated;
import javax.validation.constraints.NotBlank;
import java.util.Collections;
@Validated (1)
@Controller("/email")
public class EmailController {
@Get("/send")
public HttpResponse send(@NotBlank String recipient, (2)
@NotBlank String subject) { (2)
return HttpResponse.ok(Collections.singletonMap("msg", "OK"));
}
}| 1 | Annotate controller with Validated |
| 2 | subject and recipient cannot be blank. |
The validation behaviour is shown in the following test:
def "invoking /email/send validates parameters"() {
when:
client.toBlocking().retrieve('/email/send?subject=Hi&recipient=')
then:
def e = thrown(HttpClientResponseException)
when:
def response = e.response
then:
response.status == HttpStatus.BAD_REQUEST
when:
client.toBlocking().retrieve('/email/send?subject=Hi&recipient=me@micronaut.example')
then:
noExceptionThrown()
}Often, you may want to use POJOs as controller method parameters.
package io.micronaut.docs.datavalidation.pogo;
import javax.validation.constraints.NotBlank;
public class Email {
@NotBlank (1)
String subject;
@NotBlank (1)
String recipient;
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public String getRecipient() {
return recipient;
}
public void setRecipient(String recipient) {
this.recipient = recipient;
}
}| 1 | You can use javax.validation annotations in your POJOs. |
You need to annotate your controller with Validated. Also, you need to annotate the binding POJO with @Valid.
Example
import io.micronaut.http.HttpResponse;
import io.micronaut.http.annotation.Body;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Post;
import io.micronaut.validation.Validated;
import javax.validation.Valid;
import java.util.Collections;
@Validated (1)
@Controller("/email")
public class EmailController {
@Post("/send")
public HttpResponse send(@Body @Valid Email email) { (2)
return HttpResponse.ok(Collections.singletonMap("msg", "OK")); }
}| 1 | Annotate controller with Validated |
| 2 | Annotate the POJO which you wish to validate with @Valid |
The validation of POJOs is shown in the following test:
def "invoking /email/send parse parameters in a POJO and validates"() {
when:
Email email = new Email()
email.subject = 'Hi'
email.recipient = ''
client.toBlocking().exchange(HttpRequest.POST('/email/send', email))
then:
def e = thrown(HttpClientResponseException)
when:
def response = e.response
then:
response.status == HttpStatus.BAD_REQUEST
when:
email = new Email()
email.subject = 'Hi'
email.recipient = 'me@micronaut.example'
client.toBlocking().exchange(HttpRequest.POST('/email/send', email))
then:
noExceptionThrown()
}6.11 Serving Static Resources
Static resource resolution is disabled by default. Micronaut supports resolving resources from the classpath or the file system.
See the information below for available configuration options:
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets whether this specific mapping is enabled. Default value (true). |
|
java.util.List |
A list of paths either starting with |
|
java.lang.String |
The path resources should be served from. Uses ant path matching. Default value ("/**"). |
6.12 Error Handling
Sometimes with distributing applications, bad things happen. Thus having a good way to handle errors is important.
Status Handlers
The Error annotation supports defining either an exception class or an HTTP status. Methods decorated with the annotation will be invoked as the result of other controller methods. The annotation also supports the notion of global and local, local being the default.
Local error handlers will only respond to methods defined in the same controller. Global error handlers can respond to any method in any controller. A local error handler is always searched for first when resolving which handler to execute.
| When defining an error handler for an exception, you can specify the exception instance as an argument to the method and omit the exception property of the annotation. |
Local Error Handling
For example the following method will handling JSON parse exceptions from Jackson for the scope of the declaring controller:
Local exception handler
@Error
public HttpResponse<JsonError> jsonError(HttpRequest request, JsonParseException jsonParseException) { (1)
JsonError error = new JsonError("Invalid JSON: " + jsonParseException.getMessage()) (2)
.link(Link.SELF, Link.of(request.getUri()));
return HttpResponse.<JsonError>status(HttpStatus.BAD_REQUEST, "Fix Your JSON")
.body(error); (3)
}| 1 | A method that explicitly handles JsonParseException is declared |
| 2 | An instance of JsonError is returned. |
| 3 | A custom response is returned to handle the error |
Local status handler
@Error(status = HttpStatus.NOT_FOUND)
public HttpResponse<JsonError> notFound(HttpRequest request) { (1)
JsonError error = new JsonError("Page Not Found") (2)
.link(Link.SELF, Link.of(request.getUri()));
return HttpResponse.<JsonError>notFound()
.body(error); (3)
}| 1 | The Error declares which HttpStatus error code to handle (in this case 404) |
| 2 | A JsonError instance is returned for all 404 responses |
| 3 | An NOT_FOUND response is returned |
Global Error Handling
Global error handler
@Error(global = true) (1)
public HttpResponse<JsonError> error(HttpRequest request, Throwable e) {
JsonError error = new JsonError("Bad Things Happened: " + e.getMessage()) (2)
.link(Link.SELF, Link.of(request.getUri()));
return HttpResponse.<JsonError>serverError()
.body(error); (3)
}| 1 | The Error is used to declare the method a global error handler |
| 2 | A JsonError instance is returned for all errors |
| 3 | An INTERNAL_SERVER_ERROR response is returned |
Global status handler
@Error(status = HttpStatus.NOT_FOUND, global = true)
public HttpResponse<JsonError> notFound(HttpRequest request) { (1)
JsonError error = new JsonError("Page Not Found") (2)
.link(Link.SELF, Link.of(request.getUri()));
return HttpResponse.<JsonError>notFound()
.body(error); (3)
}| 1 | The Error declares which HttpStatus error code to handle (in this case 404) |
| 2 | A JsonError instance is returned for all 404 responses |
| 3 | An NOT_FOUND response is returned |
A few things to note about the Error annotation. Two identical @Error annotations that are
global cannot be declared. Two identical @Error annotations that are non-global cannot be declared in the same controller.
If an @Error annotation with the same parameter exists as global and another as a local, the local one will take precedence.
|
ExceptionHandler
Additionally you can implement a ExceptionHandler; a generic hook for handling exceptions that occurs during the execution of an HTTP request.
Imagine your e-commerce app throws an OutOfStockException when a book is out of stock:
public class OutOfStockException extends RuntimeException {
}@Controller("/books")
public class BookController {
@Produces(MediaType.TEXT_PLAIN)
@Get("/stock/{isbn}")
Integer stock(String isbn) {
throw new OutOfStockException();
}
}If you don’t handle the exception the server returns a 500 (Internal Server Error) status code.
If you want to respond 200 OK with 0 (stock level) as the response body when the OutOfStockException is thrown, you could register a ExceptionHandler:
@Produces
@Singleton
@Requires(classes = {OutOfStockException.class, ExceptionHandler.class})
public class OutOfStockExceptionHandler implements ExceptionHandler<OutOfStockException, HttpResponse> {
@Override
public HttpResponse handle(HttpRequest request, OutOfStockException exception) {
return HttpResponse.ok(0);
}
}
An @Error annotation capturing an exception has precedence over an implementation of ExceptionHandler capturing the same exception.
|
6.13 Handling Form Data
In order to make data binding model customizations consistent between form data and JSON, Micronaut uses Jackson to implement binding data from form submissions.
The advantage of this approach is that the same Jackson annotations used for customizing JSON binding can be used for form submissions too.
What this means in practise is that in order to bind regular form data the only change required to the previous JSON binding code is updating the MediaType consumed:
Binding Form Data to POJOs
@Post(value = "/", consumes = MediaType.APPLICATION_FORM_URLENCODED)
public HttpResponse<Person> save(@Body Person person) {
inMemoryDatastore.put(person.getFirstName(), person);
return HttpResponse.created(person);
}
To avoid denial of service attacks, collection types and arrays created during binding are limited by the setting jackson.arraySizeThreshold in application.yml
|
Alternatively, instead of using a POJO you can bind form data directly to method parameters (which works with JSON too!):
Binding Form Data to Parameters
@Post(value = "/", consumes = MediaType.APPLICATION_FORM_URLENCODED)
public HttpResponse<Person> save(String firstName, String lastName, Optional<Integer> age) {
Person p = new Person(firstName, lastName);
age.ifPresent(p::setAge);
inMemoryDatastore.put(p.getFirstName(), p);
return HttpResponse.created(p);
}As you can see from the example above, this approach allows you to use features such as support for Optional types and restrict the parameters to be bound (When using POJOs you must be careful to use Jackson annotations to exclude properties that should not be bound).
6.14 Writing Response Data
Writing Data without Blocking
Micronaut’s HTTP server supports writing data without blocking simply by returning a Publisher the emits objects that can be encoded to the HTTP response.
The following table summarizes example return type signatures and the behaviour the server exhibits to handle each of them:
| Return Type | Description |
|---|---|
|
A Flowable that emits each chunk of content as a |
|
A Reactor |
|
A Publisher that emits each chunk of content as a String |
|
When emitting a POJO each emitted object is encoded as JSON by default without blocking |
When returning reactive type the server will use a Transfer-Encoding of chunked and keep writing data until the Publisher's onComplete method is called.
The server will request a single item from the Publisher, write the item, without blocking, and then request the next item, thus controlling back pressure.
Performing Blocking I/O
In some cases you may wish to integrate with a library that does not support non-blocking I/O.
In this you can return a Writable object from any controller method. The Writable has various signatures that allowing writing to traditional blocking streams like Writer or OutputStream.
When returning a Writable object the blocking I/O operation will be shifted to the I/O thread pool so that the Netty event loop is not blocked.
| See the section on configuring Server Thread Pools for details on how to configure the I/O thread pool to meet the requirements of your application. |
The following example demonstrates how to use this API with Groovy’s SimpleTemplateEngine to write a server side template:
Performing Blocking I/O
import groovy.text.SimpleTemplateEngine;
import groovy.text.Template;
import io.micronaut.core.io.Writable;
import io.micronaut.core.util.CollectionUtils;
import io.micronaut.http.MediaType;
import io.micronaut.http.annotation.*;
import io.micronaut.http.server.exceptions.HttpServerException;
@Controller("/template")
public class TemplateController {
private final SimpleTemplateEngine templateEngine = new SimpleTemplateEngine();
private final Template template;
public TemplateController() {
template = initTemplate(); (1)
}
@Get(value = "/welcome", produces = MediaType.TEXT_PLAIN)
Writable render() { (2)
return writer -> template.make( (3)
CollectionUtils.mapOf(
"firstName", "Fred",
"lastName", "Flintstone"
)
).writeTo(writer);
}
private Template initTemplate() {
Template template;
try {
template = templateEngine.createTemplate(
"Dear $firstName $lastName. Nice to meet you."
);
} catch (Exception e) {
throw new HttpServerException("Cannot create template");
}
return template;
}
}404 Responses
Often, you want to respond 404 (Not Found) when you don’t find an item in your persistence layer or in similar scenarios.
See the following example:
@Controller("/books")
public class BooksController {
@Get("/stock/{isbn}")
public Map stock(String isbn) {
return null; (1)
}
@Get("/maybestock/{isbn}")
public Maybe<Map> maybestock(String isbn) {
return Maybe.empty(); (2)
}
}| 1 | Returning null triggers a 404 (Not Found) response. |
| 2 | Returning an empty Maybe triggers a 404 (Not Found) response. |
Responding with an empty Publisher or Flowable will result in an empty array being returned if the content type is JSON.
|
6.15 File Uploads
Handling of file uploads has special treatment in Micronaut. Support is provided for streaming of uploads in a non-blocking manner through streaming uploads or completed uploads.
To receive data from a multipart request, set the consumes argument of the method annotation to MULTIPART_FORM_DATA. For example:
@Post(consumes = MediaType.MULTIPART_FORM_DATA)
HttpResponse upload( ... )Route Arguments
How the files are received by your method is determined by the type of the arguments. Data can be received a chunk at a time or when an upload is completed.
| If the route argument name can’t or shouldn’t match the name of the part in the request, simply add the @Part annotation to the argument and specify the name that is expected to be in the request. |
Chunk Data Types
PartData is the data type used to represent a chunk of data received in a multipart request. There are methods on the PartData interface to convert the data to a byte[], InputStream, or a ByteBuffer.
| Data can only be retrieved from a PartData once. The underlying buffer will be released which causes further attempts to fail. |
Route arguments of type Publisher<PartData> will be treated as only intended to receive a single file and each chunk of the received file will be sent downstream. If the generic type is something other than PartData, conversion will be attempted using Micronaut’s conversion service. Conversions to String and byte[] are supported by default.
If requirements dictate you must have knowledge about the metadata of the file being received, a special class called StreamingFileUpload has been created that is a Publisher<PartData>, but also has file information like the content type and file name.
import io.micronaut.http.*;
import io.micronaut.http.annotation.*;
import io.micronaut.http.multipart.StreamingFileUpload;
import io.reactivex.Single;
import org.reactivestreams.Publisher;
import java.io.File;
@Controller("/upload")
public class UploadController {
@Post(value = "/", consumes = MediaType.MULTIPART_FORM_DATA) (1)
public Single<HttpResponse<String>> upload(StreamingFileUpload file) throws IOException { (2)
File tempFile = File.createTempFile(file.getFilename(), "temp");
Publisher<Boolean> uploadPublisher = file.transferTo(tempFile); (3)
return Single.fromPublisher(uploadPublisher) (4)
.map(success -> {
if (success) {
return HttpResponse.ok("Uploaded");
} else {
return HttpResponse.<String>status(HttpStatus.CONFLICT)
.body("Upload Failed");
}
});
}
}| 1 | The method is set to consume MULTIPART_FORM_DATA |
| 2 | The method parameters match form attribute names. In this case the file will match for example an <input type="file" name="file"> |
| 3 | The StreamingFileUpload.transferTo(java.lang.String) method is used to transfer the file to the server. The method returns a Publisher |
| 4 | The returned Single subscribes to the Publisher and outputs a response once the upload is complete, without blocking. |
Whole Data Types
Route arguments that are not publishers will cause the route execution to be delayed until the upload has finished. The received data will attempt to be converted to the requested type. Conversions to a String or byte[] are supported by default. In addition, the file can be converted to a POJO if a media type codec has been registered that supports the media type of the file. A media type codec is included by default that allows conversion of JSON files to POJOs.
If requirements dictate you must have knowledge about the metadata of the file being received, a special class called CompletedFileUpload has been created that has methods to retrieve the data of the file, but also has file information like the content type and file name.
import io.micronaut.http.multipart.CompletedFileUpload;
import java.io.IOException;
import java.nio.file.*;
@Controller("/upload")
public class UploadController {
@Post(value = "/completed", consumes = MediaType.MULTIPART_FORM_DATA) (1)
public HttpResponse<String> uploadCompleted(CompletedFileUpload file) { (2)
try {
File tempFile = File.createTempFile(file.getFilename(), "temp"); (3)
Path path = Paths.get(tempFile.getAbsolutePath());
Files.write(path, file.getBytes()); (3)
return HttpResponse.ok("Uploaded");
} catch (IOException exception) {
return HttpResponse.badRequest("Upload Failed");
}
}
}| 1 | The method is set to consume MULTIPART_FORM_DATA |
| 2 | The method parameters match form attribute names. In this case the file will match for example an <input type="file" name="file"> |
| 3 | The CompletedFileUpload instance gives access to metadata about the upload as well as access to the file’s contents. |
Multiple Uploads
Different Names
If a multipart request supplies multiple uploads that each have a different part name, simply create an argument to your route that receives each part. For example:
HttpResponse upload(String title, String name)A route method signature like the above will expect 2 different parts with the names "title" and "name".
Same Name
To handle receiving multiple parts with the same part name, the argument must be a Publisher. When used in one of the following ways, the publisher will emit one item per file found with the specified name. The publisher must accept one of the following types:
-
Any POJO assuming a media codec is found that supports the content type
-
Another Publisher that accepts one of the chunked data types described above
For example:
HttpResponse upload(Publisher<StreamingFileUpload> files)
HttpResponse upload(Publisher<CompletedFileUpload> files)
HttpResponse upload(Publisher<MyObject> files)
HttpResponse upload(Publisher<Publisher<PartData>> files)6.16 File Transfers
Micronaut supports the sending of files to the client in a couple of easy ways.
Sending File Objects
It is possible to simply return a File object from your controller method and the data will be returned to the client.
For files that should be downloaded (i.e. using the Content-Disposition header) you should instead construct an AttachedFile with the file object and the name you would like to be used. For example:
Sending an AttachedFile
@Get
public AttachedFile download() {
File file = ...
return new AttachedFile(file, "myfile.txt");
}Sending an InputStream
For cases where a reference to a File object is not possible (for example resources contained within JAR files), Micronaut supports transferring of input streams. To return a stream of data from the controller method, construct a StreamedFile.
The constructor for StreamedFile also accepts a java.net.URL for your convenience.
|
Sending a StreamedFile
@Get
public StreamedFile download() {
InputStream inputStream = ...
return new StreamedFile(inputStream, "download.txt")
}
The Content-Type header of file responses will be calculated based on the name of the file.
|
The server supports returning 304 (Not Modified) responses if the files being transferred have not changed and the request contains the appropriate header. In addition, if the client accepts encoded responses, Micronaut will encode the file if it is deemed appropriate. Encoding will happen if the file is text based and greater than 1 kilobyte.
6.17 HTTP Filters
The Micronaut HTTP server supports the ability to apply filters to request/response processing in a similar, but reactive, way to Servlet filters in traditional Java applications.
Filters provide the ability to support the following use cases:
-
Decoration of the incoming HttpRequest
-
Modification of the outgoing HttpResponse
-
Implementation of cross cutting concerns such as security, tracing etc.
For a server application, the HttpServerFilter interface’s doFilter method can be implemented.
The doFilter method accepts the HttpRequest and an instance of ServerFilterChain.
The ServerFilterChain interface contains a resolved chain of filters with the final entry in the chain being the matched route. The ServerFilterChain.proceed(io.micronaut.http.HttpRequest) method can be used to resume processing of the request.
The proceed(..) method returns a Reactive Streams Publisher that emits the response that will be returned to the client. Implementors of filters can subscribe to the Publisher and mutate the emitted MutableHttpResponse object to modify the response prior to returning the response to the client.
To put these concepts into practise lets look at an example.
Writing a Filter
Consider a hypothetical use case whereby you wish to trace each request to the Micronaut "Hello World" example using some external system. The external system could be a database, a distributed tracing service and may require I/O operations.
What you don’t want to do is block the underlying Netty event loop within your filter, instead you want to the filter to proceed with execution once any I/O is complete.
As an example, consider the following example TraceService that uses RxJava to compose an I/O operation:
A TraceService Example using RxJava
import io.micronaut.http.HttpRequest;
import io.reactivex.Flowable;
import io.reactivex.schedulers.Schedulers;
import org.slf4j.*;
import javax.inject.Singleton;
@Singleton
public class TraceService {
private static final Logger LOG = LoggerFactory.getLogger(TraceService.class);
Flowable<Boolean> trace(HttpRequest<?> request) {
return Flowable.fromCallable(() -> { (1)
if (LOG.isDebugEnabled()) {
LOG.debug("Tracing request: " + request.getUri());
}
// trace logic here, potentially performing I/O (2)
return true;
}).subscribeOn(Schedulers.io()); (3)
}
}| 1 | The Flowable type is used to create logic that executes potentially blocking operations to write the trace data from the request |
| 2 | Since this is just an example the logic does nothing and a place holder comment is used |
| 3 | The RxJava I/O scheduler is used to execute the logic |
You can then inject this implementation into your filter definition:
An Example HttpServerFilter
import io.micronaut.http.*;
import io.micronaut.http.annotation.Filter;
import io.micronaut.http.filter.*;
import org.reactivestreams.Publisher;
@Filter("/hello/**") (1)
public class TraceFilter implements HttpServerFilter { (2)
private final TraceService traceService;
public TraceFilter(TraceService traceService) { (3)
this.traceService = traceService;
}
...
}| 1 | The Filter annotation is used to define the URI patterns the filter matches |
| 2 | The class implements the HttpServerFilter interface |
| 3 | The previously defined TraceService is injected via a constructor argument |
The final step is write the doFilter implementation of the HttpServerFilter interface.
The doFilter implementation
@Override
public Publisher<MutableHttpResponse<?>> doFilter(HttpRequest<?> request, ServerFilterChain chain) {
return traceService.trace(request) (1)
.switchMap(aBoolean -> chain.proceed(request)) (2)
.doOnNext(res -> (3)
res.getHeaders().add("X-Trace-Enabled", "true")
);
}| 1 | The previously defined TraceService is called to trace the request |
| 2 | If the trace call succeeds then the filter switches back to resuming the request processing using RxJava’s switchMap method, which invokes the proceed method of the ServerFilterChain |
| 3 | Finally, RxJava’s doOnNext method is used to add a header called X-Trace-Enabled to the response. |
The previous example demonstrates some key concepts such as executing logic in a non-blocking matter before proceeding with the request and modifying the outgoing response.
| The examples use RxJava, however you can use any reactive framework that supports the Reactive streams specifications |
6.18 HTTP Sessions
By default Micronaut is a stateless HTTP server, however depending on your application requirements you may need the notion of HTTP sessions.
Micronaut comes with a session module inspired by Spring Session that enables this that currently features two implementations:
-
In-Memory sessions - which you should combine with an a sticky sessions proxy if you plan to run multiple instances.
-
Redis sessions - In this case Redis is used to store sessions and non-blocking I/O is used to read/write sessions to Redis.
Enabling Sessions
To enable support for in-memory sessions you just need the session dependency:
build.gradle
compile "io.micronaut:micronaut-session"To enable sessions with Redis you must also have the redis-lettuce configuration on your classpath:
build.gradle
compile "io.micronaut:micronaut-session"
compile "io.micronaut.configuration:micronaut-redis-lettuce"And enable Redis sessions via configuration in application.yml:
Enabling Redis Sessions
redis:
uri: redis://localhost:6379
micronaut:
session:
http:
redis:
enabled: trueConfiguring Session Resolution
How the Session is resolved can be configured with HttpSessionConfiguration.
By default sessions are resolved using an HttpSessionFilter that looks up session identifiers via either an HTTP header (using the Authorization-Info or X-Auth-Token header values) or via a Cookie called SESSION.
If you wish to disable either header resolution or cookie resolution you can via configuration in application.yml:
Disabling Cookie Resolution
micronaut:
session:
http:
cookie: false
header: trueThe above configuration enables header resolution, but disables cookie resolution. You can also configure the header or cookie names as necessary.
Working with Sessions
A Session object can be retrieved simply by declaring the Session in a controller method signature. For example consider the following controller:
ShoppingController.java
import io.micronaut.http.annotation.*;
import io.micronaut.session.Session;
import io.micronaut.session.annotation.SessionValue;
import javax.annotation.Nullable;
import javax.validation.constraints.NotBlank;
@Controller("/shopping")
public class ShoppingController {
private static final String ATTR_CART = "cart"; (1)
@Post("/cart/{name}")
Cart addItem(Session session, @NotBlank String name) { (2)
Cart cart = session.get(ATTR_CART, Cart.class).orElseGet(() -> { (3)
Cart newCart = new Cart();
session.put(ATTR_CART, newCart); (4)
return newCart;
});
cart.getItems().add(name);
return cart;
}
}| 1 | The ShoppingController declares a Session attribute called cart |
| 2 | The Session is declared as a parameter to the method |
| 3 | The cart attribute is retrieved |
| 4 | Otherwise a new Cart instance is created and stored in the session |
Note that because the Session is declared as a required parameter to the execute the controller action, the Session will be created and saved to the SessionStore.
If you don’t want to create unnecessary sessions then you can declare the Session as @Nullable in which case a session will not be created and saved unnecessarily. For example:
Using @Nullable with Sessions
@Post("/cart/clear")
void clearCart(@Nullable Session session) {
if (session != null) {
session.remove(ATTR_CART);
}
}The above method will only create and inject a new Session if one already exists.
Session Clients
If the client is a web browser then sessions should just work if you have cookies is enabled. However for programmatic HTTP clients you need to make sure you propagate the session id between HTTP calls.
For example, when invoking the viewCart method of the StoreController in the previous example the HTTP client will receive by default a AUTHORIZATION_INFO header. The following example, using a Spock test, demonstrates this:
Retrieving the AUTHORIZATION_INFO header
when: "The shopping cart is retrieved"
HttpResponse<Cart> response = httpClient.exchange(HttpRequest.GET('/shopping/cart'), Cart) (1)
.blockingFirst()
Cart cart = response.body()
then: "The shopping cart is present as well as a session id header"
response.header(HttpHeaders.AUTHORIZATION_INFO) != null (2)
cart != null
cart.items.isEmpty()| 1 | A request is made to /shopping/cart |
| 2 | The AUTHORIZATION_INFO header is present in the response |
You can then pass this AUTHORIZATION_INFO in subsequent requests to re-use the existing Session:
Sending the AUTHORIZATION_INFO header
String sessionId = response.header(HttpHeaders.AUTHORIZATION_INFO) (1)
response = httpClient.exchange(
HttpRequest.POST('/shopping/cart/Apple', "")
.header(HttpHeaders.AUTHORIZATION_INFO, sessionId), Cart) (2)
.blockingFirst()
cart = response.body()| 1 | The AUTHORIZATION_INFO is retrieved from the response |
| 2 | And then sent as a header in the subsequent request |
Using @SessionValue
Rather than explicitly injecting the Session into a controller method you can instead use @SessionValue. For example:
Using @SessionValue
@Get("/cart")
@SessionValue(ATTR_CART) (1)
Cart viewCart(@SessionValue @Nullable Cart cart) { (2)
if (cart == null) {
cart = new Cart();
}
return cart;
}| 1 | @SessionValue is declared on the method resulting in the return value being stored in the Session. Note that you must specify the attribute name when used on a return value |
| 2 | @SessionValue is used on a @Nullable parameter which results in looking up the value from the Session in a non-blocking way and supplying it if present. In the case a value is not specified to @SessionValue resulting in the parameter name being used to lookup the attribute. |
Session Events
You can register ApplicationEventListener beans to listen for Session related events located in the io.micronaut.session.event package.
The following table summarizes the events:
| Type | Description |
|---|---|
Fired when a Session is created |
|
Fired when a Session is deleted |
|
Fired when a Session expires |
|
Parent of both |
Redis Sessions
Storing Session instances is Redis requires special considerations.
You can configure how sessions are stored in Redis using RedisHttpSessionConfiguration.
The following represents an example configuration in application.yml.
Configuring Redis Sessions
micronaut:
session:
http:
redis:
enabled: true
# The Redis namespace to write sessions to
namespace: 'myapp:sessions'
# Write session changes in the background
write-mode: BACKGROUND
# Disable programatic activation of keyspace events
enable-keyspace-events: false| The RedisSessionStore implementation uses keyspace events to cleanup active sessions and fire SessionExpiredEvent and requires they are active. |
By default sessions values are serialized using Java serialization and stored in Redis hashes. You can configure serialization to instead use Jackson to serialize to JSON if desired:
Using Jackson Serialization
micronaut:
session:
http:
redis:
enabled: true
valueSerializer: io.micronaut.jackson.serialize.JacksonObjectSerializer6.19 Server Sent Events
The Micronaut HTTP server supports emitting Server Sent Events (SSE) using the Event API.
To emit events from the server you simply return a Reactive Streams Publisher that emits objects of type Event.
The Publisher itself could publish events from a background task, via an event system or whatever.
Imagine for an example a event stream of news headlines, you may define a data class as follows:
Headline.java
public class Headline {
private String title;
private String description;
public Headline() { }
public Headline(String title, String description) {
this.title = title;
this.description = description;
}
public String getTitle() {
return title;
}
public String getDescription() {
return description;
}
public void setTitle(String title) {
this.title = title;
}
public void setDescription(String description) {
this.description = description;
}
}To emit news headline events you can write a controller that returns a Publisher of Event instances using which ever Reactive library you prefer. The example below uses RxJava 2’s Flowable via the generate method:
Publishing Server Sent Events from a Controller
import io.micronaut.http.annotation.*;
import io.micronaut.http.sse.Event;
import io.reactivex.Flowable;
import org.reactivestreams.Publisher;
@Controller("/headlines")
public class HeadlineController {
@Get
public Publisher<Event<Headline>> index() { (1)
String[] versions = new String[]{"1.0", "2.0"}; (2)
return Flowable.generate(() -> 0, (i, emitter) -> { (3)
if (i < versions.length) {
emitter.onNext( (4)
Event.of(new Headline("Micronaut " + versions[i] + " Released", "Come and get it"))
);
} else {
emitter.onComplete(); (5)
}
return ++i;
});
}
}| 1 | The controller method returns a Publisher of Event |
| 2 | For each version of Micronaut a headline is emitted |
| 3 | The Flowable type’s generate method is used to generate a Publisher. The generate method accepts an initial value and a lambda that accepts the value and a Emitter. Note that this example executes on the same thread as the controller action, but you could use subscribeOn or map and existing "hot" Flowable. |
| 4 | The Emitter interface’s onNext method is used to emit objects of type Event. The Event.of(ET) factory method is used to construct the event. |
| 5 | The Emitter interface’s onComplete method is used to indicate when to finish sending server sent events. |
The above example will send back a response of type text/event-stream and for each Event emitted the Headline type previously will be converted to JSON resulting in responses such as:
Server Sent Event Response Output
data: {"title":"Micronaut 1.0 Released","description":"Come and get it"}
data: {"title":"Micronaut 2.0 Released","description":"Come and get it"}You can use the methods of the Event interface to customize the Server Sent Event data sent back including associating event ids, comments, retry timeouts etc.
6.20 WebSocket Support
Micronaut features dedicated support for creating WebSocket clients and servers. The io.micronaut.websocket.annotation package includes a set of annotations for defining both clients and servers.
6.20.1 Using @ServerWebSocket
The @ServerWebSocket annotation can be applied to any class that should map to a WebSocket URI. The following example is a simple chat WebSocket implementation:
WebSocket Chat Example
package io.micronaut.http.server.netty.websocket;
import io.micronaut.websocket.WebSocketBroadcaster;
import io.micronaut.websocket.WebSocketSession;
import io.micronaut.websocket.annotation.*;
import java.util.function.Predicate;
@ServerWebSocket("/chat/{topic}/{username}") (1)
public class ChatServerWebSocket {
private WebSocketBroadcaster broadcaster;
public ChatServerWebSocket(WebSocketBroadcaster broadcaster) {
this.broadcaster = broadcaster;
}
@OnOpen (2)
public void onOpen(String topic, String username, WebSocketSession session) {
String msg = "[" + username + "] Joined!";
broadcaster.broadcastSync(msg, isValid(topic, session));
}
@OnMessage (3)
public void onMessage(
String topic,
String username,
String message,
WebSocketSession session) {
String msg = "[" + username + "] " + message;
broadcaster.broadcastSync(msg, isValid(topic, session)); (4)
}
@OnClose (5)
public void onClose(
String topic,
String username,
WebSocketSession session) {
String msg = "[" + username + "] Disconnected!";
broadcaster.broadcastSync(msg, isValid(topic, session));
}
private Predicate<WebSocketSession> isValid(String topic, WebSocketSession session) {
return s -> s != session && topic.equalsIgnoreCase(s.getUriVariables().get("topic", String.class, null));
}
}| 1 | The @ServerWebSocket annotation is used to define the path the WebSocket is mapped under. The URI can be a URI template. |
| 2 | The @OnOpen annotation is used to declare a method that is invoked when the WebSocket is opened. |
| 3 | The @OnMessage annotation is used to declare a method that is invoked when a message is received. |
| 4 | You can use a WebSocketBroadcaster to broadcast messages to every WebSocket session. You can filter which sessions to communicate with a Predicate. Also, you could use the passed WebSocketSession instance to send a message to it with WebSocketSession::send. |
| 5 | The @OnClose annotation is used to declare a method that is invoked when the WebSocket is closed. |
| A working example of WebSockets in action can be found in the Micronaut Examples GitHub repository. |
In terms of binding the method arguments to each WebSocket method can be:
-
A variable from the URI template (in the above example
topicandusernameare variables in the URI template) -
An instance of WebSocketSession
The @OnClose Method
The @OnClose method can also optionally receive a CloseReason. The @OnClose method is invoked prior to the session closing.
The @OnMessage Method
The @OnMessage method can define a parameter that is the message body. The parameter can be one of the following:
-
A Netty
WebSocketFrame -
Any Java primitive or simple type (such as
String). In fact any type that can be converted fromByteBuf(you can register additional TypeConverter beans if you wish to support a custom type). -
A
byte[], aByteBufor a Java NIOByteBuffer. -
A Plain Old Java Object (POJO). In the case of a POJO the POJO will be decoded by default as JSON using JsonMediaTypeCodec. You can register a custom codec if necessary and define the content type of the handler using the @Consumes annotation.
The @OnError Method
A method annotated with @OnError can be added to implement custom error handling. The @OnError method can optionally define a parameter that receives the exception type that is to be handled. If no @OnError handling is present and a unrecoverable exception occurs the WebSocket is automatically closed.
Non-Blocking Message Handling
The previous example uses the broadcastSync method of the WebSocketSession interface which blocks until the broadcast is complete. You can however implement non-blocking WebSocket servers by instead returning a Publisher or a Future from each WebSocket handler method. For example:
WebSocket Chat Example
@OnMessage
public Publisher<Message> onMessage(
String topic,
String username,
Message message,
WebSocketSession session) {
String text = "[" + username + "] " + message.getText();
Message newMessage = new Message(text);
return broadcaster.broadcast(newMessage, isValid(topic, session));
}@ServerWebSocket and Scopes
By default a unique @ServerWebSocket instance is created for each WebSocket connection. This allows you to retrieve the WebSocketSession from the @OnOpen handler and assign it to a field of the @ServerWebSocket instance.
If you define the @ServerWebSocket as @Singleton it should be noted that extra care will need to be taken to synchronize local state to avoid thread safety issues.
Sharing Sessions with the HTTP Session
The WebSocketSession is by default backed by an in-memory map. If you add the the session module you can however share sessions between the HTTP server and the WebSocket server.
| When sessions are backed by a persistent store such as Redis then after each message is processed the session is updated to the backing store. |
|
Using the CLI
If you have created your project using the Micronaut CLI and the default ( $ mn create-websocket-server MyChat | Rendered template WebsocketServer.java to destination src/main/java/example/MyChatServer.java |
Connection Timeouts
By default Micronaut will timeout idle connections that have no activity after 5 minutes. Normally this is not a problem as browsers will automatically reconnect WebSocket sessions, however you can control this behaviour by setting the micronaut.server.idle-timeout setting (a negative value will result no timeout):
Setting the Connection Timeout for the Server
micronaut:
server:
idle-timeout: 30m # 30 minutesIf you are using Micronaut’s WebSocket client then you may also wish to set the timeout on the client:
Setting the Connection Timeout for the Client
micronaut:
http:
client:
read-idle-timeout: 30m # 30 minutes6.20.2 Using @ClientWebSocket
The @ClientWebSocket annotation can be used in combination with the WebSocketClient interface to define WebSocket clients.
You can inject a reference to the a WebSocketClient instance using the @Client annotation:
@Inject
@Client("http://localhost:8080")
RxWebSocketClient webSocketClient;This allows you to use the same service discovery and load balancing features for WebSocket clients.
Once you have a reference to the WebSocketClient interface you can use the connect method to obtain a connected instance of a bean annotated with @ClientWebSocket.
For example consider the following implementation:
WebSocket Chat Example
import io.micronaut.websocket.WebSocketSession;
import io.micronaut.websocket.annotation.*;
import io.reactivex.Single;
import java.util.Collection;
import java.util.concurrent.ConcurrentLinkedQueue;
@ClientWebSocket("/chat/{topic}/{username}") (1)
public abstract class ChatClientWebSocket implements AutoCloseable { (2)
private WebSocketSession session;
private String topic;
private String username;
private Collection<String> replies = new ConcurrentLinkedQueue<>();
@OnOpen
public void onOpen(String topic, String username, WebSocketSession session) { (3)
this.topic = topic;
this.username = username;
this.session = session;
}
public String getTopic() {
return topic;
}
public String getUsername() {
return username;
}
public Collection<String> getReplies() {
return replies;
}
public WebSocketSession getSession() {
return session;
}
@OnMessage
public void onMessage(
String message) {
replies.add(message); (4)
}
}| 1 | The class is abstract (more on that later) and is annotated with @ClientWebSocket |
| 2 | The client must implement AutoCloseable and you should ensure that the connection is closed at some point. |
| 3 | You can use the same annotations as on the server, in this case @OnOpen to obtain a reference to the underlying session. |
| 4 | The @OnMessage annotation can be used to define the method that receives responses from the server. |
You can also define abstract methods that start with either send or broadcast and these methods will be implemented for you at compile time. For example:
WebSocket Send Methods
public abstract void send(String message);Note by returning void this tells Micronaut that the method is a blocking send. You can instead define methods that return either futures or a Publisher:
WebSocket Send Methods
public abstract io.reactivex.Single<String> send(String message);The above example defines a send method that returns an Single.
Once you have defined a client class you can connect to the client socket and start sending messages:
Connecting a Client WebSocket
ChatClientWebSocket chatClient = webSocketClient.connect(ChatClientWebSocket.class, "/chat/football/fred").blockingFirst();
chatClient.send("Hello World!");
For illustration purposes we use blockingFirst() to obtain the client, it is however possible to combine connect (which returns an Flowable) to perform non-blocking interaction via WebSocket.
|
|
Using the CLI
If you have created your project using the Micronaut CLI and the default ( $ mn create-websocket-client MyChat | Rendered template WebsocketClient.java to destination src/main/java/example/MyChatClient.java |
6.21 Server Events
The HTTP server will emit a number of Bean Events, defined in the io.micronaut.runtime.server.event package, that you can write listeners for. The following table summarizes those events:
| Event | Description |
|---|---|
Emitted when the server completes startup |
|
Emitted when the server shuts down |
|
Emitted after all ServerStartupEvent listeners have been executed and exposes the EmbeddedServerInstance |
|
Emitted after all ServerShutdownEvent listeners have been executed and exposes the EmbeddedServerInstance |
| If you do significant work within a listener for a ServerStartupEvent this will slow down you startup time. |
The following example defines a ApplicationEventListener that listens for ServerStartupEvent:
Listening for Server Startup Events
import io.micronaut.context.event.ApplicationEventListener;
...
@Singleton
public class StartupListener implements ApplicationEventListener<ServerStartupEvent> {
@Override
public void onApplicationEvent(ServerStartupEvent event) {
// logic here
...
}
}Alternatively, you can also use the @EventListener annotation on a method of any existing bean that accepts ServerStartupEvent:
Using
@EventListener with ServerStartupEventimport io.micronaut.runtime.server.event.*;
import io.micronaut.runtime.event.annotation.*;
...
@Singleton
public class MyBean {
@EventListener
public void onStartup(ServerStartupEvent event) {
// logic here
...
}
}6.22 Configuring the HTTP Server
The HTTP server features a number of configuration options you may wish to tweak. They are defined in the NettyHttpServerConfiguration configuration class, which extends HttpServerConfiguration.
The following example shows how to tweak configuration options for the server via application.yml:
Configuring HTTP server settings
micronaut:
server:
maxRequestSize: 1MB
host: localhost (1)
netty:
maxHeaderSize: 500KB (2)
worker:
threads: 8 (3)
childOptions:
autoRead: true (4)| 1 | By default Micronaut will bind to all the network interfaces. Use localhost to bind only to loopback network interface |
| 2 | Maximum size for headers |
| 3 | Number of netty worker threads |
| 4 | Auto read request body |
| Property | Type | Description |
|---|---|---|
|
java.util.Map |
Sets the Netty child worker options. |
|
java.util.Map |
Sets the channel options. |
|
int |
Sets the maximum initial line length for the HTTP request. Default value (4096). |
|
int |
Sets the maximum size of any one header. Default value (8192). |
|
int |
Sets the maximum size of any single request chunk. Default value (8192). |
|
boolean |
Sets whether chunked transfer encoding is supported. Default value (true). |
|
boolean |
Sets whether to validate incoming headers. Default value (true). |
|
int |
Sets the initial buffer size. Default value (128). |
|
io.netty.handler.logging.LogLevel |
Sets the Netty log level. |
6.22.1 Configuring Server Thread Pools
The HTTP server is built on Netty which is designed as a non-blocking I/O toolkit in an event loop model.
To configure the number of threads used by the Netty EventLoop, you can use application.yml:
Configuring Netty Event Loop Threads
micronaut:
server:
netty:
worker:
threads: 8 # number of netty worker threads
The default value is the value of the system property io.netty.eventLoopThreads or if not specified the available processors x 2
|
When dealing with blocking operations, Micronaut will shift the blocking operations to an unbound, caching I/O thread pool by default. You can configure the I/O thread pool using the ExecutorConfiguration named io. For example:
Configuring the Server I/O Thread Pool
micronaut:
executors:
io:
type: fixed
nThreads: 75The above configuration will create a fixed thread pool with 75 threads.
6.22.2 Configuring CORS
Micronaut supports CORS (Cross Origin Resource Sharing) out of the box. By default, CORS requests will be rejected. To enable processing of CORS requests, modify your configuration. For example with application.yml:
CORS Configuration Example
micronaut:
server:
cors:
enabled: trueBy only enabling CORS processing, a "wide open" strategy will be adopted that will allow requests from any origin.
To change the settings for all origins or a specific origin, change the configuration to provide a set of "configurations". By providing any configuration, the default "wide open" configuration is not configured.
CORS Configurations (… is a placeholder)
micronaut:
server:
cors:
enabled: true
configurations:
all:
...
web:
...
mobile:
...In the above example, three configurations are being provided. Their names (all, web, mobile) are not important and have no significance inside Micronaut. They are there purely to be able to easily recognize the intended user of the configuration.
The same configuration properties can be applied to each configuration. See CorsOriginConfiguration for the reference of properties that can be defined. Each configuration supplied will have its values default to the default values of the corresponding fields.
When a CORS request is made, configurations are searched for allowed origins that are an exact match or match the request origin through a regular expression.
Allowed Origins
To allow any origin for a given configuration, simply don’t include the allowedOrigins key in your configuration.
To specify a list of valid origins, set the allowedOrigins key of the configuration to a list of strings. Each value can either be a static value (http://www.foo.com) or a regular expression (^http(|s)://www\.google\.com$).
Any regular expressions are passed to Pattern#compile and compared to the request origin with Matcher#matches.
Example CORS Configuration
micronaut:
server:
cors:
enabled: true
configurations:
web:
allowedOrigins:
- http://foo.com
- ^http(|s)://www\.google\.com$Allowed Methods
To allow any request method for a given configuration, simply don’t include the allowedMethods key in your configuration.
To specify a list of allowed methods, set the allowedMethods key of the configuration to a list of strings.
Example CORS Configuration
micronaut:
server:
cors:
enabled: true
configurations:
web:
allowedMethods:
- POST
- PUTAllowed Headers
To allow any request header for a given configuration, simply don’t include the allowedHeaders key in your configuration.
To specify a list of allowed headers, set the allowedHeaders key of the configuration to a list of strings.
Example CORS Configuration
micronaut:
server:
cors:
enabled: true
configurations:
web:
allowedHeaders:
- Content-Type
- AuthorizationExposed Headers
To configure the list of headers that are sent in the response to a CORS request through the Access-Control-Expose-Headers header, include a list of strings for the exposedHeaders key in your configuration. By default no headers are exposed.
Example CORS Configuration
micronaut:
server:
cors:
enabled: true
configurations:
web:
exposedHeaders:
- Content-Type
- AuthorizationAllow Credentials
Credentials are allowed by default for CORS requests. To disallow credentials, simply set the allowCredentials option to false.
Example CORS Configuration
micronaut:
server:
cors:
enabled: true
configurations:
web:
allowCredentials: falseMax Age
The default maximum age that preflight requests can be cached is 30 minutes. To change that behavior, specify a value in seconds.
Example CORS Configuration
micronaut:
server:
cors:
enabled: true
configurations:
web:
maxAge: 3600 # 1 hour6.22.3 Securing the Server with HTTPS
Micronaut supports HTTPS out of the box. By default HTTPS is disabled and all requests are served using HTTP. To enable
HTTPS support, modify your configuration. For example with application.yml:
HTTPS Configuration Example
micronaut:
ssl:
enabled: true
buildSelfSigned: true (1)| 1 | Micronaut will create a self-signed certificate. |
By default Micronaut with HTTPS support starts on port 8443 but you can change the port the property
micronaut.ssl.port.
|
| Keep in mind that this configuration will generate a warning on the browser. |

Using a valid x509 certificate
It is also possible to configure Micronaut to use an existing valid x509 certificate, for example one created with
Let’s Encrypt. You will need the server.crt and server.key files and convert them to a
PKCS #12 file.
$ openssl pkcs12 -export \
-in server.crt \ (1)
-inkey server.key \ (2)
-out server.p12 \ (3)
-name someAlias \ (4)
-CAfile ca.crt -caname root| 1 | The original server.crt file |
| 2 | The original server.key file |
| 3 | The server.p12 file that will be created |
| 4 | The alias for the certificate |
During the creation of the server.p12 file it is necessary to define a password that will be required later when using
the certificate in Micronaut.
Now modify your configuration:
HTTPS Configuration Example
micronaut:
ssl:
enabled: true
keyStore:
path: classpath:server.p12 (1)
password: mypassword (2)
type: PKCS12| 1 | The p12 file created. It can also be referenced as file:/path/to/the/file |
| 2 | The password defined during the export |
With this configuration if we start Micronaut and connect to https://localhost:8443 we still see the warning on the
browser but if we inspect the certificate we can check that it’s the one generated by Let’s Encrypt.
Finally we can test that the certificate is valid for the browser just by adding an alias to the domain in /etc/hosts file:
$ cat /etc/hosts
...
127.0.0.1 my-domain.org
...Now we can connect to https://my-domain.org:8443:

Using Java Keystore (JKS)
It is not recommended using this type of certificate because it is a proprietary format and it’s better to use a PKCS12 format. In any case Micronaut also supports it.
Convert the p12 certificate to a JKS one:
$ keytool -importkeystore \
-deststorepass newPassword -destkeypass newPassword \ (1)
-destkeystore server.keystore \ (2)
-srckeystore server.p12 -srcstoretype PKCS12 -srcstorepass mypassword \ (3)
-alias someAlias (4)| 1 | It is necessary to define a the password for the keystore |
| 2 | The file that will be created |
| 3 | The PKCS12 file created before and the password defined during the creation |
| 4 | The alias used before |
If either srcstorepass or alias are not the same as defined in the p12 file, the conversion will fail.
|
Now modify your configuration:
HTTPS Configuration Example
micronaut:
ssl:
enabled: true
keyStore:
path: classpath:server.keystore
password: newPassword
type: JKSStart Micronaut and the application is running on https://localhost:8443 using the certificate in the keystore.
6.23 Server Side View Rendering
Although Micronaut is primarily designed around message encoding / decoding there are occasions where it is convenient to render a view on the server side.
The views module provides support for view rendering on the server side and does so by rendering views on the I/O thread pool in order to avoid blocking the Netty event loop.
To use the view rendering features described in this section, add the following dependency on your classpath. For example, in build.gradle
build.gradle
compile "io.micronaut:micronaut-views"Views and templates can then be placed in the src/main/resource/views directory of your project.
If you wish to use a different folder instead of views, set the property micronaut.views.folder.
Your controller’s method can render the response with a template with the the View annotation.
The following is an example of a controller which renders a template by passing a model as a java.util.Map via the returned response object.
src/main/java/myapp/ViewsController.java
@Controller("/views")
class ViewsController {
@View("home")
@Get("/")
public HttpResponse index() {
return HttpResponse.ok(CollectionUtils.mapOf("loggedIn", true, "username", "sdelamo"))
}
}| 1 | Use @View annotation to indicate the view name which should be used to render a view for the route. |
In addition, you can return any POJO object and the properties of the POJO will be exposed to the view for rendering:
src/main/java/myapp/ViewsController.java
@Controller("/views")
class ViewsController {
@View("home")
@Get("/pogo")
public HttpResponse<Person> pogo() {
return HttpResponse.ok(new Person("sdelamo", true))
}
}| 1 | Use @View annotation to indicate the view name which should be used to render the POJO responded by the controller. |
You can also return a ModelAndView and skip specifying the View annotation.
src/main/java/myapp/ViewsController.java
@Controller("/views")
class ViewsController {
@Get("/modelAndView")
ModelAndView modelAndView() {
return new ModelAndView("home",
new Person(loggedIn: true, username: 'sdelamo'))
}The following sections show different template engines integrations.
To create your own implementation create a class which implements ViewRenderer and annotate it with @Produces to the media types the view rendering supports producing.
6.23.1 Thymeleaf
Micronaut includes ThymeleafViewsRenderer which uses the Thymeleaf Java template engine.
In addition to the Views dependency, add the following dependency on your classpath. For example, in build.gradle
runtime "org.thymeleaf:thymeleaf:3.0.9.RELEASE"Thymeleaf integration instantiates a ClassLoaderTemplateResolver.
The properties used can be customized by overriding the values of:
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets whether thymeleaf rendering is enabled. Default value (true). |
|
java.lang.String |
Sets the character encoding to use. Default value ("UTF-8"). |
|
org.thymeleaf.templatemode.TemplateMode |
Sets the template mode. |
|
java.lang.String |
Sets the suffix to use. |
|
boolean |
Sets whether to force the suffix. Default value (false). |
|
boolean |
Sets whether to force template mode. Default value (false). |
|
boolean |
Sets whether templates are cacheable. |
|
java.lang.Long |
Sets the cache TTL in millis. |
|
boolean |
Sets whether templates should be checked for existence. |
|
java.time.Duration |
Sets the cache TTL as a duration. |
The example shown in the Views section, could be rendered with the following Thymeleaf template:
src/main/resources/views/home.html
<!DOCTYPE html>
<html th:replace="~{layoutFile :: layout(~{::title}, ~{::section})}">
<head>
<title>Home</title>
</head>
<body>
<section>
<h1 th:if="${loggedIn}">username: <span th:text="${username}"></span></h1>
<h1 th:unless="${loggedIn}">You are not logged in</h1>
</section>
</body>
</html>and layout:
src/main/resources/views/layoutFile.html
<!DOCTYPE html>
<html th:fragment="layout (title, content)" xmlns:th="http://www.thymeleaf.org">
<head>
<title th:replace="${title}">Layout Title</title>
</head>
<body>
<h1>Layout H1</h1>
<div th:replace="${content}">
<p>Layout content</p>
</div>
<footer>
Layout footer
</footer>
</body>
</html>6.23.2 Handlebars.java
Micronaut includes HandlebarsViewsRenderer which uses the Handlebars.java project.
In addition to the Views dependency, add the following dependency on your classpath. For example, in build.gradle
runtime "com.github.jknack:handlebars:4.1.0"The example shown in the Views section, could be rendered with the following Handlebars template:
src/main/resources/views/home.hbs
<!DOCTYPE html>
<html>
<head>
<title>Home</title>
</head>
<body>
{{#if loggedIn}}
<h1>username: <span>{{username}}</span></h1>
{{else}}
<h1>You are not logged in</h1>
{{/if}}
</body>
</html>6.23.3 Apache Velocity
Micronaut includes VelocityViewsRenderer which uses the Apache Velocity Java-based template engine.
In addition to the Views dependency, add the following dependency on your classpath. For example, in build.gradle
runtime "org.apache.velocity:velocity-engine-core:2.0"The example shown in the Views section, could be rendered with the following Velocity template:
src/main/resources/views/home.vm
<!DOCTYPE html>
<html>
<head>
<title>Home</title>
</head>
<body>
#if( $loggedIn )
<h1>username: <span>$username</span></h1>
#else
<h1>You are not logged in</h1>
#end
</body>
</html>6.24 OpenAPI / Swagger Support
Micronaut includes experimental support for producing OpenAPI (Swagger) YAML at compilation time. Micronaut will at compile time produce a Swagger 2.x compliant YAML file just based on the regular Micronaut annotations and the javadoc comments within your code.
You can customize the generated Swagger using the standard Swagger Annotations.
Getting Started with Swagger
To enable this support you should add the following dependencies to your build configuration:
Adding the Swagger Dependencies
annotationProcessor "io.micronaut.configuration:micronaut-openapi" (1)
compile "io.swagger.core.v3:swagger-annotations" (2)| 1 | The openapi configuration gets added into the annotation processor scope |
| 2 | The Swagger Annotations are added to the compile classpath |
For Kotlin the openapi dependency should be in the kapt scope and for Groovy in the compileOnly scope.
|
You can use the swagger-* feature when creating your app to setup Swagger / OpenAPI correctly: mn create-app my-app --features swagger-java
|
Once dependencies have been configured a minimum requirement is to add a @OpenAPIDefinition annotation to your Application class:
Example @OpenAPIDefinition usage
import io.swagger.v3.oas.annotations.*;
import io.swagger.v3.oas.annotations.info.*;
@OpenAPIDefinition(
info = @Info(
title = "Hello World",
version = "0.0",
description = "My API",
license = @License(name = "Apache 2.0", url = "http://foo.bar"),
contact = @Contact(url = "http://gigantic-server.com", name = "Fred", email = "Fred@gigagantic-server.com")
)
)
public class Application {
public static void main(String[] args) {
Micronaut.run(Application.class);
}
}With that in place you compile your project and a Swagger YAML file will be generated to the META-INF/swagger directory of your project’s class output. For example the above configuration for Java will be generated to build/classes/java/main/META-INF/swagger/hello-world-0.0.yml.
The previously defined annotations will produce YAML like the following:
Generated Swagger YAML
openapi: 3.0.1
info:
title: the title
description: My API
contact:
name: Fred
url: http://gigantic-server.com
email: Fred@gigagantic-server.com
license:
name: Apache 2.0
url: http://foo.bar
version: "0.0"Exposing Swagger Output
If you wish to expose the generated Swagger output from your running application you can simply add the necessary static resource configuration. For example:
Exposing Swagger YAML
micronaut:
router:
static-resources:
swagger:
paths: classpath:META-INF/swagger
mapping: /swagger/**With the above configuration in place when you run your application you can access your Swagger documentation at http://localhost:8080/swagger/the-title-0.0.yml.
Controllers and Swagger Annotations
By default Micronaut will automatically at compile time build out the Swagger YAML definition from your defined controllers and methods. For example given the following class:
Hello World Example
@Controller("/")
@Validated
public class HelloController {
/**
* @param name The person's name
* @return The greeting
*/
@Get(uri="/hello/{name}", produces=MediaType.TEXT_PLAIN)
public Single<String> hello(@NotBlank String name) {
return Single.just("Hello " + name + "!");
}
}The resulting output will be:
Example Generated Swagger Output
paths:
/hello/{name}:
get:
description: ""
operationId: hello
parameters:
- name: name
in: path
description: The person's name
required: true
explode: false
schema:
type: string
responses:
default:
description: The greeting
content:
text/plain:
schema:
type: stringNotice how the javadoc comments are used to fill out the description of the API. If this is not desirable then you can take full control by augmenting your definition with Swagger annotations:
Using Swagger Annotations
import io.swagger.v3.oas.annotations.*;
import io.swagger.v3.oas.annotations.parameters.*;
import io.swagger.v3.oas.annotations.responses.*;
import io.swagger.v3.oas.annotations.security.*;
import io.swagger.v3.oas.annotations.tags.*;
import io.swagger.v3.oas.annotations.media.*;
import io.swagger.v3.oas.annotations.enums.*;
@Controller("/")
@Validated
public class HelloController {
/**
* @param name The person's name
* @return The greeting
*/
@Get(uri="/hello/{name}", produces=MediaType.TEXT_PLAIN)
@Operation(summary = "Greets a person",
description = "A friendly greeting is returned",
)
@ApiResponse(
content = @Content(mediaType = "text/plain",
schema = @Schema(type="string"))
)
@ApiResponse(responseCode = "400", description = "Invalid Name Supplied")
@ApiResponse(responseCode = "404", description = "Person not found")
@Tag(name = "greeting")
public Single<String> hello(@Parameter(description="The name of the person") @NotBlank String name) {
return Single.just("Hello " + name + "!");
}
}Schemas and POJOs
If you return types are not simple strings and primitive types then Micronaut will attempt to generate a Schema definition. You can customize the
generation of the Schema by using the @Schema annotation on your POJO. For example:
Using the @Schema Annotation
@Schema(name="MyPet", description="Pet description") (1)
class Pet {
private PetType type;
private int age;
private String name;
public void setAge(int a) {
age = a;
}
/**
* The age
*/
@Schema(description="Pet age", maximum="20") (2)
public int getAge() {
return age;
}
public void setName(String n) {
name = n;
}
@Schema(description="Pet name", maxLength=20)
public String getName() {
return name;
}
public void setType(PetType t) {
type = t;
}
public PetType getType() {
return type;
}
}
enum PetType {
DOG, CAT;
}| 1 | The @Schema annotation is used to customize the name of the schema |
| 2 | Properties can be customized too. |
Schemas and Generics
If a method return type includes generics then these will included when calculating the schema name. For example the following:
Swagger returns types and generics
class Response<T> {
private T r;
public T getResult() {
return r;
};
}
@Controller("/")
class MyController {
@Put("/")
public Response<Pet> updatePet(Pet pet) {
...
}
}Will result in a schema called #/components/schemas/Response<Pet> being generated. If you wish to alter the name of the schema you can do so with the @Schema annotation:
Changing the name of response schema
@Put("/")
@Schema(name="ResponseOfPet")
public Response<Pet> updatePet(Pet pet) {
...
}In the above case the generated schema will be named #/components/schemas/ResponseOfPet.
7 The HTTP Client
|
Using the CLI
If you are creating your project using the Micronaut CLI, the |
A critical component of any Microservice architecture is the client communication between Microservices. With that in mind Micronaut features a built in HTTP client that has both a low-level API and a higher level AOP-driven API.
| Regardless whether you choose to use Micronaut’s HTTP server, you may wish to use the Micronaut HTTP client in your application since it is a feature-rich client implementation. |
To use the HTTP client you must have the http-client dependency on your classpath. For example in build.gradle:
build.gradle
compile "io.micronaut:micronaut-http-client"Since the higher level API is built on the low-level HTTP client, we will first introduce the low-level client.
7.1 Using the Low-Level HTTP Client
The HttpClient interface forms the basis for the low-level API. This interfaces declares methods to help ease executing HTTP requests and receive responses.
The majority of the methods in the HttpClient interface returns Reactive Streams Publisher instances, which is not always the most useful interface to work against, hence a sub-interface called RxHttpClient is included that provides a variation of the HttpClient interface that returns RxJava Flowable types.
7.1.1 Sending your first HTTP request
Obtaining a HttpClient
There are a few ways by which you can obtain a reference to a HttpClient. The most common way is using the Client annotation. For example:
Injecting an HTTP client
@Client("https://api.twitter.com/1.1") @Inject RxHttpClient httpClient;The above example will inject a client that targets the Twitter API.
@Client("\${myapp.api.twitter.url}") @Inject httpClient: RxHttpClientThe above Kotlin example will inject a client that targets the Twitter API using a configuration path. Note the required escaping (backslash) on "\${path.to.config}" which is required due to Kotlin string interpolation.
The Client annotation is also a custom scope that will manage the creation of HttpClient instances and ensure they are shutdown when the application shuts down.
The value you pass to the Client annotation can be one of the following:
-
A absolute URI. Example
https://api.twitter.com/1.1 -
A relative URI, in which case the server targeted will be the current server (useful for testing)
-
A service identifier. See the section on Service Discovery for more information on this topic.
Another way to create an HttpClient is with the create static method of the RxHttpClient, however this approach is not recommended as you will have to ensure you manually shutdown the client and of course no dependency injection will occur for the created client.
Performing an HTTP GET
Generally there are two methods of interest when working with the HttpClient. The first method is called retrieve, which will execute an HTTP request and return the body in whichever type you request (by default a String) as an RxJava Flowable.
The retrieve method accepts an HttpRequest object or a String URI to the endpoint you wish to request.
The following example shows how to use retrieve to execute an HTTP GET and receive the response body as a String:
Using retrieve
String result = client.toBlocking().retrieve("/hello/John");
assertEquals(
"Hello John",
result
);Note that in this example, for illustration purposes we are calling toBlocking() to return a blocking version of the client. However, in production code you should not do this and instead rely on the non-blocking nature of the Micronaut HTTP server.
For example the following @Controller method calls another endpoint in a non-blocking manner:
Using the HTTP client without blocking
import static io.micronaut.http.HttpRequest.*;
import io.micronaut.http.HttpStatus;
import io.micronaut.http.MediaType;
import io.micronaut.http.annotation.*;
import io.micronaut.http.client.*;
import io.micronaut.http.client.annotation.Client;
import io.reactivex.Maybe;
@Get("/hello/{name}")
Maybe<String> hello(String name) { (1)
return httpClient.retrieve( GET("/hello/" + name) )
.firstElement(); (2)
}| 1 | The method hello returns a Maybe which may or may not emit an item. If an item is not emitted a 404 is returned. |
| 2 | The retrieve method is called which returns a Flowable which has a firstElement method that returns the first emitted item or nothing |
| Using RxJava (or Reactor if you prefer) you can easily and efficiently compose multiple HTTP client calls without blocking (which will limit the throughput and scalability of your application). |
Debugging / Tracing the HTTP Client
To debug the requests being sent and received from the HTTP client you can enable tracing logging via your logback.xml file:
logback.xml
<logger name="io.micronaut.http.client" level="TRACE"/>Client Specific Debugging / Tracing
To enable client-specific logging you could configure the default logger for all HTTP clients. And, you could also configure different loggers for different clients using Client Specific Configuration. For example, in application.yml:
application.yml
micronaut:
http:
client:
logger-name: mylogger
services:
otherClient:
logger-name: other.clientAnd, then enable logging in logback.yml:
logback.xml
<logger name="mylogger" level="DEBUG"/>
<logger name="other.client" level="TRACE"/>Customizing the HTTP Request
The previous example demonstrated using the static methods of the HttpRequest interface to construct a MutableHttpRequest instance. Like the name suggests a MutableHttpRequest can be mutated including the ability to add headers, customize the request body and so on. For example:
Passing an HttpRequest to retrieve
Flowable<String> response = client.retrieve(
GET("/hello/John")
.header("X-My-Header", "SomeValue")
);The above example adds an additional header called X-My-Header to the request before it is sent. The MutableHttpRequest interface has a bunch more convenience methods that make it easy to modify the request in common ways.
Reading JSON Responses
Typically with Microservices a message encoding format is used such as JSON. Micronaut’s HTTP client leverages Jackson for JSON parsing hence whatever type Jackson can decode can passed as a second argument to retrieve.
For example consider the following @Controller method that returns a JSON response:
Returning JSON from a controller
@Get("/greet/{name}")
Message greet(String name) {
return new Message("Hello " + name);
}The method above returns a POJO of type Message which looks like:
Message POJO
import com.fasterxml.jackson.annotation.*;
public class Message {
private final String text;
@JsonCreator
public Message(@JsonProperty("text") String text) {
this.text = text;
}
public String getText() {
return text;
}
}| Jackson annotations are used to map the constructor |
On the client end you can call this endpoint and decode the JSON into a map using the retrieve method as follows:
Decoding the response body to a Map
Flowable<Map> response = client.retrieve(
GET("/greet/John"), Map.class
);The above examples decodes the response into a Map, representing the JSON. If you wish to customize the type of the key and string you can use the Argument.of(..) method:
Decoding the response body to a Map
response = client.retrieve(
GET("/greet/John"),
Argument.of(Map.class, String.class, String.class) (1)
);| 1 | The Argument.of method is used to return a Map whether the key and value are typed as String |
Whilst retrieving JSON as a map can be desirable, more often than not you will want to decode objects into Plain Old Java Objects (POJOs). To do that simply pass the type instead:
Decoding the response body to a POJO
Flowable<Message> response = client.retrieve(
GET("/greet/John"), Message.class
);
assertEquals(
"Hello John",
response.blockingFirst().getText()
);Note how you can use the same Java type on both the client and the server. The implication of this is that typically you will want to define a common API project where you define the interfaces and types that define your API.
Decoding Other Content Types
If the server you are communicating with uses a custom content type that is not JSON by default Micronaut’s HTTP client will not know how to decode this type.
To resolve this issue you can register MediaTypeCodec as a bean and it will be automatically picked up and used to decode (or encode) messages.
Receiving the Full HTTP Response
Sometimes, receiving just the object is not enough and you need information about the response. In this case, instead of retrieve you should use the exchange method:
Recieving the Full HTTP Response
Flowable<HttpResponse<Message>> call = client.exchange(
GET("/greet/John"), Message.class (1)
);
HttpResponse<Message> response = call.blockingFirst();
Optional<Message> message = response.getBody(Message.class); (2)
// check the status
assertEquals(
HttpStatus.OK,
response.getStatus() (3)
);
// check the body
assertTrue(message.isPresent());
assertEquals(
"Hello John",
message.get().getText()
);| 1 | The exchange method is used to receive the HttpResponse |
| 2 | The body can be retrieved using the getBody(..) method of the response |
| 3 | Other aspects of the response, such as the HttpStatus can be checked |
The above example receives the full HttpResponse object from which you can obtain headers and other useful information.
7.1.2 Posting a Request Body
All the examples up until now have used the same HTTP method i.e GET. The HttpRequest interface has factory methods for all the different HTTP methods. The following table summarizes the available methods:
| Method | Description | Allows Body |
|---|---|---|
Constructs an HTTP |
|
|
Constructs an HTTP |
|
|
Constructs an HTTP |
|
|
Constructs an HTTP |
|
|
Constructs an HTTP |
|
|
Constructs an HTTP |
|
|
Constructs an HTTP |
|
A create method also exists to construct a request for any HttpMethod type. Since the POST, PUT and PATCH methods require a body, a second argument which is the body object is required.
The following example demonstrates how to send a simply String body:
Sending a
String bodyFlowable<HttpResponse<String>> call = client.exchange(
POST("/hello", "Hello John") (1)
.contentType(MediaType.TEXT_PLAIN_TYPE)
.accept(MediaType.TEXT_PLAIN_TYPE), (2)
String.class (3)
);| 1 | The POST method is used with the first argument being the URI and the second argument the body |
| 2 | The content type and accepted type are set to text/plain (the default content type is application/json) |
| 3 | The expected response type is a String |
Sending JSON
The previous example sends plain text, if you wish send JSON you can simply pass the object you wish to encode as JSON, whether that be a map or a POJO. As long as Jackson is able to encode it.
For example, the Message class from the previous section, you can create an instance and pass it to the POST method:
Sending a JSON body
Flowable<HttpResponse<Message>> call = client.exchange(
POST("/greet", new Message("Hello John")), (1)
Message.class (2)
);| 1 | And instance of Message is created and passed to the POST method |
| 2 | The same class is used to decode the response |
With the above example the following JSON will be sent as the body of the request:
Resulting JSON
{"text":"Hello John"}The JSON itself can be customized however you want using Jackson Annotations.
Using a URI Template
If some of the properties of the object need to be in the URI being posted to you can use a URI template.
For example imagine you have a class Book that has a property called title. You can represent the title property in the URI template and then populate it from an instance of Book. For example:
Sending a JSON body with a URI template
Flowable<HttpResponse<Book>> call = client.exchange(
POST("/amazon/book/{title}", new Book("The Stand")),
Book.class
);In the above case the title property of the passed object will be included in the URI being posted to.
Sending Form Data
You can also encode a POJO or a map as regular form data instead of JSON. Just set the content type to application/x-www-form-urlencoded on the post request:
Sending a Form Data
Flowable<HttpResponse<Book>> call = client.exchange(
POST("/amazon/book/{title}", new Book("The Stand"))
.contentType(MediaType.APPLICATION_FORM_URLENCODED),
Book.class
);Note that Jackson is used to bind form data too, so to customize the binding process you can use Jackson annotations.
7.1.3 Multipart Client Uploads
The Micronaut HTTP Client supports the ability to create multipart requests. In order to build a multipart request you must set the content type to multipart/form-data and set the body to be an instance of MultipartBody:
For example:
Creating the body
import io.micronaut.http.client.multipart.MultipartBody
import io.micronaut.http.HttpRequest
import io.micronaut.http.MediaType
File file = ...
MultipartBody requestBody = MultipartBody.builder() (1)
.addPart( (2)
"data",
file.name,
MediaType.TEXT_PLAIN_TYPE,
file
).build() (3)| 1 | You need to create a MultipartBody builder for adding parts to the body. |
| 2 | Method to add a part to the body, in this case a file. There are different variations of this method which you can see in MultipartBody.Builder. |
| 3 | Call the build method to assemble all parts from the builder into a MultipartBody. At least one part is required. |
Creating a request
HttpRequest.POST("/multipart/upload", requestBody) (1)
.contentType(MediaType.MULTIPART_FORM_DATA_TYPE) (2)| 1 | The multipart request body with different sets of data. |
| 2 | Set the content-type header of the request to multipart/form-data. |
7.1.4 Streaming JSON over HTTP
Micronaut’s HTTP client includes support for streaming data over HTTP via the RxStreamingHttpClient interface which includes methods specific to HTTP streaming including:
| Method | Description |
|---|---|
|
Returns a stream of data as a Flowable of ByteBuffer |
|
Returns the HttpResponse wrapping a Flowable of ByteBuffer |
|
Returns a non-blocking stream of JSON objects |
In order to do JSON streaming you should on the server side declare a controller method that returns a application/x-json-stream of JSON objects. For example:
Streaming JSON on the Server
import io.micronaut.http.MediaType;
import io.micronaut.http.annotation.*;
import io.reactivex.Flowable;
import java.time.ZonedDateTime;
import java.util.concurrent.TimeUnit;
@Get(value = "/headlines", produces = MediaType.APPLICATION_JSON_STREAM) (1)
Flowable<Headline> streamHeadlines() {
return Flowable.fromCallable(() -> { (2)
Headline headline = new Headline();
headline.setText("Latest Headline at " + ZonedDateTime.now());
return headline;
}).repeat(100) (3)
.delay(1, TimeUnit.SECONDS); (4)
}| 1 | A method streamHeadlines is defined that produces application/x-json-stream |
| 2 | A Flowable is created from a Callable function (note no blocking occurs within the function so this is ok, otherwise you would want to subscribeOn an I/O thread pool). |
| 3 | The Flowable is set to repeat 100 times |
| 4 | The Flowable will emit items with a delay of 1 second between each item |
| The server does not have to be written in Micronaut, any server that supports JSON streaming will do. |
Then on the client simply subscribe to the stream using jsonStream and every time the server emits a JSON object the client will decode and consume it:
Streaming JSON on the Client
Flowable<Headline> headlineStream = client.jsonStream(GET("/streaming/headlines"), Headline.class); (1)
CompletableFuture<Headline> future = new CompletableFuture<>(); (2)
headlineStream.subscribe(new Subscriber<Headline>() {
@Override
public void onSubscribe(Subscription s) {
s.request(1); (3)
}
@Override
public void onNext(Headline headline) {
System.out.println("Received Headline = " + headline.getText());
future.complete(headline); (4)
}
@Override
public void onError(Throwable t) {
future.completeExceptionally(t); (5)
}
@Override
public void onComplete() {
// no-op (6)
}
});| 1 | The jsonStream method is used return a Flowable |
| 2 | A CompletableFuture is used in the example to receive a value, but what you do with each emitted item is application specific |
| 3 | The Subscription is used to request a single item. You can use the Subscription to regulate back pressure and demand. |
| 4 | The onNext method is called when an item is emitted |
| 5 | The onError method is called when an error occurs |
| 6 | The onComplete method is called when all Headline instances have been emitted |
Note neither the server or the client in the example above perform blocking I/O at any point.
7.1.5 Configuring HTTP clients
Global Configuration for All Clients
The default HTTP client configuration is a Configuration Properties called DefaultHttpClientConfiguration that allows configuring the default behaviour for all HTTP clients. For example, in application.yml:
Altering default HTTP client configuration
micronaut:
http:
client:
read-timeout: 5sThe above example sets of readTimeout property of the HttpClientConfiguration class.
Client Specific Configuration
If you wish to have a separate configuration per client then there a couple of options. You can configure Service Discovery manually in application.yml and apply per-client configuration:
Manually configuring HTTP services
micronaut:
http:
services:
foo:
urls:
- http://foo1
- http://foo2
read-timeout: 5s (1)| 1 | The read timeout is applied to the foo client. |
WARN: This client configuration can be used in conjunction with the @Client annotation, either by injecting an HttpClient directly or use on a client interface. In any case, all other attributes on the annotation will be ignored other than the service id.
Then simply inject the named client configuration:
Injecting an HTTP client
@Client("foo") @Inject RxHttpClient httpClient;You can also simply define a bean that extends from HttpClientConfiguration and ensuring that the javax.inject.Named annotation is used to name it appropriately:
Defining an HTTP client configuration bean
@Named("twitter")
@Singleton
class TwitterHttpClientConfiguration extends HttpClientConfiguration {
public TwitterHttpClientConfiguration(ApplicationConfiguration applicationConfiguration) {
super(applicationConfiguration);
}
}This configuration will then be picked up if you inject a service called twitter using @Client using Service Discovery:
Injecting an HTTP client
@Client("twitter") @Inject RxHttpClient httpClient;Alternatively if you are not using service discovery then you can use the configuration member of @Client to refer to a specific type:
Injecting an HTTP client
@Client(value="https://api.twitter.com/1.1",
configuration=TwitterHttpClientConfiguration.class)
@Inject
RxHttpClient httpClient;Using HTTP Client Connection Pooling
If you have a client that needs to handle a significant number of requests then you can benefit from enabling HTTP client connection pooling. The following configuration will enable pooling for the foo client:
Manually configuring HTTP services
micronaut:
http:
services:
foo:
urls:
- http://foo1
- http://foo2
pool:
enabled: true (1)
max-connections: 50 (2)| 1 | Enables the pool |
| 2 | Sets the maximum number of connections in the pool |
See the API for ConnectionPoolConfiguration for details on available options to configure the pool.
7.1.6 Bind Errors
Often you want to consume an endpoint and bind to a POJO if the request is successful or bind to a different POJO if an error occurs. The following example shows how to invoke exchange with a success and error type.
@Controller("/books")
public class BooksController {
@Get("/{isbn}")
public HttpResponse find(String isbn) {
if (isbn.equals("1680502395")) {
Map<String, Object> m = new HashMap<>();
m.put("status", 401);
m.put("error", "Unauthorized");
m.put("message", "No message available");
m.put("path", "/books/"+isbn);
return HttpResponse.status(HttpStatus.UNAUTHORIZED).body(m);
}
return HttpResponse.ok(new Book("1491950358", "Building Microservices"));
}
}def "after an HttpClientException the response body can be bound to a POJO"() {
when:
client.toBlocking().exchange(HttpRequest.GET("/books/1680502395"),
Argument.of(Book), (1)
Argument.of(CustomError)) (2)
then:
def e = thrown(HttpClientException)
e.response.status == HttpStatus.UNAUTHORIZED
when:
Optional<CustomError> jsonError = e.response.getBody(CustomError)
then:
jsonError.isPresent()
jsonError.get().status == 401
jsonError.get().error == 'Unauthorized'
jsonError.get().message == 'No message available'
jsonError.get().path == '/books/1680502395'
}| 1 | Success Type |
| 2 | Error Type |
7.2 Declarative HTTP Clients with @Client
Now that you have gathered an understanding of the workings of the lower level HTTP client, it is time to take a look at Micronaut’s support for declarative clients via the Client annotation.
Essentially, the @Client annotation can be declared on any interface or abstract class and through the use of Introduction Advice the abstract methods will be implemented for you at compile time, greatly simplifying the creation of HTTP clients.
Let’s start with a simple example. Given the following class:
Pet.java
public class Pet {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}You can define a common interface for saving new Pet instances:
PetOperations.java
import io.micronaut.http.annotation.Post;
import io.micronaut.validation.Validated;
import io.reactivex.Single;
import javax.validation.constraints.*;
@Validated
public interface PetOperations {
@Post
Single<Pet> save(@NotBlank String name, @Min(1L) int age);
}Note how the interface uses Micronaut’s HTTP annotations which are usable on both the server and client side. Also, as you can see you can use javax.validation constraints to validate arguments.
Additionally, to use the javax.validation features you should have the validation and hibernate-validator dependencies on your classpath. For example in build.gradle:
build.gradle
compile "io.micronaut:micronaut-validation"
compile "io.micronaut.configuration:micronaut-hibernate-validator"On the server-side of Micronaut you can implement the PetOperations interface:
PetController.java
import io.micronaut.http.annotation.Controller;
import io.reactivex.Single;
@Controller("/pets")
class PetController implements PetOperations {
@Override
public Single<Pet> save(String name, int age) {
Pet pet = new Pet();
pet.setName(name);
pet.setAge(age);
// save to database or something
return Single.just(pet);
}
}You can then define a declarative client in src/test/java that uses @Client to automatically, at compile time, implement a client:
PetClient.java
import io.micronaut.http.client.annotation.Client;
import io.reactivex.Single;
@Client("/pets") (1)
public interface PetClient extends PetOperations { (2)
@Override
Single<Pet> save(String name, int age); (3)
}| 1 | The Client annotation is used with a value relative to the current server. In this case /pets |
| 2 | The interface extends from PetOperations |
| 3 | The save method is overridden. See warning below. |
Notice in the above example we override the save method. This is necessary if you compile without the -parameters option since Java does not retain parameters names in the byte code otherwise. If you compile with -parameters then overriding is not necessary.
|
Once you have defined a client you can simply @Inject it wherever you may need it.
Recall that the value of @Client can be:
-
An absolute URI. Example
https://api.twitter.com/1.1 -
A relative URI, in which case the server targeted will be the current server (useful for testing)
-
A service identifier. See the section on Service Discovery for more information on this topic.
In a production deployment you would typically use a service ID and Service Discovery to discover services automatically.
Another important thing to notice regarding the save method in the example above is that is returns a Single type.
This is a non-blocking reactive type and typically you want your HTTP clients not to block. There are cases where you may want to write an HTTP client that does block (such as in unit test cases), but this are rare.
The following table illustrates common return types usable with @Client:
| Type | Description | Example Signature |
|---|---|---|
Any type that implements the Publisher interface |
|
|
An HttpResponse and optional response body type |
Single<HttpResponse<String>> hello() |
|
A Publisher implementation that emits a POJO |
|
|
A Java |
|
|
A blocking native type. Such as |
|
|
T |
Any simple POJO type. |
|
Generally, any reactive type that can be converted to the Publisher interface is supported as a return type including (but not limited to) the reactive types defined by RxJava 1.x, RxJava 2.x and Reactor 3.x.
Returning CompletableFuture instances is also supported. Note that returning any other type will result in a blocking request and is not recommended other than for testing.
7.2.1 Customizing Parameter Binding
The previous example presented a trivial example that uses the parameters of a method to represent the body of a POST request:
PetOperations.java
@Post
Single<Pet> save(@NotBlank String name, @Min(1L) int age);The save method when called will perform an HTTP POST with the following JSON by default:
Example Produced JSON
{"name":"Dino", age:10}You may however want to customize what is sent as the body, the parameters, URI variables and so on. The @Client annotation is very flexible in this regard and supports the same HTTP Annotations as Micronaut’s HTTP server.
For example, the following defines a URI template and the name parameter is used as part of the URI template, whilst @Body is used declare that the contents to send to the server are represented by the Pet POJO:
PetOperations.java
@Post("/{name}")
Single<Pet> save(
@NotBlank String name, (1)
@Body @Valid Pet pet) (2)| 1 | The name parameter, included as part of the URI, and declared @NotBlank |
| 2 | The pet parameter, used to encode the body and declared @Valid |
The following table summarizes the parameter annotations, their purpose and provides an example:
| Annotation | Description | Example |
|---|---|---|
Allows to specify the parameter that is the body of the request |
|
|
Allows specifying parameters that should be sent as cookies |
|
|
Allows specifying parameters that should be sent as HTTP headers |
|
|
Allows customizing the name of the URI parameter to bind from |
|
7.2.2 Streaming with @Client
The @Client annotation can also handle streaming HTTP responses.
Streaming JSON with @Client
For example to write a client that streams data from the controller defined in the JSON Streaming section of the documentation you can simply define a client that returns an unbound Publisher such as a RxJava Flowable or Reactor Flux:
HeadlineClient.java
@Client("/streaming")
public interface HeadlineClient {
@Get(value = "/headlines", processes = MediaType.APPLICATION_JSON_STREAM) (1)
Flowable<Headline> streamHeadlines(); (2)
}| 1 | The @Get method is defined as processing responses of type APPLICATION_JSON_STREAM |
| 2 | A Flowable is used as the return type |
The following example shows how the previously defined HeadlineClient can be invoked from a JUnit test:
Streaming HeadlineClient
@Test
public void testClientAnnotationStreaming() throws Exception {
try( EmbeddedServer embeddedServer = ApplicationContext.run(EmbeddedServer.class) ) {
HeadlineClient headlineClient = embeddedServer
.getApplicationContext()
.getBean(HeadlineClient.class); (1)
Maybe<Headline> firstHeadline = headlineClient.streamHeadlines().firstElement(); (2)
Headline headline = firstHeadline.blockingGet(); (3)
assertNotNull( headline );
assertTrue( headline.getText().startsWith("Latest Headline") );
}
}| 1 | The client is retrieved from the ApplicationContext |
| 2 | The firstElement method is used to return the first emitted item from the Flowable as a Maybe. |
| 3 | The blockingGet() is used in the test to retrieve the result. |
Streaming Clients and Response Types
The example defined in the previous section expects the server to respond with a stream of JSON objects and the content type to be application/x-json-stream. For example:
A JSON Stream
{"title":"The Stand"}
{"title":"The Shining"}The reason for this is simple, a sequence of JSON object is not, in fact, valid JSON and hence the response content type cannot be application/json. For the JSON to be valid it would have to return an array:
A JSON Array
[
{"title":"The Stand"},
{"title":"The Shining"}
]Micronaut’s client does however support streaming of both individual JSON objects via application/x-json-stream and also JSON arrays defined with application/json.
Streaming Clients and Read Timeout
When streaming responses from servers, the underlying HTTP client will not apply the default readTimeout setting (which defaults to 10 seconds) of the HttpClientConfiguration since the delay between reads for streaming responses may differ from normal reads.
Instead the read-idle-timeout setting (which defaults to 60 seconds) is used to dictate when a connection should be closed after becoming idle.
If you are streaming data from a server that defines a longer delay than 60 seconds between items being sent to the client you should adjust the readIdleTimeout. The following configuration in application.yml demonstrates how:
Adjusting the readIdleTimeout
micronaut:
http:
client:
read-idle-timeout: 5mThe above example sets the readIdleTimeout to 5 minutes.
Streaming Server Sent Events
Micronaut features a native client for Server Sent Events (SSE) defined by the interface SseClient.
You can use this client to stream SSE events from any server that emits them.
Although SSE streams are typically consumed by a browser EventSource, there are a few cases where you may wish to consume a SSE stream via SseClient such as in unit testing or when a Micronaut service acts as a gateway for another service.
|
The @Client annotation also supports consuming SSE streams. For example, consider the following controller method that produces a stream of SSE events:
SSE Controller
@Get(value = "/headlines", produces = MediaType.TEXT_EVENT_STREAM) (1)
Flux<Event<Headline>> streamHeadlines() {
return Flux.<Event<Headline>>create((emitter) -> { (2)
Headline headline = new Headline();
headline.setText("Latest Headline at " + ZonedDateTime.now());
emitter.next(Event.of(headline));
emitter.complete();
}).repeat(100) (3)
.delayElements(Duration.ofSeconds(1)); (4)
}| 1 | The controller defines a @Get annotation that produces a MediaType.TEXT_EVENT_STREAM |
| 2 | The method itself uses Reactor to emit a hypothetical Headline object |
| 3 | The repeat method is used to repeat the emission 100 times |
| 4 | With a delay of 1 second between each item emitted. |
Notice that the return type of the controller is also Event and that the Event.of method is used to create events to stream to the client.
To define a client that consumes the events you simply have to define a method that processes MediaType.TEXT_EVENT_STREAM:
SSE Client
@Client("/streaming/sse")
public interface HeadlineClient {
@Get(value = "/headlines", processes = MediaType.TEXT_EVENT_STREAM)
Flux<Event<Headline>> streamHeadlines();
}The generic type of the Flux or Flowable can be either an Event, in which case you will receive the full event object, or a POJO, in which case you will receive only the data contained within the event converted from JSON.
7.2.3 Customizing Request Headers
Customizing the request headers deserves special mention as there are several ways that can be accomplished.
Populating Headers Using Configuration
The @Header annotation can be declared at the type level and is repeatable such that it is possible to drive the request headers sent via configuration using annotation metadata.
The following example serves to illustrate this:
Defining Headers via Configuration
@Client("/pets")
@Header(name="X-Pet-Client", value="${pet.client.id}")
public interface PetClient extends PetOperations {
@Override
Single<Pet> save(String name, int age);
@Get("/{name}")
Single<Pet> get(String name);
}The above example defines a @Header annotation on the PetClient interface that reads a property using property placeholder configuration called pet.client.id.
In your application configuration you then set the following in application.yml to populate the value:
Configuring Headers in YAML
pet:
client:
id: fooAlternatively you can supply a PET_CLIENT_ID environment variable and the value will be populated.
Populating Headers using an Client Filter
Alternatively if you need the ability to dynamically populate headers an alternative is to use a Client Filter.
For more information on writing client filters see the Client Filters section of the guide.
7.2.4 Customizing Jackson Settings
As mentioned previously, Jackson is used for message encoding to JSON. A default Jackson ObjectMapper is configured and used by Micronaut HTTP clients.
You can override the settings used to construct the ObjectMapper using the properties defined by the JacksonConfiguration class in application.yml.
For example, the following configuration enabled indented output for Jackson:
Example Jackson Configuration
jackson:
serialization:
indentOutput: trueHowever, these settings apply globally and impact both how the HTTP server renders JSON and how JSON is sent from the HTTP client. Given that sometimes it useful to provide client specific Jackson settings which can be done with the @JacksonFeatures annotation on any client:
As an example, the following snippet is taken from Micronaut’s native Eureka client (which, of course, is built using Micronaut’s HTTP client):
Example of JacksonFeatures
@Client(id = EurekaClient.SERVICE_ID, path = "/eureka", configuration = EurekaConfiguration.class)
@JacksonFeatures(
enabledSerializationFeatures = WRAP_ROOT_VALUE,
disabledSerializationFeatures = WRITE_SINGLE_ELEM_ARRAYS_UNWRAPPED,
enabledDeserializationFeatures = {UNWRAP_ROOT_VALUE, ACCEPT_SINGLE_VALUE_AS_ARRAY}
)
public interface EurekaClient {
...
}The Eureka serialization format for JSON uses the WRAP_ROOT_VALUE serialization feature of Jackson, hence it is enabled just for that client.
If the customization offered by JacksonFeatures is not enough, you can also write a BeanCreatedEventListener for the ObjectMapper and add whatever customizations you need.
|
7.2.5 Retry and Circuit Breaker
Being able to recover from failure is critical for HTTP clients, and that is where the integrated Retry Advice included as part of Micronaut comes in really handy.
You can declare the @Retryable or @CircuitBreaker annotations on any @Client interface and the retry policy will be applied, for example:
Declaring @Retryable
@Client("/pets")
@Retryable
public interface PetClient extends PetOperations {
@Override
Single<Pet> save(String name, int age);
}For more information on customizing retry, see the section on Retry Advice.
7.2.6 Client Fallbacks
In distributed systems, failure happens and it is best to be prepared for it and handle it in as graceful a manner possible.
In addition, when developing Microservices it is quite common to work on a single Microservice without other Microservices the project requires being available.
With that in mind Micronaut features a native fallback mechanism that is integrated into Retry Advice that allows falling back to another implementation in the case of failure.
Using the @Fallback annotation you can declare a fallback implementation of a client that will be picked up and used once all possible retries have been exhausted.
In fact the mechanism is not strictly linked to Retry, you can declare any class as @Recoverable and if a method call fails (or, in the case of reactive types, an error is emitted) a class annotated with @Fallback will be searched for.
To illustrate this consider again the PetOperations interface declared earlier. You can define a PetFallback class that will be called in the case of failure:
Defining a Fallback
@Fallback
public class PetFallback implements PetOperations {
@Override
public Single<Pet> save(String name, int age) {
Pet pet = new Pet();
pet.setAge(age);
pet.setName(name);
return Single.just(pet);
}
}
If you purely want to use fallbacks to help with testing against external Microservices you can define fallbacks in the src/test/java directory so they are not included in production code.
|
As you can see the fallback does not perform any network operations and is quite simple, hence will provide a successful result in the case of an external system being down.
Of course, the actual behaviour of the fallback is down to you. You could for example implement a fallback that pulls data from a local cache when the real data is not available, and sends alert emails to operations about downtime or whatever.
7.2.7 Netflix Hystrix Support
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features netflix-hystrix |
Netflix Hystrix is a fault tolerance library developed by the Netflix team and designed to improve resilience of inter process communication.
Micronaut features integration with Hystrix through the netflix-hystrix module, which you can add to your build.gradle or pom.xml:
build.gradle
compile "io.micronaut.configuration:micronaut-netflix-hystrix"Using the @HystrixCommand Annotation
With the above dependency declared you can annotate any method (including methods defined on @Client interfaces) with the @HystrixCommand annotation and it will wrap the methods execution in a Hystrix command. For example:
Using @HystrixCommand
@HystrixCommand
String hello(String name) {
return "Hello $name"
}
This works for reactive return types such as Flowable etc. as well and the reactive type will be wrapped in a HystrixObservableCommand.
|
The @HystrixCommand annotation also integrates with Micronauts support for Retry Advice and Fallbacks
| For information on how to customize the Hystrix thread pool, group and properties see the javadoc for @HystrixCommand. |
Enabling Hystrix Stream & Dashboard
You can enable a Server Sent Event stream to feed into the Hystrix Dashboard by setting the hystrix.stream.enabled setting to true in application.yml:
Enabling Hystrix Stream
hystrix:
stream:
enabled: trueThis exposes a /hystrix.stream endpoint with the format the Hystrix Dashboard expects.
7.3 HTTP Client Filters
Often, you need to include the same HTTP headers or URL parameters in a set of requests against a third-party API or when calling another Microservice.
To simplify this, Micronaut includes the ability to define HttpClientFilter classes that are applied to all matching HTTP clients.
As an example say you want to build a client to communicate with the Bintray REST API. It would be terribly tedious to have to specify authentication for every single HTTP call.
To resolve this burden you can define a filter. The following is an example BintrayService:
class BintrayApi {
public static final String URL = 'https://api.bintray.com'
}
@Singleton
class BintrayService {
final RxHttpClient client
final String org
BintrayService(
@Client(BintrayApi.URL) RxHttpClient client, (1)
@Value('${bintray.organization}') String org ) {
this.client = client
this.org = org
}
Flowable<HttpResponse<String>> fetchRepositories() {
return client.exchange(HttpRequest.GET("/repos/$org"), String) (2)
}
Flowable<HttpResponse<String>> fetchPackages(String repo) {
return client.exchange(HttpRequest.GET("/repos/${org}/${repo}/packages"), String) (2)
}
}| 1 | An RxHttpClient is injected for the Bintray API |
| 2 | The organization is configurable via configuration |
The Bintray API is secured. To authenticate you need to add an Authorization header for every request. You could modify fetchRepositories and fetchPackages methods to include the necessary HTTP Header for each request. Using a filter is much simpler though:
@Filter('/repos/**') (1)
class BintrayFilter implements HttpClientFilter {
final String username
final String token
BintrayFilter(
@Value('${bintray.username}') String username, (2)
@Value('${bintray.token}') String token ) { (2)
this.username = username
this.token = token
}
@Override
Publisher<? extends HttpResponse<?>> doFilter(MutableHttpRequest<?> request, ClientFilterChain chain) {
return chain.proceed(
request.basicAuth(username, token) (3)
)
}
}| 1 | You can match only a subset of paths with a Client filter. |
| 2 | The username and token are injected via configuration |
| 3 | The basicAuth method is used include the HTTP BASIC credentials |
Now, whenever you invoke the bintrayService.fetchRepositories() method, the Authorization HTTP header is included in the request.
7.4 HTTP Client Sample
8 Cloud Native Features
The majority of frameworks in use today on the JVM were designed before the rise of cloud deployments and microservice architectures. Applications built with these frameworks were intended to be deployed to traditional Java containers. As a result, cloud support in these frameworks typically comes as an add-on rather than as core design features.
Micronaut was designed from the ground up for building microservices for the cloud. As a result, many key features that typically require external libraries or services are available within your application itself. To override one of the industry’s current favorite buzzwords, Micronaut applications are "natively cloud-native".
The following are some of the cloud-specific features that are integrated directly into the Micronaut runtime:
-
Distributed Configuration
-
Service Discovery
-
Client-Side Load-Balancing
-
Distributed Tracing
-
Serverless Functions
Many of the features in Micronaut and heavily inspired by features from Spring and Grails. This is by design and helps developers who are already familiar with systems such as Spring Cloud.
The following sections cover these features and how to use them.
8.1 Cloud Configuration
Applications that are built for the Cloud often need adapt to running in a Cloud environment, read and share configuration in a distributed manner and externalize configuration to the environment where necessary.
Micronaut’s Environment concept is by default Cloud platform aware and will make a best effort to detect the underlying active environment.
You can then use the Requires annotation to conditionally load bean definitions.
The following table summarizes the constants provided by the Environment interface and provides an example:
| Constant | Description | Requires Example |
|---|---|---|
The application is running as an Android application |
|
|
The application is running within a JUnit or Spock test |
|
|
The application is running in a Cloud environment (present for all other cloud platform types) |
|
|
Running on Amazon EC2 |
|
|
Running on Google Compute |
|
|
Running on Kubernetes |
|
|
Running on Heroku |
|
|
Running on Cloud Foundry |
|
|
Running on Microsoft Azure |
|
|
Running on IBM Cloud |
|
Note that it may be the case that you have multiple active environment names since you may run Kubernetes on AWS for example.
In addition, using the value of the constants defined in the table above you can create environment specific configuration files. For example if you create a src/main/resources/application-gcp.yml file then that configuration will only be loaded when running on Google Compute.
Any configuration property in the Environment can also be set via an environment variable. For example, setting the CONSUL_CLIENT_HOST environment variable will override the host property in ConsulConfiguration.
|
Using Cloud Instance Metadata
When Micronaut detects it is running on Google Compute or AWS EC2, upon startup Micronaut will populate the interface ComputeInstanceMetadata.
| Depending on the environment you are running in the backing implementation will be either GoogleComputeInstanceMetadata or AmazonEC2InstanceMetadata with metadata found from Google or Amazon’s metadata services. |
All of this data is merged together into the metadata property for the running ServiceInstance.
If you need to access the metadata for your application instance you can use the interface EmbeddedServerInstance, and call getMetadata() which will get a map of all of the metadata.
If you are connecting remotely via client, the instance metadata can be referenced once you have retrieved a ServiceInstance from either the LoadBalancer or DiscoveryClient APIs.
| The Netflix Ribbon client side load balancer can be configured to use the metadata to do zone aware client side load balancing. See Client Side Load Balancing |
To obtain metadata for a service via Service Discovery use the LoadBalancerResolver interface to resolve a LoadBalancer and obtain a reference to a service by identifier:
Obtaining Metadata for a Service instance
LoadBalancer loadBalancer = loadBalancerResolver.resolve("some-service");
Flowable.fromPublisher(
loadBalancer.select()
).subscribe((instance) ->
ConvertibleValues<String> metaData = instance.getMetadata();
...
);To obtain metadata for the locally running server use the EmbeddedServerInstance interface:
Obtaining Metadata for a Local Server
EmbeddedServerInstance serverInstance = applicationContext.getBean(EmbeddedServerInstance.class);
ConvertibleValues<String> metaData = serverInstance.getMetadata();8.1.1 Distributed Configuration
As you can see, Micronaut features a robust system for externalizing and adapting configuration to the environment inspired by similar approaches found in Grails and Spring Boot.
However, what if you want two Microservices to share configuration? Micronaut comes with built in APIs for doing distributed configuration.
The ConfigurationClient interface has a single method called getPropertySources that can be implemented to read and resolve configuration from distributed sources.
The getPropertySources returns a Publisher that emits zero or many PropertySource instances.
The default implementation is DefaultCompositeConfigurationClient which merges all registered ConfigurationClient beans into a single bean.
You can either implement your own ConfigurationClient implementation or you can use one of the ones already built into Micronaut. The following sections cover those.
8.1.2 Consul Support
Consul is a popular Service Discovery and Distributed Configuration server provided by HashiCorp. Micronaut features a native ConsulClient that is built using Micronaut’s support for Declarative HTTP Clients.
Starting Consul
The quickest way to start using Consul is via Docker:
-
Starting Consul with Docker
docker run -p 8500:8500 consul
Alternatively you can install and run a local Consul instance.
Enabling Distributed Configuration with Consul
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features config-consul |
To enable distributed configuration, similar to Spring Boot and Grails, you need to create a src/main/resources/bootstrap.yml configuration file and configure Consul as well as enable the configuration client:
bootstrap.yml
micronaut:
application:
name: hello-world
config-client:
enabled: true
consul:
client:
defaultZone: "${CONSUL_HOST:localhost}:${CONSUL_PORT:8500}"Once you have enabled distributed configuration you need to store the configuration you wish the share in Consul’s Key/Value store.
There are a number of different ways to do that.
Storing Configuration as Key/Value Pairs
One way is to store each key and value directly in Consul. In this case by default Micronaut will look for configuration in the /config folder of Consul.
You can alter the path searched for by setting consul.client.config.path
|
Within the /config folder Micronaut will search values within the following folders in order of precedence:
| Folder | Description |
|---|---|
|
Configuration shared by all applications |
|
Configuration shared by all applications for the |
|
Application specific configuration, example |
|
Application specific configuration for an active Environment |
The value of APPLICATION_NAME is whatever your have configured micronaut.application.name to be in bootstrap.yml.
To see this in action use the following curl command to store a property called foo.bar with a value of myvalue in the folder /config/application.
Using curl to Write a Value
curl -X PUT -d @- localhost:8500/v1/kv/config/application/foo.bar <<< myvalueIf you know define a @Value("${foo.bar}") or call environment.getProperty(..) the value myvalue will be resolved from Consul.
Storing Configuration in YAML, JSON etc.
Some Consul users prefer storing configuration in blobs of a certain format, such as YAML. Micronaut supports this mode and supports storing configuration in either YAML, JSON or Java properties format.
| The ConfigDiscoveryConfiguration has a number of configuration options for configuring how distributed configuration is discovered. |
You can set the consul.client.config.format option to configure the format with which properties are read.
For example, to configure JSON:
application.yml
consul:
client:
config:
format: JSONNow write your configuration in JSON format to Consul:
Using curl write JSON
curl -X PUT localhost:8500/v1/kv/config/application \
-d @- << EOF
{ "foo": { "bar": "myvalue" } }
EOFStoring Configuration as File References
Another option popular option is git2consul which mirrors the contents of a Git repository to Consul’s Key/Value store.
You can setup a Git repository that contains files like application.yml, hello-world-test.json etc. and the contents of these files are cloned to Consul.
In this case each key in consul represents a file with an extension. For example /config/application.yml and you must configure the FILES format:
application.yml
consul:
client:
config:
format: FILES8.1.3 AWS Parameter Store Support
Micronaut supports configuration sharing via AWS System Manager Parameter Store. You will need the following dependencies configured:
Example
build.gradle for AWS System Manager Parameter Storecompile "io.micronaut:micronaut-discovery-client"
compile "io.micronaut.configuration:micronaut-aws-common"
compile group: 'com.amazonaws', name: 'aws-java-sdk-ssm', version: '1.11.308'You can configure shared properties by going into the AWS Console → System Manager → Parameter Store
Micronaut will use a hierarchy to read the configuration values, and supports String, StringList, and SecureString types.
You can make environment specific configurations as well by including the environment name after an underscore _. For example if your micronaut.application.name setting is set to helloworld then providing configuration values under helloworld_test will be applied only to the test environment.
For example:
Names as Hierarchy
application/
/specialConfig
application_test/
/specialConfig2
application_dev
/specialDevConfig
Each level of the tree can be composed of key=value pairs. If you want multiple key value pairs, set the type to 'StringList'.
For special secure information, like keys or passwords, use the type "SecureString". KMS will be automatically invoked when you add and retrieve values and decrypt them with the default key store for your account. If you set the configuration to not use secure strings, they will be returned to you encrypted and you must manually decrypt them.
The following is an example configuration in application.yml:
Configuration Properties Example
aws:
client:
system-manager:
parameterstore:
# true/false will turn on or off this feature
enabled: true
# true/false - ask AWS to automatically decrypt SecureString type with KMS
useSecureParameters: true
# String - you can use a custom root path the application will look for configurations in. The default is '/config/application'.
rootHierarchyPath: /config/application8.2 Service Discovery
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply either of $ mn create-app my-app --features discovery-consul |
Service Discovery enables the ability for Microservices to find each other without necessarily knowing the physical location or IP address of associated services.
There are many ways Service Discovery can be implemented, including:
-
Manually implement Service Discovery using DNS without requiring a third party tool or component.
-
Delegate the work to a container runtime, such as Kubernetes.
With that in mind, Micronaut tries to flexible to support all of these approaches. As of this writing, Micronaut features integrated support for the popular Service Discovery servers:
-
Eureka
-
Consul
To include Service Discovery in your application simply the first step is to add the discovery-client dependency to your application:
build.gradle
compile "io.micronaut:micronaut-discovery-client"The discovery-client dependency provides implementations of the DiscoveryClient interface.
The DiscoveryClient is fairly simple and provides two main entry points:
-
DiscoveryClient.getServiceIds() - Returns all discovered service IDs
-
DiscoveryClient.getInstances(java.lang.String) - Returns all the ServiceInstance objects for a given service ID
Both methods return Publisher instances since the operation to retrieve service ID information may result in a blocking network call depending on the underlying implementation.
The default implementation of the DiscoveryClient interface is CachingCompositeDiscoveryClient which merges all other DiscoveryClient beans into a single bean and provides caching of the results of the methods. The default behaviour is to cache for 30 seconds. This cache can be disabled in application configuration:
Disabling the Discovery Client Cache
micronaut:
caches:
discovery-client:
enabled: falseAlternatively you can alter the cache’s expiration policy:
Configuring the Discovery Client Cache
micronaut:
caches:
discovery-client:
expire-after-access: 60sSee the DiscoveryClientCacheConfiguration class for available configuration options.
8.2.1 Consul Support
Consul is a popular Service Discovery and Distributed Configuration server provided by HashiCorp. Micronaut features a native non-blocking ConsulClient that is built using Micronaut’s support for Declarative HTTP Clients.
Starting Consul
The quickest way to start using Consul is via Docker:
-
Starting Consul with Docker
docker run -p 8500:8500 consul
Alternatively you can install and run a local Consul instance.
Auto Registering with Consul
To register a Micronaut application with Consul simply add the necessary ConsulConfiguration. A minimal example can be seen below:
Auto Registering with Consul (application.yml)
micronaut:
application:
name: hello-world
consul:
client:
registration:
enabled: true
defaultZone: "${CONSUL_HOST:localhost}:${CONSUL_PORT:8500}"
Using the Micronaut CLI you can quickly create a new service setup with Consul using: mn create-app my-app --features discovery-consul
|
The consul.client.defaultZone settings accepts a list of Consul servers to be used by default.
You could also simply set consul.client.host and consul.client.port, however ConsulConfiguration allows you specify per zone discovery services for the purpose load balancing. A zone maps onto a AWS availability zone or a Google Cloud zone.
|
By default registering with Consul is disabled hence you should set consul.client.registration.enabled to true. Note that you may wish to do this only in your production configuration.
| Running multiple instances of a service may require an additional configuration param. See below. |
If you are running the same applications on the same port across different servers it is important to set the micronaut.application.instance.id property or you will experience instance registration collision.
micronaut:
application:
name: hello-world
instance:
id: ${random.shortuuid}Customizing Consul Service Registration
The ConsulConfiguration class features a range of customization options for altering how an instance registers with Consul. You can customize the tags, the retry attempts, the fail fast behaviour and so on.
Notice too that ConsulConfiguration extends DiscoveryClientConfiguration which in turn extends HttpClientConfiguration allowing you to customize the settings for the Consul client, including read timeout, proxy configuration and so on.
For example:
Customizing Consul Registration Configuration
micronaut:
application:
name: hello-world
consul:
client:
registration:
enabled: true
# Alters the tags
tags:
- hello
- world
# Alters the retry count
retry-count: 5
# Alters fail fast behaviour
fail-fast: false
defaultZone: "${CONSUL_HOST:localhost}:${CONSUL_PORT:8500}"Discovery Services from Consul
To discovery other services you could manually interact with the DiscoveryClient, however typically instead you use the Client Annotation to declare how an HTTP client maps to a service.
For example the configuration in the previous section declared a value for micronaut.application.name of hello-world. This is the value that will be used as the service ID when registering with Consul.
Other services can discovery instances of the hello-world service simply by declaring a client as follows:
Using @Client to Discover Services
@Client(id = "hello-world")
interface HelloClient{
...
}Alternatively you can also use @Client as a qualifier to @Inject an instance of HttpClient:
Using @Client to Discover Services
@Client(id = "hello-world")
@Inject
RxHttpClient httpClient;Consul Health Checks
By default when registering with Consul Micronaut will register a TTL check. A TTL check basically means that if the application does not send a heartbeat back to Consul after a period of time the service is put in a failing state.
Micronaut applications feature a HeartbeatConfiguration which starts a thread using HeartbeatTask that fires HeartbeatEvent instances.
The ConsulAutoRegistration class listens for these events and sends a callback to the /agent/check/pass/:check_id endpoint provided by Consul, effectively keeping the service alive.
With this arrangement the responsibility is on the Micronaut application to send TTL callbacks to Consul on a regular basis.
If you prefer you can push the responsibility for health checks to Consul itself by registering an HTTP check:
Consul HTTP Check Configuration
consul:
client:
registration:
check:
http: trueWith this configuration option in place Consul will assume responsibility of invoking the Micronaut applications Health Endpoint.
8.2.2 Eureka Support
Netflix Eureka is a popular discovery server deployed at scale at organizations like Netflix.
Micronaut features a native non-blocking EurekaClient as part of the discovery-client module that does not require any additional third-party dependencies and is built using Micronaut’s support for Declarative HTTP Clients.
Starting Eureka
The quickest way to start a Eureka server is to use to use Spring Boot’s Eureka starters.
| As of this writing the Docker images for Eureka are significantly out-of-date so it is recommended to create a Eureka server following the steps above. |
Auto Registering with Eureka
The process to register a Micronaut application with Eureka is very similar to with Consul, as seen in the previous section, simply add the necessary EurekaConfiguration. A minimal example can be seen below:
Auto Registering with Eureka (application.yml)
micronaut:
application:
name: hello-world
eureka:
client:
registration:
enabled: true
defaultZone: "${EUREKA_HOST:localhost}:${EUREKA_PORT:8761}"Customizing Eureka Service Registration
You can customize various aspects of registration with Eureka using the EurekaConfiguration. Notice that EurekaConfiguration extends DiscoveryClientConfiguration which in turn extends HttpClientConfiguration allowing you to customize the settings for the Eureka client, including read timeout, proxy configuration and so on.
Example Eureka Configuration
eureka:
client:
readTimeout: 5s
registration:
asgName: myAsg # the auto scaling group name
countryId: 10 # the country id
vipAddress: 'myapp' # The Eureka VIP address
leaseInfo:
durationInSecs: 60 # The lease information
metadata: # arbitrary instance metadata
foo: bar
retry-count: 10 # How many times to retry
retry-delay: 5s # How long to wait between retries| Property | Type | Description |
|---|---|---|
|
java.time.Duration |
|
|
boolean |
|
|
boolean |
|
|
boolean |
|
|
int |
|
|
java.time.Duration |
|
|
java.lang.String |
Eureka Basic Authentication
You can customize the Eureka credentials in the URI you specify to in defaultZone.
For example:
Auto Registering with Eureka
eureka:
client:
defaultZone: "https://${EUREKA_USERNAME}:${EUREKA_PASSWORD}@localhost:8761"The above example externalizes configuration of the username and password Eureka to environment variables called EUREKA_USERNAME and EUREKA_PASSWORD.
Eureka Health Checks
Like Consul, the EurekaAutoRegistration will send HeartbeatEvent instances with the HealthStatus of the Micronaut application to Eureka.
The HealthMonitorTask will by default continuously monitor the HealthStatus of the application by running health checks and the CurrentHealthStatus will be sent to Eureka.
Secure Communication with Eureka
If you wish to configure HTTPS and have clients discovery Eureka instances and communicate over HTTPS then you should set the eureka.client.discovery.use-secure-port option to true to ensure that service communication happens over HTTPS and also configure HTTPS appropriately for each instance.
8.2.3 Kubernetes Support
Kubernetes is a container runtime which has a whole bunch of features including integrated Service Discovery. The strategy for Service Discovery in Kubernetes is pretty simple in that for each Pod, Kubernetes will expose environment variables in the format [SERVICE_NAME]_SERVICE_HOST and [SERVICE_NAME]_SERVICE_PORT.
Micronaut features a KubernetesDiscoveryClient that simply looks at the environment variables and translates those into the available services.
For example given a service exposed as HELLO_WORLD_SERVICE_HOST to your application, you can declare clients that will be automatically discovered using:
Using @Client to Discover Services
@Client(id = "hello-world")
interface HelloClient{
...
}Since Kubernetes itself assumes responsibility for tasks such as health checks, load balancing and so on there is no need to send HeartbeatEvent instances and so on.
8.2.4 AWS Route 53 Support
To use the Route 53 Service Discovery, you must meet the following criteria:
-
Run EC2 instances of some type
-
Have a domain name hosted in Route 53
-
Have a newer version of AWS-CLI (such as 14+)
Assuming you have those things, you are ready. It is not as fancy as Consul or Eureka, but other than some initial setup with the AWS-CLI, there is no other software running to go wrong. You can even support health checks if you add a custom health check to your service. If you would like to test if your account can create and use Service Discovery see the Integration Test section. More information can be found at https://docs.aws.amazon.com/Route53/latest/APIReference/overview-service-discovery.html.
Here are the steps:
-
Use AWS-CLI to create a namespace. You can make either a public or private one depending on what IPs or subnets you are using
-
Create a service with DNS Records with AWS-CLI command
-
Add health checks or custom health checks (optional)
-
Add Service ID to your application configuration file like so:
Sample application.yml
aws:
route53:
registration
enabled: true
aws-service-id: srv-978fs98fsdf
namespace: micronaut.io
micronaut:
application:
name: something-
Make sure you have the following dependencies included in your build file:
Sample build.gradle
compile "io.micronaut:micronaut-discovery-client"
compile "io.micronaut.configuration:micronaut-aws-common"
compile group: 'com.amazonaws', name: 'aws-java-sdk-route53', version: '1.11.297'
compile group: 'com.amazonaws', name: 'aws-java-sdk-core', version: '1.11.297'
compile group: 'com.amazonaws', name: 'jmespath-java', version: '1.11.297'
compile group: 'com.amazonaws', name: 'aws-java-sdk-servicediscovery', version: '1.11.297'-
On the client side, you will need the same dependencies and less configuration options:
Sample application.yml
aws:
route53:
discovery:
client:
enabled: true
aws-service-id: srv-978fs98fsdf
namespace-id: micronaut.ioYou can then use the DiscoveryClient API to find other services registered via Route 53. For example:
Sample code for client
DiscoveryClient discoveryClient = embeddedServer.applicationContext.getBean(DiscoveryClient);
List<String> serviceIds = Flowable.fromPublisher(discoveryClient.getServiceIds()).blockingFirst();
List<ServiceInstance> instances = Flowable.fromPublisher(discoveryClient.getInstances(serviceIds.get(0))).blockingFirst();Creating the Namespace
Namespaces are similar to a regular Route53 hosted zone, and they appear in the Route53 console but the console doesn’t support modifying them. You must use the AWS-CLI at this time for any Service Discovery functionality.
First decide if you are creating a public facing namespace or a private one, as the commands are different:
Creating Namespace
$ aws servicediscovery create-public-dns-namespace --name micronaut.io --create-request-id create-1522767790 --description adescrptionhere
or
$ aws servicediscovery create-private-dns-namespace --name micronaut.internal.io --create-request-id create-1522767790 --description adescrptionhere --vpc yourvpcIDWhen you run this you will get an operation ID. You can check the status with the get-operation CLI command:
Get Operation Results
$ aws servicediscovery get-operation --operation-id asdffasdfsdaYou can use this command to get the status of any call you make that returns an operation id.
The result of the command will tell you the ID of the namespace. Write that down, you’ll need it for the next steps. If you get an error it will say what the error was.
Creating the Service & DNS Records
The next step is creating the Service and DNS records.
Create Service
$ aws create-service --name yourservicename --create-request-id somenumber --description someservicedescrption --dns-config NamespaceId=yournamespaceid,RoutingPolicy=WEIGHTED,DnsRecords=[{Type=A,TTL=1000},{Type=A,TTL=1000}]The DnsRecord type can be A(ipv4),AAAA(ipv6),SRV, or CNAME. RoutingPolicy can be WEIGHTED or MULTIVALUE. Keep in mind CNAME must use weighted routing type, SRV must have a valid port configured.
If you want to add a health check, you can use the following syntax on the CLI:
Specifying a Health Check
Type=string,ResourcePath=string,FailureThreshold=integerType can be 'HTTP','HTTPS', or 'TCP'. You can only use a standard health check on a public namespace. See Custom Health Checks for private namespaces. Resource path should be a url that returns 200 OK if it’s healthy.
For a custom health check, you only need to specify --health-check-custom-config FailureThreshold=integer which will work on private namespaces as well.
This is also good because Micronaut will send out pulsation commands to let AWS know the instance is still healthy.
For more help run 'aws discoveryservice create-service help'.
You will get a service ID and an ARN back from this command if successful. Write that down, it’s going to go into the Micronaut configuration.
Setting up the configuration in Micronaut
Auto Naming Registration
You will need to add the configuration to make your applications register with Route 53 Auto-discovery:
Registration Properties
aws:
route53:
registration:
enabled: true
aws-service-id=<enter the service id you got after creation on aws cli>
discovery:
namespace-id=<enter the namespace id you got after creating the namespace>Discovery Client Configuration
Discovery Properties
aws:
route53:
discovery:
client
enabled: true
aws-service-id: <enter the service id you got after creation on aws cli>You can also call the following methods by getting the bean "Route53AutoNamingClient":
Discovery Methods
// if serviceId is null it will use property "aws.route53.discovery.client.awsServiceId"
Publisher<List<ServiceInstance>> getInstances(String serviceId)
// reads property "aws.route53.discovery.namespaceId"
Publisher<List<String>> getServiceIds()Integration Tests
If you set the environment variable AWS_SUBNET_ID and have credentials configured in your home directory that are valid (in ~/.aws/credentials)
you can run the integration tests. You will still need a domain hosted on route53 as well. This test will create a t2.nano instance, a namespace, service, and register that instance to service discovery.
When the test completes it will remove/terminate all resources it spun up.
8.2.5 Manual Service Discovery Configuration
If you do not wish to involve a service discovery server like Consul or you are interacting with a third-party service that cannot register with Consul you can instead manually configure services that are available via Service discovery.
To do this you should use the micronaut.http.services setting. The following is an example configuration:
Manually configuring services
micronaut:
http:
services:
foo:
urls:
- http://foo1
- http://foo2You can then inject a client with @Client("foo") and it will use the above configuration to load balance between the two configured servers.
WARN: This client configuration can be used in conjunction with the @Client annotation, either by injecting an HttpClient directly or use on a client interface. In any case, all other attributes on the annotation will be ignored other than the service id.
You can override this configuration in production by specifying an environment variable such as MICRONAUT_HTTP_SERVICES_FOO_URLS=http://prod1,http://prod2
|
Note that by default no health checking will happen to assert that the referenced services are operational. You can alter that by enabling health checking and optionally specifying a health check path (the default is /heath):
Enabling Health Checking
micronaut:
http:
services:
foo:
...
health-check: true (1)
health-check-interval: 15s (2)
health-check-uri: /health (3)| 1 | Whether to health check the service |
| 2 | The interval to wait between checks |
| 3 | The URI to send the health check request to |
Micronaut will start a background thread to check the health status of the service and if any of the configured services respond with an error code, they will be removed from the list of available services.
8.3 Client Side Load Balancing
When discovering services from Consul, Eureka or other Service Discovery servers the DiscoveryClient will emit a list of available ServiceInstance.
Micronaut by default will automatically perform Round Robin client-side load balancing using the servers in this list. This combined with Retry Advice adds extra resiliency to your Microservice infrastructure.
The load balancing itself is handled by the LoadBalancer interface which defines a LoadBalancer.select() method that returns a Publisher that emits a ServiceInstance.
The Publisher is returned because the process for selecting a ServiceInstance may result in a network operation depending on the Service Discovery strategy employed.
The default implementation of the LoadBalancer interface is DiscoveryClientRoundRobinLoadBalancer. You can replace this strategy for another implementation if you wish to customize how client side load balancing is handled in Micronaut since there are many different ways you may wish to optimize load balancing.
For example, you may wish to load balance between services in a particular zone or you may wish to load balance between servers that have the best overall response time.
To replace the LoadBalancer used you should define a bean that replaces the DiscoveryClientLoadBalancerFactory.
In fact that is exactly what the Netflix Ribbon support does, described in the next section.
8.3.1 Netflix Ribbon Support
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features netflix-ribbon |
Netflix Ribbon is a inter-process communication library used at Netflix that has support for customizable load balancing strategies.
If you need more flexibility in how your application performs client-side load balancing then you may wish use Micronaut’s Netflix Ribbon support.
To add Ribbon support to your application add the netflix-ribbon configuration to build.gradle or pom.xml:
build.gradle
compile "io.micronaut.configuration:micronaut-netflix-ribbon"The LoadBalancer implementations will now be RibbonLoadBalancer instances.
Ribbon’s Configuration options can be set using the ribbon namespace in configuration. For example in application.yml:
Configuring Ribbon
ribbon:
VipAddress: test
ServerListRefreshInterval: 2000Each discovered client can also be configured under ribbon.clients. For example given a @Client(id = "hello-world") you can configure Ribbon settings with:
Per Client Ribbon Settings
ribbon:
clients:
hello-world:
VipAddress: test
ServerListRefreshInterval: 2000By default Micronaut registers a DiscoveryClientServerList for each client that integrates Ribbon with Micronaut’s DiscoveryClient.
8.4 Distributed Tracing
When operating Microservices in production it can be challenging to troubleshoot interactions between Microservices in a distributed architecture.
To solve this problem a way to visualize interactions between Microservices in a distributed manner can be critical. Currently, there are various distributed tracing solutions, the most popular of which are Zipkin and Jaeger both of which provide different levels of support for the Open Tracing API.
Micronaut features integration with both Zipkin and Jaeger (via the Open Tracing API).
To enable tracing you should add the tracing module to your build.gradle or pom.xml file:
build.gradle
compile "io.micronaut:micronaut-tracing"Tracing Annotations
The io.micronaut.tracing.annotation package contains annotations that can be declared on methods to create new spans or continue existing spans.
The available annotations are:
-
The @NewSpan annotation will create a new span, wrapping the method call or reactive type.
-
The @ContinueSpan annotation will continue an existing span, wrapping the method call or reactive type.
-
The @SpanTag annotation can be used on method arguments to include the value of each argument within a Span’s tags. When you use
@SpanTagon a method argument, you need either to annotate the method with@NewSpanor@ContinueSpan.
The following snippet presents an example of using the annotations:
Using Trace Annotations
@Singleton
class HelloService {
@NewSpan("hello-world") (1)
public String hello(@SpanTag("person.name") String name) { (2)
return greet("Hello " + name);
}
@ContinueSpan (3)
public String greet(@SpanTag("hello.greeting") String greet) {
return greeting;
}
}| 1 | The @NewSpan annotation is used to start a new span |
| 2 | You can use @SpanTag to include arguments of methods as tags for the span |
| 3 | The @ContinueSpan annotation can be used to continue as existing span and incorporate additional tags using @SpanTag |
Tracing Instrumentation
In addition to explicit tracing tags, Micronaut includes a number of instrumentations to ensure that the Span context is propagated between threads and across Microservice boundaries.
These instrumentations are found in the io.micronaut.tracing.instrument package and include HTTP Client Filters and Server Filters to propagate the necessary headers via HTTP.
Tracing Beans
If the Tracing annotations and existing instrumentations are not enough, Micronaut’s tracing integration registers a io.opentracing.Tracer bean that can be injected into any class and exposes the Open Tracing API.
Depending on the implementation you choose there are also additional beans. For example for Zipkin brave.Tracing and brave.SpanCustomizer beans are available too.
8.4.1 Tracing with Zipkin
Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in microservice architectures. It manages both the collection and lookup of this data.
Running Zipkin
The quickest way to get up and started with Zipkin is with Docker:
Running Zipkin with Docker
$ docker run -d -p 9411:9411 openzipkin/zipkinYou can then open a browser tab to the location http://localhost:9411 to view traces.
Sending Traces to Zipkin
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features tracing-zipkin |
To send tracing spans to Zipkin the minimal configuration requires you add the following dependencies to build.gradle or pom.xml:
Adding Zipkin Dependencies
runtime 'io.zipkin.brave:brave-instrumentation-http'
runtime 'io.zipkin.reporter2:zipkin-reporter'
compile 'io.opentracing.brave:brave-opentracing'Then you need to enable ZipKin tracing in your configuration (potentially only your production configuration):
application.yml
tracing:
zipkin:
enabled: true
Or alternatively if you have the Micronaut CLI installed you can configure Zipkin when creating your service with: mn create-app hello-world --features tracing-zipkin
|
Customizing the Zipkin Sender
In order to send spans you need to configure a Zipkin sender. You can configure a HttpClientSender that sends Spans asynchronously using Micronaut’s native HTTP client using the tracing.zipkin.http.url setting:
Configuring Multiple Zipkin Servers
tracing:
zipkin:
enabled: true
http:
url: http://localhost:9411It is unlikely that sending spans to localhost will be suitable for production deployment so you generally will want to configure the location of one or many Zipkin servers for production:
Configuring Multiple Zipkin Servers
tracing:
zipkin:
enabled: true
http:
urls:
- http://foo:9411
- http://bar:9411
In production, setting TRACING_ZIPKIN_HTTP_URLS environment variable with a comma separated list of URLs will also work.
|
Alternatively if you wish to use a different zipkin2.reporter.Sender implementation, you can simply define a bean that is of type zipkin2.reporter.Sender and it will be picked up.
Zipkin Configuration
There are many configuration options available for the Brave client that sends Spans to Zipkin and they are generally exposed via the BraveTracerConfiguration class. You can refer to the javadoc for all the available options.
Below is an example of customizing Zipkin configuration:
Customizing Zipkin Configuration
tracing:
zipkin:
enabled: true
traceId128Bit: true
sampler:
probability: 1You can also optionally dependency inject common configuration classes into BraveTracerConfiguration such as brave.sampler.Sampler just by defining them as beans. See the API for BraveTracerConfiguration for available injection points.
8.4.2 Tracing with Jaeger
Jaeger is another distributed tracing system developed at Uber that is more or less the reference implementation for Open Tracing.
Running Jaeger
The easiest way to get started with Jaeger is to run Jaeger via Docker:
$ docker run -d \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 9411:9411 \
jaegertracing/all-in-one:1.6You can then navigate to http://localhost:16686 to access the Jaeger UI.
See Getting Started with Jaeger for more information.
Sending Traces to Jaeger
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features tracing-jaeger |
To send tracing spans to Jaeger the minimal configuration requires you add the following dependencies to build.gradle or pom.xml:
Adding Jaeger Dependencies
compile 'io.jaegertracing:jaeger-thrift:0.31.0'Then you need to enable Jaeger tracing in your configuration (potentially only your production configuration):
application.yml
tracing:
jaeger:
enabled: trueBy default Jaeger will be configured to send traces to a locally running Jaeger agent.
Or alternatively if you have the Micronaut CLI installed you can configure Zipkin when creating your service with: mn create-app hello-world --features tracing-jaeger
|
Jaeger Configuration
There are many configuration options available for the Jaeger client that sends Spans to Jaeger and they are generally exposed via the JaegerConfiguration class. You can refer to the javadoc for all the available options.
Below is an example of customizing JaegerConfiguration configuration:
Customizing Zipkin Configuration
tracing:
jaeger:
enabled: true
sampler:
probability: 0.5
sender:
agentHost: foo
agentPort: 5775
reporter:
flushInterval: 2000
maxQueueSize: 200You can also optionally dependency inject common configuration classes into JaegerConfiguration such as io.jaegertracing.Configuration.SamplerConfiguration just by defining them as beans. See the API for JaegerConfiguration for available injection points.
9 Serverless Functions
Server-less architectures where as a developer you deploy functions that are fully managed by the Cloud environment and are executed in ephemeral processes require a unique approach.
Traditional frameworks like Grails and Spring are not really suitable since low memory consumption and fast startup time are critical, since the Function as a Service (FaaS) server will typically spin up your function for a period using a cold start and then keep it warm.
Micronaut’s compile-time approach, fast startup time and low-memory footprint make it a great candidate for using as a framework for developing functions and in fact Micronaut features dedicated support for developing and deploying functions to AWS Lambda and any FaaS system that supports running functions as containers (such as OpenFaaS, Rift or Fn).
9.1 Writing Functions
|
Using the CLI
If you are creating your project using the Micronaut CLI, use the |
To get started writing serverless function you must add the appropriate Micronaut function dependency to your classpath. In certain cases there are FaaS platform specific extension which you may wish to include. The following table includes the dependencies for each individual FaaS platform:
| Provider | Dependency |
|---|---|
AWS Lambda |
|
If you are using Groovy, there is a single compile-time dependency to be added: "io.micronaut:micronaut-function-groovy" Please see Groovy Functions.
|
Add the appropriate dependency to your project, For example, in build.gradle:
Example build.gradle
dependencies {
...
compile "io.micronaut:micronaut-function-aws"
...
}9.1.1 FunctionApplication
| This section applies to Java & Kotlin functions - for functions written in Groovy, see Groovy Functions. |
In order to enable Micronaut’s DI features in a deployed function, your project’s main class must be set to the FunctionApplication class. Typically this will be done in your build.gradle or pom.xml files, as seen in the examples below:
Example build.gradle
mainClassName = "io.micronaut.function.executor.FunctionApplication"Example pom.xml
<project>
<properties>
<exec.mainClass>io.micronaut.function.executor.FunctionApplication</exec.mainClass>
</properties>
</project>9.1.2 FunctionBean
| This section applies to Java & Kotlin functions - for functions written in Groovy, see Groovy Functions |
To write your function’s behavior, annotate your class with the @FunctionBean annotation. Your class must also implement one of the interfaces from the java.util.function package.
If you have the Micronaut CLI installed you can quickly create a Java function with mn create-function hello-world or mn create-function hello-world --lang kotlin for Kotlin
|
The following examples implement Java’s Supplier functional interface.
Example Java Function
package example;
import io.micronaut.function.FunctionBean;
import java.util.function.Supplier;
@FunctionBean("hello-world-java")
public class HelloJavaFunction implements Supplier<String> {
@Override
public String get() { (1)
return "Hello world!";
}
}| 1 | Override the get method of Supplier to return the response from your function. |
Alternatively you can also define a Factory that returns a Java lambda:
Example Java Function as a Lambda
package example;
import io.micronaut.context.annotation.*;
import io.micronaut.function.FunctionBean;
import java.util.function.Supplier;
@Factory (1)
public class MyFunctions {
@FunctionBean("hello-world-java")
public Supplier<String> helloWorld() { (2)
return () -> "Hello world!";
}
}| 1 | A Factory bean is defined |
| 2 | The @FunctionBean annotation is used on a method that returns the function. |
If you are using Kotlin then process is exactly the same:
Example Kotlin Function
package example
import io.micronaut.function.FunctionBean
import java.util.function.Supplier
@FunctionBean("hello-world-kotlin")
class HelloKotlinFunction : Supplier<String> {
override fun get(): String { (1)
return "Hello world!"
}
}| 1 | Override the get method of Supplier to return the response from your function. |
The following table summarizes the supported interfaces:
| Interface | Dependency |
|---|---|
Accepts no arguments and returns a single result |
|
Accepts a single argument and returns no result |
|
Accepts two arguments and returns no result |
|
Accepts a single argument and returns a single result |
|
Accepts two arguments and returns a single result |
In addition, functions have an input and/or an output. The input is represented by the accepted argument and represents the body consumed by the function and the output is represented by the return value of the function. The input and the output should be either a Java primitive or simple type (int, String etc.) or a POJO.
Often, you want to accept a POJO and return a POJO. Use java.util.function.Function to accept a single argument and return a single result.
import io.micronaut.function.FunctionBean;
import java.util.function.Function;
@FunctionBean("isbn-validator")
public class IsbnValidatorFunction implements Function<IsbnValidationRequest, IsbnValidationResponse> {
@Override
public IsbnValidationResponse apply(IsbnValidationRequest request) {
return new IsbnValidationResponse();
}
}A single project can define multiple functions, however only a single function should be configured for execution by the application. This can be configured using the micronaut.function.name property in application.yml:
Configuring the Function Name to Execute
micronaut:
function:
name: hello-world-javaAlternatively you can specify the value when running your function (for example in the Dockerfile) either as an environment variable:
Specifying the Function to Execute as a Environment variable
$ export MICRONAUT_FUNCTION_NAME=hello-world-java
$ java -jar build/libs/hello-world-function-all.jarOr as a system property:
Specifying the Function to Execute as a System property
$ java -Dmicronaut.function.name=hello-world-java -jar build/libs/hello-world-function-all.jar9.1.3 Groovy Functions
As is typical in Groovy, writing functions is much simpler than in Java or Kotlin.
If you have the Micronaut CLI installed you can quickly create a Groovy function with mn create-function hello-world --lang groovy
|
To begin, add the function-groovy dependency (instead of the provider-specific dependency) which provides additional AST transformations that make writing functions simpler. For example, in build.gradle:
Example build.gradle
dependencies {
...
compile "io.micronaut:micronaut-function-groovy"
...
}You can now create your function as a Groovy script, under src/main/groovy. You will set your project’s main class property to this function (instead of FunctionApplication as in Java/Kotlin). For example:
Example build.gradle
mainClassName = "example.HelloGroovyFunction"HelloGroovyFunction.groovy
String hello(String name) {
"Hello ${name}!"
}The function you define should follow the following rules:
-
Define no more than 2 inputs
-
Use either Java primitive or simple types or POJOs as the arguments and return values
In order to make use of dependency injection in your Groovy function, use the groovy.transform.Field annotation transform in addition to the @Inject annotation.
HelloGroovyFunction.groovy
import groovy.transform.Field
import javax.inject.Inject
@Field @Inject HelloService helloService
String hello(String name) {
helloService.hello(name)
}9.2 Running Functions
Typically function applications will be run in a cloud-based environment, such as AWS Lambda. However during development and testing it is often desirable to run your functions locally, either as standalone web applications or as executables from the command line. Micronaut provides support for both of these approaches.
9.2.1 Functions as Web Applications
To run your function as a web application as described in this section, you will need the function-web dependency on your classpath. For example, in build.gradle
build.gradle
dependencies {
...
runtime "io.micronaut:micronaut-function-web"
runtime "io.micronaut:micronaut-http-server-netty" (1)
...
}| 1 | In order to run the function as a web application, you will need an HTTP server, such as the http-server-netty dependency |
Once the dependencies have been added to the project, you can run the function via an Application class.
Example Application class
import io.micronaut.runtime.Micronaut;
public class Application {
public static void main(String[] args) {
Micronaut.run(Application.class);
}
}You can now make requests against the function with a REST client.
$ curl -X GET http://localhost:8080/hello
The URI mapped to is defined by the either the value of the @FunctionBean annotation for Java or, in the case of Groovy, the name of the function defined in the function script. The following tables summarizes the convention:
| Annotation | URI |
|---|---|
|
|
|
|
|
|
| Method Name | URI |
|---|---|
|
|
|
|
Functions that only return a value are mapped to HTTP GET requests, whilst functions that accept an input require an HTTP POST.
In addition, the function will be registered by the configured Service Discovery provider, and be made accessible to clients via the @FunctionClient annotation.
For further information on the use of @FunctionClient, please see Calling Functions.
|
Testing Functions
Functions can also be run as part of the Micronaut application context for ease of testing. Similarly to the example above, this approach requires the function-web and an HTTP server dependency on the classpath for tests. For example, in build.gradle:
build.gradle
dependencies {
...
testRuntime "io.micronaut:micronaut-function-web"
testRuntime "io.micronaut:micronaut-http-server-netty" (1)
...
}| 1 | In order to run the function as a web application, you will need an HTTP server, such as the http-server-netty dependency |
Create a @FunctionClient interface as shown below:
MathClient.groovy
import io.micronaut.function.client.FunctionClient
import javax.inject.Named
@FunctionClient
static interface MathClient {
Long max() (1)
@Named("round")
int rnd(float value)
}
For further information on the use of @FunctionClient, please see Calling Functions.
|
Now you can start up the Micronaut application and access your function via the client interface in your test.
void "test invoking a local function"() {
given:
EmbeddedServer server = ApplicationContext.run(EmbeddedServer)
MathClient mathClient = server.getApplicationContext().getBean(MathClient)
expect:
mathClient.max() == Integer.MAX_VALUE.toLong()
mathClient.rnd(1.6) == 2
mathClient.sum(new Sum(a:5,b:10)) == 15
}9.2.2 Functions as CLI Applications
To execute your function as a CLI application with java -jar, you will need to package your application as an executable JAR file. For example, in build.gradle:
build.gradle
buildscript {
repositories {
maven { url "https://plugins.gradle.org/m2/" } (1)
}
dependencies {
classpath "com.github.jengelman.gradle.plugins:shadow:2.0.4"
...
}
}
apply plugin:"com.github.johnrengelman.shadow"
shadowJar {
mergeServiceFiles()
}| 1 | The Gradle Shadow plugin is hosted in the http://plugins.gradle.org repository |
You can now package your application using the shadowJar task.
Packaging a Function as a JAR
$ ./gradlew shadowJarAt this point, you can execute your function using the java -jar command. To supply input data to the function, simply pipe input via System.in. For example:
Executing a function via the CLI
$ echo '{value: 3}' | java -jar build/libs/math-function-0.1-all.jarThe above example will provide the JSON {value: 3} to function which will write the return value to standard out.
This allows functions written with Micronaut to be deployed to Function-as-a-Service (FaaS) platforms that process functions via standard in/out such as OpenFaaS.
9.3 Deploying Functions
Micronaut functions can be deployed to either AWS lambda or any FaaS platform that can execute the function as a container. The following sections detail how to deploy your function.
9.3.1 Deploying Functions to AWS Lambda
| Read Micronaut Functions deployed in AWS Lambda guide for a step by step tutorial. |
For Java & Kotlin functions, support for AWS Lambda can be enabled by adding the function-aws dependency to your classpath. For example, in build.gradle:
build.gradle
dependencies {
...
compile "io.micronaut:micronaut-function-aws"
...
}For Groovy functions, the function-groovy dependency is sufficient for AWS Lambda support.
build.gradle
dependencies {
...
compile "io.micronaut:micronaut-function-groovy"
...
}Configuration
Configuration properties specific to AWS Lambda environments can be supplied in an application-aws configuration file in src/main/resources.
application-aws.yml
production:
property: 44Manual Deployment
You can deploy your function to AWS Lambda manually by building and uploading an executable JAR file. Various build plugins offer this capability.
Gradle Shadow plugin
The Gradle Shadow plugin provides a shadowJar task to generate a self-contained executable JAR file, which is suitable for AWS Lambda deployments.
Example build.gradle
buildscript {
repositories {
maven { url "https://plugins.gradle.org/m2/" } (1)
}
dependencies {
classpath "com.github.jengelman.gradle.plugins:shadow:2.0.4"
...
}
}
apply plugin:"com.github.johnrengelman.shadow"
shadowJar {
mergeServiceFiles()
}| 1 | The Gradle Shadow plugin is hosted in the http://plugins.gradle.org repository |
The executable JAR file can now be built using the shadowJar task.
$ ./gradlew shadowJarMaven Shade plugin
The Maven Shade plugin will generate an executable JAR file for Maven projects. For further details, consult the AWS Lambda Documentation.
Example pom.xml
<project>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>${exec.mainClass}</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>The executable JAR file can now be built using the package phase.
$ ./mvnw packageGradle AWS Plugin
For Gradle projects, deployment can be made even more straightforward using the Gradle AWS Plugin. This plugin provides a deploy task which can push your function to AWS Lambda directly, as well as a AWSLambdaInvokeTask which can be used to invoke your function when it is deployed.
Example build.gradle
import com.amazonaws.services.lambda.model.InvocationType
import jp.classmethod.aws.gradle.lambda.AWSLambdaInvokeTask
import jp.classmethod.aws.gradle.lambda.AWSLambdaMigrateFunctionTask
import com.amazonaws.services.lambda.model.Runtime
buildscript {
repositories {
...
maven { url "https://plugins.gradle.org/m2/" } (1)
}
dependencies {
classpath "jp.classmethod.aws:gradle-aws-plugin:0.22"
}
}
apply plugin: 'jp.classmethod.aws.lambda' (2)
...
task deploy(type: AWSLambdaMigrateFunctionTask, dependsOn: shadowJar) {
functionName = "hello-world"
handler = "example.HelloWorldFunction::hello"
role = "arn:aws:iam::${aws.accountId}:role/lambda_basic_execution" (3)
runtime = Runtime.Java8
zipFile = shadowJar.archivePath
memorySize = 256
timeout = 60
}
task invoke(type: AWSLambdaInvokeTask) {
functionName = "hello-world"
invocationType = InvocationType.RequestResponse
payload = '{"name":"Fred"}'
doLast {
println "Lambda function result: " + new String(invokeResult.payload.array(), "UTF-8")
}
}| 1 | The AWS Gradle plugin is hosted from the https://plugins.gradle.org repository |
| 2 | Apply the Gradle AWS plugin |
| 3 | The Gradle AWS plugin will resolve your AWS credentials from .aws/credentials file, which is the default location used by the AWS CLI to set up your environment |
Note that the value of the handler property of the deploy task should be either:
-
In this case of Java or Kotlin:
io.micronaut.function.aws.MicronautRequestStreamHandler -
In the case of Groovy function definitions: A reference to the function (in the above case
example.HelloWorldFunction::hello)
The reason for this is the function-groovy dependency applies additional code transformations to make it possible to reference the function directly.
With the above build configuration, the function can be deployed to AWS Lambda using the deploy task.
$ ./gradlew deployThe deployed function can then be invoked.
$ ./gradlew invoke
Hello, FredConsult the Gradle AWS plugin documentation for more details on the use of the plugin.
9.3.2 Deploying Functions to OpenFaaS
When creating a function you can use the openfaas feature to create a function that includes a Dockerfile that can be built into an image deployable to OpenFaas:
Creating an OpenFaaS Function
$ mn create-function hello-world-function --features openfaas9.4 Calling Functions with FunctionClient
Micronaut provides support for invoking functions (either locally or deployed to a cloud provider) directly within the application context. To use the features described in this section, you will need to have the function-client dependency on your classpath. For example, in build.gradle
build.gradle
compile "io.micronaut:micronaut-function-client"|
Using the CLI
If you are creating your project using the Micronaut CLI’s |
The developer’s primary use of this feature will be in defining interfaces that are annotated with FunctionClient. When this annotation is applied, methods on the interface will become invokers of respective methods on the remote (or local) function associated with the interface.
In addition, the function-client works together with Micronaut’s Service Discovery functionality, identifying any functions that are registered with the current service discovery provider and making them available to the client application.
FunctionClient
The @FunctionClient annotation makes it very straightforward to invoke local or remotely deployed functions. For example, the following Groovy function can be accessed using the MathClient interface listed below it.
MaxFunction.groovy
import groovy.transform.Field
math.multiplier = 2
@Field MathService mathService
Long max() {
mathService.max()
}Using @FunctionClient to Discover Function
import io.micronaut.function.client.FunctionClient
import javax.inject.Named
@FunctionClient
static interface MathClient {
Long max() (1)
}| 1 | Method names in the interface will be mapped to methods on the target function, in this case Long max() |
If you would like the names of the client interface and target function to be different, you can use the Named annotation to specify the target method name.
RoundFunction.groovy
import groovy.transform.Field
math.multiplier = 2
@Field MathService mathService
int round(float value) {
mathService.round(value)
}Using @Named to customize target method
import io.micronaut.function.client.FunctionClient
import javax.inject.Named
@FunctionClient
static interface MathClient {
@Named("round")
int rnd(float value)
}Functions that only return a value are mapped to HTTP GET requests, whilst functions that accept an input require an HTTP POST.
For a example, the following function can be accessed using the IsbnValidatorClient interface listed below.
import io.micronaut.function.FunctionBean;
import java.util.function.Function;
@FunctionBean("isbn-validator")
public class IsbnValidatorFunction implements Function<IsbnValidationRequest, IsbnValidationResponse> {
@Override
public IsbnValidationResponse apply(IsbnValidationRequest request) {
return new IsbnValidationResponse();
}
}import io.micronaut.function.client.FunctionClient;
import io.micronaut.http.annotation.Body;
import io.reactivex.Single;
import javax.inject.Named;
@FunctionClient
public interface IsbnValidatorClient {
@Named("isbn-validator")
Single<IsbnValidationResponse> validate(@Body IsbnValidationRequest request); (1)
}| 1 | Please, note the @Body annotation in the method parameter. |
Reactive FunctionClients
@FunctionClient interfaces support RxJava constructs, so the above interfaces could be implemented as shown below:
RxMathClient.groovy
import io.micronaut.function.client.FunctionClient
import javax.inject.Named
import io.reactivex.Single
@FunctionClient
static interface RxMathClient {
Single<Long> max()
@Named("round")
Single<Integer> rnd(float value)
Single<Long> sum(Sum sum)
}Remote Functions
Once functions have been deployed to a cloud provider, you can specify endpoints in your client configuration. Micronaut will then create FunctionDefinitions for these remote functions, allowing you to access them through FunctionClient interfaces just as you would with local functions.
AWS Lambda
The configuration key path aws.lambda.functions can be used to specify function endpoints in an AWS Lambda environment.
application.yml
aws:
lambda:
functions:
hello:
functionName: hello-world
qualifer: foo
region: us-east-1In the above case a function named hello is mapped to the remote lambda function called hello-world. You can define multiple named functions under the aws.lambda.functions configuration. Each is configured by AWSInvokeRequestDefinition that allows setting any property on the underlying com.amazonaws.services.lambda.model.InvokeRequest.
To configure credentials for invoking the function you can either define a ~/.aws/credentials file or use application.yml. Micronaut registers a EnvironmentAWSCredentialsProvider that resolves AWS credentials from the Micronaut Environment.
To invoke a function Micronaut configures a AWSLambdaAsyncClient using AWSLambdaConfiguration that allows configuring any of the properties of the AWSLambdaAsyncClientBuilder class.
|
You can now write FunctionClient interfaces against the remote function, as shown below.
HelloClient.groovy
import io.reactivex.*;
@FunctionClient
interface HelloClient {
Single<String> hello(String name);
}10 Message-Driven Microservices
In the past, with monolithic applications, message listeners that listened to messages from messaging systems would frequently be embedded in the same application unit.
In Microservice architectures it is common to have individual Microservice applications that are driven by a message system such as RabbitMQ or Kafka.
In fact a Message-driven Microservice may not even feature an HTTP endpoint or HTTP server (although this can be valuable from a health check and visibility perspective).
10.1 Kafka Support
Apache Kafka is a distributed stream processing platform that can be used for a range of messaging requirements in addition to stream processing and real-time data handling.
Micronaut features dedicated support for defining both Kafka Producer and Consumer instances. Micronaut applications built with Kafka can be deployed with or without the presence of an HTTP server.
With Micronaut’s efficient compile-time AOP and cloud native features, writing efficient Kafka consumer applications that use very little resources is a breeze.
10.1.1 Using the Micronaut CLI
To create a project with Kafka support using the Micronaut CLI, supply the kafka feature to the features flag.
$ mn create-app my-kafka-app --features kafka
This will create a project with the minimum necessary configuration for Kafka.
Kafka Profile
The Micronaut CLI includes a specialized profile for Kafka-based messaging applications. This profile will create a Micronaut app with Kafka support, and without an HTTP server (although you can add one if you desire). The profile also provides a couple commands for generating Kafka listeners and producers.
To create a project using the Kafka profile, use the profile flag:
$ mn create-app my-kafka-service --profile kafka
As you’d expect, you can start the application with ./gradlew run (for Gradle) or ./mvnw compile exec:exec (Maven). The application will (with the default config) attempt to connect to Kafka at http://localhost:9092, and will continue to run without starting up an HTTP server. All communication to/from the service will take place via Kafka producers and/or listeners.
Within the new project, you can now run the Kafka-specific code generation commands:
$ mn create-kafka-producer Message | Rendered template Producer.java to destination src/main/java/my/kafka/app/MessageProducer.java $ mn create-kafka-listener Message | Rendered template Listener.java to destination src/main/java/my/kafka/app/MessageListener.java
10.1.2 Kafka Quick Start
To add support for Kafka to an existing project, you should first add the Micronaut Kafka configuration to your build configuration. For example in Gradle:
build.gradle
compile "io.micronaut.configuration:micronaut-kafka"Or with Maven:
Maven
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-kafka</artifactId>
</dependency>Configuring Kafka
The minimum requirement to configure Kafka is set the value of the kafka.bootstrap.servers property in application.yml:
Configuring Kafka
kafka:
bootstrap:
servers: localhost:9092The value can also be list of available servers:
Configuring Kafka
kafka:
bootstrap:
servers:
- foo:9092
- bar:9092
You can also set the environment variable KAFKA_BOOTSTRAP_SERVERS to a comma separated list of values to externalize configuration.
|
Creating a Kafka Producer with @KafkaClient
To create a Kafka Producer that sends messages you can simply define an interface that is annotated with @KafkaClient.
For example the following is a trivial @KafkaClient interface:
ProductClient.java
import io.micronaut.configuration.kafka.annotation.*;
@KafkaClient (1)
public interface ProductClient {
@Topic("my-products") (2)
void sendProduct(@KafkaKey String brand, String name); (3)
}| 1 | The @KafkaClient annotation is used to designate this interface as a client |
| 2 | The @Topic annotation indicates which topics the ProducerRecord should be published to |
| 3 | The method defines two parameters: The parameter that is the Kafka key and the value. |
You can omit the key, however this will result in a null key which means Kafka will not know how to partition the record.
|
At compile time Micronaut will produce an implementation of the above interface. You can retrieve an instance of ProductClient either by looking up the bean from the ApplicationContext or by injecting the bean with @Inject:
Using ProductClient
ProductClient client = applicationContext.getBean(ProductClient.class);
client.sendProduct("Nike", "Blue Trainers");Note that since the sendProduct method returns void this means the method will send the ProducerRecord and block until the response is received. You can return a Future or Publisher to support non-blocking message delivery.
Creating a Kafka Consumer with @KafkaListener
To listen to Kafka messages you can use the @KafkaListener annotation to define a message listener.
The following example will listen for messages published by the ProductClient in the previous section:
ProductListener.java
import io.micronaut.configuration.kafka.annotation.*;
@KafkaListener(offsetReset = OffsetReset.EARLIEST) (1)
public class ProductListener {
@Topic("my-products") (2)
public void receive(@KafkaKey String brand, String name) { (3)
System.out.println("Got Product - " + name + " by " + brand);
}
}| 1 | The @KafkaListener is used with offsetReset set to EARLIEST which makes the listener start listening to messages from the beginning of the partition. |
| 2 | The @Topic annotation is again used to indicate which topic(s) to subscribe to. |
| 3 | The receive method defines 2 arguments: The argument that will receive the key and the argument that will receive the value. |
10.1.3 Kafka Producers Using @KafkaClient
The example in the quick start presented a trivial definition of an interface that be implemented automatically for you using the @KafkaClient annotation.
The implementation that powers @KafkaClient (defined by the KafkaClientIntroductionAdvice class) is, however, very flexible and offers a range of options for defining Kafka clients.
10.1.3.1 Defining @KafkaClient Methods
Specifying the Key and the Value
The Kafka key can be specified by providing a parameter annotated with @KafkaKey. If no such parameter is specified the record is sent with a null key.
The value to send is resolved by selecting the argument annotated with @Body, otherwise the first argument with no specific binding annotation is used. For example:
@Topic("my-products")
void sendProduct(@KafkaKey String brand, String name);The method above will use the parameter brand as the key and the parameter name as the value.
Including Message Headers
There are a number of ways you can include message headers. One way is to annotate an argument with the @Header annotation and include a value when calling the method:
@Topic("my-products")
void sendProduct(
@KafkaKey String brand,
String name,
@Header("My-Header") String myHeader);The example above will include the value of the myHeader argument as a header called My-Header.
Another way to include headers is at the type level with the values driven from configuration:
Declaring @KafkaClient Headers
import io.micronaut.configuration.kafka.annotation.KafkaClient;
import io.micronaut.messaging.annotation.Header;
@KafkaClient(id="product-client")
@Header(name = "X-Token", value = "${my.application.token}")
public interface ProductClient {
...
}The above example will send a header called X-Token with the value read from the setting my.application.token in application.yml (or the environnment variable MY_APPLICATION_TOKEN).
If the my.application.token is not set then an error will occur creating the client.
Reactive and Non-Blocking Method Definitions
The @KafkaClient annotation supports the definition of reactive return types (such as Flowable or Reactor Flux) as well as Futures.
The following sections cover possible method signatures and behaviour:
Single Value and Return Type
Single<Book> sendBook(
@KafkaKey String author,
Single<Book> book
);Flowable Value and Return Type
Flowable<Book> sendBooks(
@KafkaKey String author,
Flowable<Book> book
);Flowable Value and Return Type
Flux<RecordMetadata> sendBooks(
@KafkaKey String author,
Flux<Book> book
);The implementation will return a Reactor Flux that when subscribed to will subscribe to the passed Flux and for each emitted item will send a ProducerRecord emitting the resulting Kafka RecordMetadata if successful or an error otherwise.
Available Annotations
There are a number of annotations available that allow you to specify how a method argument is treated.
The following table summarizes the annotations and their purpose, with an example:
| Annotation | Description | Example |
|---|---|---|
Allows explicitly indicating the body of the message to sent |
|
|
Allows specifying a parameter that should be sent as a header |
|
|
Allows specifying the parameter that is the Kafka key |
|
For example, you can use the @Header annotation to bind a parameter value to a header in the ProducerRecord.
10.1.3.2 Configuring @KafkaClient beans
@KafkaClient and Producer Properties
There are a number of ways to pass configuration properties to the KafkaProducer. You can set default producer properties using kafka.producers.default in application.yml:
Applying Default Configuration
kafka:
producers:
default:
retries: 5Any property in the ProducerConfig class can be set. The above example will set the default number of times to retry sending a record.
Per @KafkaClient Producer Properties
To configure different properties for each client, you should set a @KafkaClient id using the annotation:
Using a Client ID
@KafkaClient("product-client")This serves 2 purposes. Firstly it sets the value of the client.id setting used to build the KafkaProducer. Secondly, it allows you to apply per producer configuration in application.yml:
Applying Default Configuration
kafka:
producers:
product-client:
retries: 5Finally, the @KafkaClient annotation itself provides a properties member that you can use to set producer specific properties:
Configuring Producer Properties with @KafkaClient
import io.micronaut.configuration.kafka.annotation.KafkaClient;
import io.micronaut.context.annotation.Property;
import org.apache.kafka.clients.producer.ProducerConfig;
@KafkaClient(
id="product-client",
acks = KafkaClient.Acknowledge.ALL,
properties = @Property(name = ProducerConfig.RETRIES_CONFIG, value = "5")
)
public interface ProductClient {
...
}@KafkaClient and Serializers
When serializing keys and values Micronaut will by default attempt to automatically pick a Serializer to use. This is done via the CompositeSerdeRegistry bean.
You can replace the default SerdeRegistry bean with your own implementation by defining a bean that uses @Replaces(CompositeSerdeRegistry.class). See the section on Bean Replacement.
|
All common java.lang types (String, Integer, primitives etc.) are supported and for POJOs by default a Jackson based JSON serializer is used.
You can, however, explicitly override the Serializer used by providing the appropriate configuration in application.yml:
Applying Default Configuration
kafka:
producers:
product-client:
value:
serializer: org.apache.kafka.common.serialization.ByteArrayDeserializerYou may want to do this if for example you choose an alternative serialization format such as Avro or Protobuf.
10.1.3.3 Sending Records in Batch
By default if you define a method that takes a container type such as a List the list will be serialized using the specified value.serializer (the default will result in a JSON array).
For example the following two methods will both send serialized arrays:
Sending Arrays and Lists
@Topic("books")
void sendList(List<Book> books);
@Topic("books")
void sendBooks(Book...books);Instead of a sending a serialized array you may wish to instead send batches of ProducerRecord either synchronously or asynchronously.
To do this you can specify a value of true to the batch member of the @KafkaClient annotation:
Sending
ProducerRecord batches@KafkaClient(batch=true)
@Topic("books")
void send(List<Book> books);In the above case instead of sending a serialized array the client implementation will iterate over each item in the list and send a ProducerRecord for each. The previous example is blocking, however you can return a reactive type if desired:
Sending
ProducerRecord batches Reactively@KafkaClient(batch=true)
@Topic("books")
Flowable<RecordMetadata> send(List<Book> books);You can also use an unbound reactive type such as Flowable as the source of your batch data:
Sending
ProducerRecord batches from a Flowable@KafkaClient(batch=true)
@Topic("books")
Flowable<RecordMetadata> send(Flowable<Book> books);10.1.3.4 Injecting Kafka Producer Beans
If you need maximum flexibility and don’t want to use the @KafkaClient support you can use the @KafkaClient annotation as qualifier for dependency injection of KafkaProducer instances.
Consider the following example:
Using a KafkaProducer directly
import io.micronaut.configuration.kafka.annotation.KafkaClient;
import org.apache.kafka.clients.producer.*;
import javax.inject.Singleton;
import java.util.concurrent.Future;
@Singleton
public class BookSender {
private final KafkaProducer<String, Book> kafkaProducer;
public BookSender(
@KafkaClient("book-producer") KafkaProducer<String, Book> kafkaProducer) { (1)
this.kafkaProducer = kafkaProducer;
}
public Future<RecordMetadata> send(String author, Book book) {
return kafkaProducer.send(new ProducerRecord<>("books", author, book)); (2)
}
}| 1 | The KafkaProducer is dependency injected into the constructor. If not specified in configuration, the key and value serializer are inferred from the generic type arguments. |
| 2 | The KafkaProducer is used to send records |
Note that there is no need to call the close() method to shut down the KafkaProducer, it is fully managed by Micronaut and will be shutdown when the application shuts down.
The previous example can be tested in JUnit with the following test:
Using a KafkaProducer directly
@Test
public void testBookSender() throws IOException {
Map<String, Object> config = Collections.singletonMap( (1)
AbstractKafkaConfiguration.EMBEDDED, true
);
try (ApplicationContext ctx = ApplicationContext.run(config)) {
BookSender bookSender = ctx.getBean(BookSender.class); (2)
Book book = new Book();
book.setTitle("The Stand");
bookSender.send("Stephen King", book);
}
}| 1 | An embedded version of Kafka is used |
| 2 | The BookSender is retrieved from the ApplicationContext and a ProducerRecord sent |
By using the KafkaProducer API directly you open up even more options if you require transactions (exactly-once delivery) or want control over when records are flushed etc.
10.1.3.5 Embedding Kafka
The previous section introduced the ability to embed Kafka for your tests. This is possible in Micronaut by specifying the kafka.embedded.enabled setting to true and adding the following dependencies to your test classpath:
Kafka Test Dependencies
testCompile 'org.apache.kafka:kafka-clients:2.0.0:test'
testCompile 'org.apache.kafka:kafka_2.12:2.0.0'
testCompile 'org.apache.kafka:kafka_2.12:2.0.0:test'Note that because of the distributed nature of Kafka it is relatively slow to startup so it is generally better to do the initialization with @BeforeClass (or setupSpec in Spock) and have a large number of test methods rather than many test classes otherwise your test execution performance will suffer.
10.1.4 Kafka Consumers Using @KafkaListener
The quick start section presented a trivial example of what is possible with the @KafkaListener annotation.
Using the @KafkaListener annotation Micronaut will build a KafkaConsumer and start the poll loop by running the KafkaConsumer in a special consumer thread pool. You can configure the size of the thread pool based on the number of consumers in your application in application.yml as desired:
Configuring the
consumer thread poolmicronaut:
executors:
consumer:
type: fixed
nThreads: 25KafkaConsumer instances are single threaded, hence for each @KafkaListener method you define a new thread is created to execute the poll loop.
You may wish to scale the number of consumers you have listening on a particular topic. There are several ways you may achieve this. You could for example run multiple instances of your application each containing a single consumer in each JVM.
Alternatively, you can also scale via threads. By setting the number of threads a particular consumer bean will create:
Scaling with Threads
@KafkaListener(groupId="myGroup", threads=10)The above example will create 10 KafkaConsumer instances, each running in a unique thread and participating in the myGroup consumer group.
@KafkaListener beans are by default singleton. When using multiple threads you must either synchronize access to local state or declare the bean as @Prototype.
|
By default Micronaut will inspect the method signature of the method annotated with @Topic that will listen for ConsumerRecord instances and from the types infer an appropriate key and value Deserializer.
10.1.4.1 Defining @KafkaListener Methods
The @KafkaListener annotation examples up until now have been relatively trivial, but Micronaut offers a lot of flexibility when it comes to the types of method signatures you can define.
The following sections detail examples of supported use cases.
Specifying Topics
The @Topic annotation can be used at the method or the class level to specify which topics to be listened for.
Care needs to be taken when using @Topic at the class level because every public method of the class annotated with @KafkaListener will become a Kafka consumer, which may be undesirable.
You can specify multiple topics to listen for:
Specifying Multiple Topics
@Topic("fun-products", "awesome-products")You can also specify one or many regular expressions to listen for:
Using regular expressions to match Topics
@Topic(patterns="products-\\w+")Available Annotations
There are a number of annotations available that allow you to specify how a method argument is bound.
The following table summarizes the annotations and their purpose, with an example:
| Annotation | Description | Example |
|---|---|---|
Allows explicitly indicating the body of the message |
|
|
Allows binding a parameter to a message header |
|
|
Allows specifying the parameter that is the key |
|
For example, you can use the @Header annotation to bind a parameter value from a header contained within a ConsumerRecord.
Topics, Partitions and Offsets
If you want a reference to the topic, partition or offset it is a simple matter of defining a parameter for each.
The following table summarizes example parameters and how they related to the ConsumerRecord being processed:
| Parameter | Description |
|---|---|
|
The name of the topic |
|
The offset of the |
|
The partition of the |
|
The timestamp of the |
As an example, following listener method will receive all of the above mentioned parameters:
Specifying Parameters for offset, topic etc.
@Topic("awesome-products")
public void receive(
@KafkaKey String brand, (1)
Product product, (2)
long offset, (3)
int partition, (4)
String topic, (5)
long timestamp) { (6)
System.out.println("Got Product - " + product.getName() + " by " + brand);
}| 1 | The Kafka key |
| 2 | The message body |
| 3 | The offset of the ConsumerRecord |
| 4 | The partition of the ConsumerRecord |
| 5 | The topic. Note that the @Topic annotation supports multiple topics. |
| 6 | The timestamp of the ConsumerRecord |
Receiving a ConsumerRecord
If you prefer you can also receive the entire ConsumerRecord object being listened for. In this case you should specify appropriate generic types for the key and value of the ConsumerRecord so that Micronaut can pick the correct deserializer for each.
Consider the following example:
Specifying Parameters for offset, topic etc.
@Topic("awesome-products")
public void receive(ConsumerRecord<String, Product> record) { (1)
Product product = record.value(); (2)
String brand = record.key(); (3)
System.out.println("Got Product - " + product.getName() + " by " + brand);
}| 1 | The method signature accepts a ConsumerRecord that specifies a String for the key type and a POJO (Product) for the value type. |
| 2 | The value() method is used to retrieve the value |
| 3 | The key() method is used to retrieve the key |
Receiving and returning Reactive Types
In addition to common Java types and POJOs you can also define listener methods that receive a Reactive type such as a Single or a Reactor Mono. For example:
Using Reactive Types
@Topic("reactive-products")
public Single<Product> receive(
@KafkaKey String brand, (1)
Single<Product> productFlowable) { (2)
return productFlowable.doOnSuccess((product) ->
System.out.println("Got Product - " + product.getName() + " by " + brand) (3)
);
}| 1 | The @KafkaKey annotation is used to indicate the key |
| 2 | A Single is used to receive the message body |
| 3 | The doOnSuccess method is used to process the result |
Note that in this case the method returns an Single this indicates to Micronaut that the poll loop should continue and if enable.auto.commit is set to true (the default) the offsets will be committed potentially before the doOnSuccess is called.
The idea here is that you are able to write consumers that don’t block, however care must be taken in the case where an error occurs in the doOnSuccess method otherwise the message could be lost. You could for example re-deliver the message in case of an error.
Alternatively, you can use the @Blocking annotation to tell Micronaut to subscribe to the returned reactive type in a blocking manner which will result in blocking the poll loop, preventing offsets from being committed automatically:
Blocking with Reactive Consumers
@Blocking
@Topic("reactive-products")
public Single<Product> receive(
...
}10.1.4.2 Configuring @KafkaListener beans
@KafkaListener and Consumer Groups
Kafka consumers created with @KafkaListener will by default run within a consumer group that is the value of micronaut.application.name unless you explicitly specify a value to the @KafkaListener annotation. For example:
Specifying a Consumer Group
@KafkaListener("myGroup")The above example will run the consumer within a consumer group called myGroup.
You can make the consumer group configurable using a placeholder: @KafkaListener("${my.consumer.group:myGroup}")
|
@KafkaListener and Consumer Properties
There are a number of ways to pass configuration properties to the KafkaConsumer. You can set default consumer properties using kafka.consumers.default in application.yml:
Applying Default Configuration
kafka:
consumers:
default:
session:
timeout:
ms: 5000The above example will set the default session.timeout.ms that Kafka uses to decide whether a consumer is alive or not and applies it to all created KafkaConsumer instances.
You can also provide configuration specific to a consumer group. For example consider the following configuration:
Applying Consumer Group Specific config
kafka:
consumers:
myGroup:
session:
timeout:
ms: 5000The above configuration will pass properties to only the @KafkaListener beans that apply to the consumer group myGroup.
Finally, the @KafkaListener annotation itself provides a properties member that you can use to set consumer specific properties:
Configuring Consumer Properties with @KafkaListener
import io.micronaut.configuration.kafka.annotation.*;
import io.micronaut.context.annotation.Property;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
@KafkaListener(
groupId = "products",
pollTimeout = "500ms",
properties = @Property(name = ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, value = "5000")
)
public class ProductListener {
...
}@KafkaListener and Deserializers
As mentioned previously when defining @KafkaListener methods, Micronaut will attempt to pick an appropriate deserializer for the method signature. This is done via the CompositeSerdeRegistry bean.
You can replace the default SerdeRegistry bean with your own implementation by defining a bean that uses @Replaces(CompositeSerdeRegistry.class). See the section on Bean Replacement.
|
All common java.lang types (String, Integer, primitives etc.) are supported and for POJOs by default a Jackson based JSON deserializer is used.
You can, however, explicitly override the Deserializer used by providing the appropriate configuration in application.yml:
Applying Default Configuration
kafka:
consumers:
myGroup:
value:
deserializer: org.apache.kafka.common.serialization.ByteArrayDeserializerYou may want to do this if for example you choose an alternative deserialization format such as Avro or Protobuf.
10.1.4.3 Commiting Kafka Offsets
Automatically Committing Offsets
The way offsets are handled by a @KafkaListener bean is defined by the OffsetStrategy enum.
The following table summarizes the enum values and behaviour:
| Value | Description |
|---|---|
Automatically commit offsets. Sets |
|
Disables automatically committing offsets. Sets |
|
Commits offsets manually at the end of each |
|
Asynchronously commits offsets manually at the end of each |
|
Commits offsets manually after each |
|
Commits offsets asynchronously after each |
Depending on the your level of paranoia or durability requirements you can choose to tune how and when offsets are committed.
Manually Committing Offsets
If you set the OffsetStrategy to DISABLED it becomes your responsibility to commit offsets.
There are a couple of ways that can be achieved.
The simplest way is to define an argument of type Acknowledgement and call the ack() method to commit offsets synchronously:
Committing offsets with
ack()@KafkaListener(
offsetReset = OffsetReset.EARLIEST,
offsetStrategy = OffsetStrategy.DISABLED (1)
)
@Topic("awesome-products")
void receive(
Product product,
Acknowledgement acknowledgement) { (2)
// process product record
acknowledgement.ack(); (3)
}| 1 | Committing offsets automatically is disabled |
| 2 | The listener method specifies a parameter of type Acknowledgement |
| 3 | The ack() method is called once the record has been processed |
Alternatively, you an supply a KafkaConsumer method argument and then call commitSync (or commitAsync) yourself when you are ready to commit offsets:
Committing offsets with the
KafkaConsumer APIimport io.micronaut.configuration.kafka.annotation.*;
import io.micronaut.configuration.kafka.docs.consumer.config.Product;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import java.util.Collections;
@KafkaListener(
offsetReset = OffsetReset.EARLIEST,
offsetStrategy = OffsetStrategy.DISABLED (1)
)
@Topic("awesome-products")
void receive(
Product product,
long offset,
int partition,
String topic,
KafkaConsumer kafkaConsumer) { (2)
// process product record
// commit offsets
kafkaConsumer.commitSync(Collections.singletonMap( (3)
new TopicPartition(topic, partition),
new OffsetAndMetadata(offset + 1, "my metadata")
));
}| 1 | Committing offsets automatically is disabled |
| 2 | The listener method specifies that it receives the offset data and a KafkaConsumer |
| 3 | The commitSync() method is called once the record has been processed |
Manually Assigning Offsets to a Consumer Bean
Sometimes you may wish to control exactly the position you wish to resume consuming messages from.
For example if you store offsets in a database you may wish to read the offsets from the database when the consumer starts and start reading from the position stored in the database.
To support this use case your consumer bean can implement the ConsumerRebalanceListener and KafkaConsumerAware interfaces:
Manually seeking offsets with the
KafkaConsumer APIimport io.micronaut.configuration.kafka.KafkaConsumerAware;
import io.micronaut.configuration.kafka.annotation.*;
import org.apache.kafka.clients.consumer.ConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import javax.annotation.Nonnull;
import java.util.Collection;
@KafkaListener
public class ProductListener implements ConsumerRebalanceListener, KafkaConsumerAware {
private KafkaConsumer consumer;
@Override
public void setKafkaConsumer(@Nonnull KafkaConsumer consumer) { (1)
this.consumer = consumer;
}
@Topic("awesome-products")
void receive(Product product) {
// process product
}
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) { (2)
// save offsets here
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) { (3)
// seek to offset here
for (TopicPartition partition : partitions) {
consumer.seek(partition, 1);
}
}
}| 1 | The setKafkaConsumer of the KafkaConsumerAware allows access to the underlying producer |
| 2 | The onPartitionsRevoked can be used to save offsets |
| 3 | The onPartitionsAssigned can use used to read offsets and seek to a specific position. In this trivial example we just seek to the offset 1 (skipping the first record). |
10.1.4.4 Kafka Batch Processing
By default @KafkaListener listener methods will receive each ConsumerRecord one by one.
There may be cases where you prefer to receive all of the ConsumerRecord data from the ConsumerRecords holder object in one go.
To achieve this you can set the batch member of the @KafkaListener to true and specify a container type (typically List) to receive all of the data:
Receiving a Batch of Records
import io.micronaut.configuration.kafka.annotation.*;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import reactor.core.publisher.Flux;
import java.util.Collections;
import java.util.List;
@KafkaListener(batch = true) (1)
public class BookListener {
@Topic("all-the-books")
public void receiveList(List<Book> books) { (2)
for (Book book : books) {
System.out.println("Got Book = " + book.getTitle()); (3)
}
}
}| 1 | The @KafkaListener annotation’s batch member is set to true |
| 2 | The method defines that it receives a list of Book instances |
| 3 | The method processes the entire batch |
Note in the previous case offsets will automatically be committed for the whole batch by default when the method returns without error.
Manually Committing Offsets with Batch
You can also take more control of committing offsets when doing batch processing by specifying a method that receives the offsets in addition to the batch:
Committing Offsets Manually with Batch
@Topic("all-the-books")
public void receive(
List<Book> books,
List<Long> offsets,
List<Integer> partitions,
List<String> topics,
KafkaConsumer kafkaConsumer) { (1)
for (int i = 0; i < books.size(); i++) {
// process the book
Book book = books.get(i); (2)
// commit offsets
String topic = topics.get(i);
int partition = partitions.get(i);
long offset = offsets.get(i); (3)
kafkaConsumer.commitSync(Collections.singletonMap( (4)
new TopicPartition(topic, partition),
new OffsetAndMetadata(offset + 1, "my metadata")
));
}
}| 1 | The method receives the batch of records as well as the offsets, partitions and topics |
| 2 | Each record is processed |
| 3 | The offset, partition and topic is read for the record |
| 4 | Offsets are committed |
This example is fairly trivial in that it commits offsets after processing each record in a batch, but you can for example commit after processing every 10, or every 100 or whatever makes sense for your application.
Reactive Batch Processing
Batch listeners also support defining reactive types (either Flowable or Reactor Flux) as the method argument.
In this case the method will be passed a reactive type that can be returned from the method allowing non-blocking processing of the batch:
Reactive Processing of Batch Records
@Topic("all-the-books")
public Flux<Book> receiveFlux(Flux<Book> books) {
return books.doOnNext(book ->
System.out.println("Got Book = " + book.getTitle())
);
}Remember that as with non batch processing, the reactive type will be subscribed to on a different thread and offsets will be committed automatically likely prior to the point when the reactive type is subscribed to.
This means that you should only use reactive processing if message durability is not a requirement and you may wish to implement message re-delivery upon failure.
10.1.4.5 Forwarding Messages with @SendTo
On any @KafkaListener method that returns a value, you can use the @SendTo annotation to forward the return value to the topic or topics specified by the @SendTo annotation.
The key of the original ConsumerRecord will be used as the key when forwarding the message.
Committing offsets with the
KafkaConsumer APIimport io.micronaut.configuration.kafka.annotation.*;
import io.micronaut.configuration.kafka.docs.consumer.config.Product;
import io.micronaut.messaging.annotation.SendTo;
import io.reactivex.Single;
import io.reactivex.functions.Function;
@Topic("awesome-products") (1)
@SendTo("product-quantities") (2)
public int receive(
@KafkaKey String brand,
Product product) {
System.out.println("Got Product - " + product.getName() + " by " + brand);
return product.getQuantity(); (3)
}| 1 | The topic subscribed to is awesome-products |
| 2 | The topic to send the result to is product-quantities |
| 3 | The return value is used to indicate the value to forward |
You can also do the same using Reactive programming:
Committing offsets with the
KafkaConsumer API@Topic("awesome-products") (1)
@SendTo("product-quantities") (2)
public Single<Integer> receiveProduct(
@KafkaKey String brand,
Single<Product> productSingle) {
return productSingle.map(product -> {
System.out.println("Got Product - " + product.getName() + " by " + brand);
return product.getQuantity(); (3)
});
}| 1 | The topic subscribed to is awesome-products |
| 2 | The topic to send the result to is product-quantities |
| 3 | The return is mapped from the single to the value of the quantity |
In the reactive case the poll loop will continue and will not wait for the record to be sent unless you specifically annotate the method with @Blocking.
10.1.4.6 Handling Consumer Exceptions
When an exception occurs in a @KafkaListener method by default the exception is simply logged. This is handled by DefaultKafkaListenerExceptionHandler.
If you wish to replace this default exception handling with another implementation you can use the Micronaut’s Bean Replacement feature to define a bean that replaces it: @Replaces(DefaultKafkaListenerExceptionHandler.class).
You can also define per bean exception handling logic by implementation the KafkaListenerExceptionHandler interface in your @KafkaListener class.
The KafkaListenerExceptionHandler receives an exception of type KafkaListenerException which allows access to the original ConsumerRecord, if available.
10.1.5 Running Kafka Applications
You can run a Micronaut Kafka application with or without the presence of an HTTP server.
If you run your application without the http-server-netty dependency you will see output like the following on startup:
11:06:22.638 [main] INFO io.micronaut.runtime.Micronaut - Startup completed in 402ms. Server Running: 4 active message listeners.No port is exposed, but the Kafka consumers are active and running. The process registers a shutdown hook such that the KafkaConsumer instances are closed correctly when the server is shutdown.
10.1.5.1 Kafka Health Checks
In addition to http-server-netty, if the management dependency is added, then Micronaut’s Health Endpoint can be used to expose the health status of the Kafka consumer application.
For example if Kafka is not available the /health endpoint will return:
{
"status": "DOWN",
"details": {
...
"kafka": {
"status": "DOWN",
"details": {
"error": "java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Timed out waiting for a node assignment."
}
}
}
}| By default, the details visible above are only shown to authenticated users. See the Health Endpoint documentation for how to configure that setting. |
10.1.6 Building Kafka Stream Applications
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features kafka-streams |
Kafka Streams is a platform for building real time streaming applications.
When using Micronaut with Kafka Stream, your application gains all of the features from Micronaut (configuration management, AOP, DI, health checks etc.), simplifying the construction of Kafka Stream applications.
Since Micronaut’s DI and AOP is compile time, you can build low overhead stream applications with ease.
Defining Kafka Streams
To define Kafka Streams you should first add the kafka-streams configuration to your build.
For example in Gradle:
build.gradle
compile "io.micronaut.configuration:micronaut-kafka-streams"Or with Maven:
Maven
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-kafka-streams</artifactId>
</dependency>The minimum configuration required is to set the Kafka bootstrap servers:
Configuring Kafka
kafka:
bootstrap:
servers: localhost:9092You should then define a @Factory for your streams that defines beans that return a KStream. For example to implement the Word Count example from the Kafka Streams documentation:
Kafka Streams Word Count
import io.micronaut.context.annotation.Factory;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.*;
import javax.inject.Named;
import javax.inject.Singleton;
import java.util.*;
@Factory
public class WordCountStream {
public static final String INPUT = "streams-plaintext-input"; (1)
public static final String OUTPUT = "streams-wordcount-output"; (2)
@Singleton
KStream<String, String> wordCountStream(ConfiguredStreamBuilder builder) { (3)
// set default serdes
Properties props = builder.getConfiguration();
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
KStream<String, String> source = builder.stream(INPUT);
KTable<String, Long> counts = source
.flatMapValues( value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split(" ")))
.groupBy((key, value) -> value)
.count();
// need to override value serde to Long type
counts.toStream().to(OUTPUT, Produced.with(Serdes.String(), Serdes.Long()));
return source;
}
}| 1 | The input topic |
| 2 | The output topic |
| 3 | An instance of ConfiguredStreamBuilder is injected that allows mutating the configuration |
With Kafka streams the key and value Serdes (serializer/deserializer) must be classes with a zero argument constructor. If you wish to use JSON (de)serialization you can subclass JsonSerde to define your Serdes
|
You can use the @KafkaClient annotation to send a sentence to be processed by the above stream:
Defining a Kafka Client
package io.micronaut.configuration.kafka.streams;
import io.micronaut.configuration.kafka.annotation.KafkaClient;
import io.micronaut.configuration.kafka.annotation.Topic;
@KafkaClient
public interface WordCountClient {
@Topic(WordCountStream.INPUT)
void publishSentence(String sentence);
}You can also define a @KafkaListener to listen for the result of the word count stream:
Defining a Kafka Listener
package io.micronaut.configuration.kafka.streams;
import io.micronaut.configuration.kafka.annotation.*;
import java.util.Collections;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
@KafkaListener(offsetReset = OffsetReset.EARLIEST)
public class WordCountListener {
private final Map<String, Long> wordCounts = new ConcurrentHashMap<>();
@Topic(WordCountStream.OUTPUT)
void count(@KafkaKey String word, long count) {
wordCounts.put(word, count);
}
public long getCount(String word) {
Long num = wordCounts.get(word);
if (num != null) {
return num;
}
return 0;
}
public Map<String, Long> getWordCounts() {
return Collections.unmodifiableMap(wordCounts);
}
}Configuring Kafka Streams
You can define multiple Kafka streams each with their own unique configuration. To do this you should define the configuration with kafka.streams.[STREAM-NAME]. For example in application.yml:
Defining Per Stream Configuration
kafka:
streams:
my-stream:
num:
stream:
threads: 10The above configuration sets the num.stream.threads setting of the Kafka StreamsConfig to 10 for a stream named my-stream.
You can then inject a ConfiguredStreamBuilder specfically for the above configuration using javax.inject.Named:
Kafka Streams Word Count
@Singleton
KStream<String, String> myStream(
@Named("my-stream") ConfiguredStreamBuilder builder) {
}11 Standalone Command Line Applications
In certain cases you may which to create standalone command-line (CLI) applications that interact with your Microservice infrastructure.
Examples of applications like this include scheduled tasks, batch applications and general command line applications.
In this case having a robust way to parse command line options and positional parameters is important.
11.1 Picocli Support
Picocli is a command line parser that supports usage help with ANSI colors, autocomplete and nested subcommands. It has an annotations API to create command line applications with almost no code, and a programmatic API for dynamic uses like creating Domain Specific Languages.
From the project Readme page:
How it works: annotate your class and picocli initializes it from the command line arguments, converting the input to strongly typed data. Supports git-like subcommands (and nested sub-subcommands), any option prefix style, POSIX-style grouped short options, password options, custom type converters and more. Parser tracing facilitates troubleshooting.
It distinguishes between named options and positional parameters and allows both to be strongly typed. Multi-valued fields can specify an exact number of parameters or a range (e.g.,
0..*,1..2). Supports Map options like-Dkey1=val1 -Dkey2=val2, where both key and value can be strongly typed.It generates polished and easily tailored usage help and version help, using ANSI colors where possible. Picocli-based command line applications can have TAB autocompletion, interactively showing users what options and subcommands are available. Picocli can generate completion scripts for bash and zsh, and offers an API to easily create a JLine
Completerfor your application.
Micronaut features dedicated support for defining picocli Command instances. Micronaut applications built with picocli can be deployed with or without the presence of an HTTP server.
Combining picocli with Micronaut makes it easy to provide a rich, well-documented command line interface for your Microservices.
11.1.1 Generating a Project with the Micronaut CLI
Create-Cli-App Command
To create a project with picocli support using the Micronaut CLI, use the create-cli-app command.
This will add the dependencies for the picocli feature, and set the profile of the generated project to cli, so the create-command command is available to generate additional commands.
The main class of the project is set to the *Command class (based on the project name - e.g., hello-world will generate HelloWorldCommand):
$ mn create-cli-app my-cli-app
The generated command looks like this:
my.cli.app.MyCliAppCommand.java generated by
create-cli-apppackage my.cli.app;
import io.micronaut.configuration.picocli.PicocliRunner;
import io.micronaut.context.ApplicationContext;
import picocli.CommandLine;
import picocli.CommandLine.Command;
import picocli.CommandLine.Option;
import picocli.CommandLine.Parameters;
@Command(name = "my-cli-app", description = "...",
mixinStandardHelpOptions = true) (1)
public class MyCliAppCommand implements Runnable { (2)
@Option(names = {"-v", "--verbose"}, description = "...") (3)
boolean verbose;
public static void main(String[] args) throws Exception {
PicocliRunner.run(MyCliAppCommand.class, args); (4)
}
public void run() { (5)
// business logic here
if (verbose) {
System.out.println("Hi!");
}
}
}| 1 | The picocli @Command annotation designates this class as a command. The mixinStandardHelpOptions attribute adds --help and --version options to it. |
| 2 | By implementing Runnable or Callable your application can be executed in a single line (<4>) and picocli takes care of handling invalid input and requests for usage help (<cmd> --help) or version information (<cmd> --version). |
| 3 | An example option. Options can have any name and be of any type. The generated code contains this example boolean flag option that lets the user request more verbose output. |
| 4 | PicocliRunner lets picocli-based applications leverage the Micronaut DI container. PicocliRunner.run first creates an instance of this command with all services and resources injected, then parses the command line, while taking care of handling invalid input and requests for usage help or version information, and finally invokes the run method. |
| 5 | Put the business logic of the application in the run or call method. |
Running the Application
Now you can build the project and start the application. The build will create a ${project-name}-all.jar with all dependencies in build/libs.
Running this jar from Java will run the generated MyCliAppCommand.
$ java -jar build/libs/my-cli-app-0.1-all.jar -v
Picocli Feature
Alternatively, to create a project with picocli support using the Micronaut CLI, supply the picocli feature to the features flag.
$ mn create-app my-picocli-app --features picocli
This will create a project with the service profile that has the minimum necessary configuration for picocli.
Note that no command is generated and the main class of the project is set to the default Application class.
Cli Profile
It is also possible to create a project with the create-app command and the --profile=cli flag.
This will create a Micronaut app with picocli support, without an HTTP server (although you can add one if you desire).
The cli profile provides a command for generating picocli commands and subcommands.
$ mn create-app example --profile cli
Note that the main class of the project is set to the default Application class.
If you want a picocli command to be the main class of this application, you need to first generate a command with create-command:
$ cd example $ ../mn mn> create-command example.my-command | Rendered template Command.java to destination src/main/java/example/MyCommand.java | Rendered template CommandTest.java to destination src/test/java/example/MyCommandTest.java
Then open the gradle.build file, and change the mainClassName line to the fully qualified class name of the command:
mainClassName = "example.MyCommand"
The create-cli-app command is more convenient, since it generates a project that includes a command from the beginning and sets the main class to this command.
|
11.1.2 Picocli Quick Start
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features picocli |
To add support for Picocli to an existing project, you should first add the picocli dependency and the Micronaut picocli configuration to your build configuration. For example in Gradle:
build.gradle
compile "info.picocli:picocli"
compile "io.micronaut.configuration:micronaut-picocli"Or with Maven:
Maven
<dependency>
<groupId>info.picocli</groupId>
<artifactId>picocli</artifactId>
</dependency>
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-picocli</artifactId>
</dependency>Configuring picocli
Picocli does not require configuration. See other sections of the manual for configuring the services and resources to inject.
Creating a Picocli Command with @Command
This section will show a quick example that provides a command line interface to a HTTP client that communicates with the GitHub API.
When creating this example project with the Micronaut CLI, use the create-cli-app command, and add the --features=http-client flag:
$ mn create-cli-app example.git-star --features http-client
This will add the io.micronaut:micronaut-http-client dependency to the build. You can also manually add this to your gradle.build:
compile "io.micronaut:micronaut-http-client"
An Example HTTP Client
To create a picocli Command you create a class with fields annotated with @Option or @Parameters to capture the values of the command line options or positional parameters, respectively.
For example the following is a picocli @Command that wraps around the GitHub API:
Example picocli command with injected HTTP client
package example;
import io.micronaut.configuration.picocli.PicocliRunner;
import io.micronaut.context.ApplicationContext;
import io.micronaut.http.annotation.*;
import io.micronaut.http.client.*;
import io.reactivex.*;
import static io.micronaut.http.HttpRequest.*;
import picocli.CommandLine;
import picocli.CommandLine.Command;
import picocli.CommandLine.Option;
import picocli.CommandLine.Parameters;
import java.util.*;
import javax.inject.Inject;
@Command(name = "git-star", header = {
"@|green _ _ _ |@", (1)
"@|green __ _(_) |_ __| |_ __ _ _ _ |@",
"@|green / _` | | _(_-< _/ _` | '_| |@",
"@|green \\__, |_|\\__/__/\\__\\__,_|_| |@",
"@|green |___/ |@"},
description = "Shows GitHub stars for a project",
mixinStandardHelpOptions = true, version = "git-star 0.1") (2)
public class GitStarCommand implements Runnable {
@Client("https://api.github.com")
@Inject RxHttpClient client; (3)
@Option(names = {"-v", "--verbose"}, description = "Shows some project details")
boolean verbose;
@Parameters(description = {"One or more GitHub slugs (comma separated) to show stargazers for.",
" Default: ${DEFAULT-VALUE}"}, split = ",", paramLabel = "<owner/repo>") (4)
List<String> githubSlugs = Arrays.asList("micronaut-projects/micronaut-core", "remkop/picocli");
public static void main(String[] args) throws Exception {
PicocliRunner.run(GitStarCommand.class, args);
}
public void run() { (5)
for (String slug : githubSlugs) {
Map m = client.retrieve(
GET("/repos/" + slug).header("User-Agent", "remkop-picocli"),
Map.class).blockingFirst();
System.out.printf("%s has %s stars%n", slug, m.get("watchers"));
if (verbose) {
String msg = "Description: %s%nLicense: %s%nForks: %s%nOpen issues: %s%n%n";
System.out.printf(msg, m.get("description"),
((Map) m.get("license")).get("name"),
m.get("forks"), m.get("open_issues"));
}
}
}
}| 1 | Headers, footers and descriptions can be multi-line. You can embed ANSI styled text anywhere with the @|STYLE1[,STYLE2]… text|@ markup notation. |
| 2 | Add version information to display when the user requests this with --version. This can also be supplied dynamically, e.g. from the manifest file or a build-generated version properties file. |
| 3 | Inject a HTTP client. In this case, hard-coded to the GitHub API endpoint. |
| 4 | A positional parameter that lets the user select one or more GitHub projects |
| 5 | The business logic: display information for each project the user requested. |
The usage help message generated for this command looks like this:
Subcommands
If your service has a lot of functionality, a common pattern is to have subcommands to control different areas of the service.
To allow Micronaut to inject services and resources correctly into the subcommands,
make sure to obtain subcommand instances from the ApplicationContext, instead of instantiating them directly.
The easiest way to do this is to declare the subcommands on the top-level command, like this:
A top-level command with subcommands
@Command(name = "topcmd", subcommands = {SubCmd1.class, SubCmd2.class}) (1)
class TopCommand implements Callable<Object> { (2)
public static void main(String[] args) throws Exception {
PicocliRunner.call(TopCommand.class, args); (3)
}
//...
}| 1 | The top-level command has two subcommands, SubCmd1 and SubCmd2. |
| 2 | Let all commands in the hierarchy implement Runnable or Callable. |
| 3 | Start the application with PicocliRunner. This creates an ApplicationContext that instantiates the commands and performs the dependency injection. |
12 Configurations
Micronaut features several built-in configurations that enable integration with common databases and other servers.
12.1 Configurations for Data Access
The table summarizes the configuration modules and the dependencies you should add to your build to enable them.
| Dependency | Description |
|---|---|
|
Configures SQL DataSource instances using Commons DBCP |
|
Configures SQL DataSource instances using Hikari Connection Pool |
|
Configures SQL DataSource instances using Tomcat Connection Pool |
|
Configures Hibernate/JPA EntityManagerFactory beans |
|
Configures GORM for Hibernate for Groovy applications |
|
Configures the MongoDB Reactive Driver |
|
Configures GORM for MongoDB for Groovy applications |
|
Configures the Bolt Java Driver for Neo4j |
|
Configures GORM for Neo4j for Groovy applications |
|
Configures the Reactive Postgres Client |
|
|
|
Configures the Datastax Java Driver for Cassandra |
For example, to add support for MongoDB you define the following dependency:
build.gradle
compile "io.micronaut.configuration:micronaut-mongo-reactive"For Groovy users, Micronaut provides special support for GORM.
For GORM for Hibernate you should not have both the hibernate-jpa and hibernate-gorm dependency.
|
The following sections go into more detail about configuration options and the exposed beans for each implementation.
12.1.1 Configuring a SQL Data Source
Java data sources can be configured for one of three currently provided implementations. Apache DBCP2, Hikari, and Tomcat are supported by default.
Configuring a JDBC DataSource
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply one of the $ mn create-app my-app --features jdbc-tomcat |
To get started, simply add a dependency to one of the JDBC configurations that corresponds to the implementation you would like to use.
build.gradle
dependencies {
// Choose one of the following
compile "io.micronaut.configuration:micronaut-jdbc-tomcat"
compile "io.micronaut.configuration:micronaut-jdbc-hikari"
compile "io.micronaut.configuration:micronaut-jdbc-dbcp"
}You also need to add a JDBC driver dependency to your classpath. For example to add the H2 In-Memory Database:
build.gradle
runtime "com.h2database:h2"Configuring JDBC Connection Pools
All of the implementation specific parameters can be configured. Effort was made to allow basic configuration to be consistent across the implementations.
-
Hikari: The URL is able to be configured through
urlin addition tojdbcUrl. The JNDI name can be configured throughjndiNamein addition todataSourceJNDI. -
Tomcat: The JNDI name can be configured through
jndiNamein addition todataSourceJNDI.
Several configuration options will be calculated if they are not provided.
URL |
The classpath will be searched for an embedded database driver. If found, the URL will be set to the default value for that driver. |
Driver Class |
If the URL is configured, the driver class will be derived from the URL, otherwise the classpath will be searched for an embedded database driver. If found, the default class name for that driver will be used. |
Username |
If the configured database driver is embedded, the username will be set to "sa" |
Password |
If the configured database driver is embedded, the password will be set to an empty string. |
For example:
application.yaml
datasources.default: {}The above configuration will result in a single DataSource bean being registered with the named qualifier of default.
If for example, the H2 driver is on the classpath, it is equivalent to the following:
application.yaml
datasources:
default:
url: jdbc:h2:mem:default;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
username: sa
password: ""
driverClassName: org.h2.DriverFor a list of other properties able to be configured, simply refer to the implementation that is being used. All setter methods are candidates for configuration.
Tomcat |
|
Hikari |
|
Apache DBCP |
Configuring Multiple Data Sources
To register more than one data source, simply configure them under different names.
application.yaml
datasources:
default:
...
warehouse:
...When injecting DataSource beans, the one with the name "default" will be injected unless the injection is qualified with the configured name. If no configuration is named "default", none of the beans will be primary and thus all injections must be qualified. For example:
@Inject DataSource dataSource // "default" will be injected
@Inject @Named("warehouse") DataSource dataSource // "warehouse" will be injectedJDBC Health Checks
Once you have configured a JDBC DataSource the JdbcIndicator is activated resulting in the /health endpoint and CurrentHealthStatus interface resolving the health of the JDBC connection.
See the section on the Health Endpoint for more information.
Using Spring Transaction Management
If you wish to use Spring-based transaction management you can add the following dependencies to your application:
build.gradle
dependencies {
compile "io.micronaut:micronaut-spring"
runtime "org.springframework:spring-jdbc"
}Micronaut will automatically configure a DataSourceTransactionManager and wrap the DataSource in a TransactionAwareDataSourceProxy for each configured DataSource.
You should then use Micronaut’s @Transactional annotation to ensure low-overhead, compile-time transaction management is applied to your classes.
12.1.2 Configuring Hibernate
Setting up a Hibernate/JPA EntityManager
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features hibernate-jpa |
Micronaut features built in support for configuring a Hibernate / JPA EntityManager that builds on the SQL DataSource support.
Once you have configured one or many DataSources to use Hibernate, you will need to add the hibernate-jpa dependency to your build configuration:
build.gradle
compile "io.micronaut.configuration:micronaut-hibernate-jpa"And that is it. For each registered SQL DataSource, Micronaut will configure the following beans using EntityManagerFactoryBean:
-
StandardServiceRegistry - The Hibernate
StandardServiceRegistry -
MetadataSources - The Hibernate
MetadataSources -
SessionFactoryBuilder - The Hibernate
SessionFactoryBuilder -
SessionFactory - The Hibernate
SessionFactorybean which also implements the JPAEntityManagerFactoryinterface.
Injecting an EntityManager or Hibernate Session
You can use the javax.persistence.PersistenceContext annotation to inject an EntityManager (or Hibernate Session). To do so you need to make sure the JPA annotations are on the annotationProcessor path in your build:
Adding the JPA dependency to
annotationProcessor in GradleannotationProcessor "javax.persistence:javax.persistence-api:2.2"Using
@PersistenceContext@PersistenceContext
EntityManager entityManager;
@PersistenceContext(name = "other")
EntityManager otherManager;Micronaut will inject a compile time scoped proxy that retrieves the EntityManager associated with the current transaction when using @Transactional (see "Using Spring Transaction Management" below).
Note the examples above use field injection, since the @PersistenceContext annotation does not support declaration on a parameter of a constructor or method argument. Therefore if you wish to instead use constructor or method injection you must use the @CurrentSession instead:
Using
@CurrentSession for constructor injectionMyService(@CurrentSession EntityManager entityManager) {
this.entityManager = entityManager;
}
Customizing Hibernate / JPA Configuration
There are several different ways you can customize and configure how the SessionFactory is built. The easiest way is via configuration in application.yml. The following configuration demonstrates an example:
Configuring Hibernate Properties
datasources:
default:
name: 'mydb'
jpa:
default:
packages-to-scan:
- 'foo.bar'
- 'foo.baz'
properties:
hibernate:
hbm2ddl:
auto: update
show_sql: trueThe above example configures the packages to be scanned and sets properties to be passed to Hibernate. As you can see these are done on a per DataSource basis. Refer to the JpaConfiguration configuration class for the possible options.
If you need even further control over how the SessionFactory is built then you can register BeanCreatedEventListener beans that listen for the creation of the SessionFactoryBuilder, MetadataSources etc. and apply your custom configuration in the listener.
You may also optionally create beans of type Integrator and Interceptor and these will be picked up and injected automatically.
Using Spring Transaction Management
Micronaut’s Hibernate integration will also automatically provide a Spring HibernateTransactionManager bean so you can use Spring-based transaction management.
You should use Micronaut’s @Transactional annotation to ensure low-overhead, compile-time transaction management is applied to your classes.
Understanding LazyInitializationException
Micronaut is built on Netty which is based on a non-blocking, event loop model. JDBC and Hibernate are blocking APIs and hence when they are used in a Micronaut application the work is shifted to a blocking I/O thread pool.
When using @Transactional the Hibernate Session will only be open for the duration of this method execution and then will automatically be closed. This ensures that the blocking operation is kept as short as possible.
There is no notion of OpenSessionInView (OSIV) in Micronaut and never will be, since it is sub-optimal and not recommended. You should optimize the queries that you write to return all the necessary data Micronaut will need to encode your objects into JSON either by using the appropriate join queries or using a data transfer object (DTO).
If you encounter a LazyInitializationException when returning a Hibernate entity from a method it is an indication that your query is suboptimal and you should perform a join.
Using GORM for Hibernate
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features hibernate-gorm |
For Groovy users and users familiar with the Grails framework, special support for GORM for Hibernate is available. To use GORM for Hibernate you should not include Micronaut’s built in SQL Support or the hibernate-jpa dependency since GORM itself takes responsibility for creating the DataSource, SessionFactory etc.
Rather, you only need to include the hibernate-gorm dependency in your project, a connection pool implementation, and the desired JDBC driver. For example:
Configuring GORM for Hibernate
compile "io.micronaut.configuration:micronaut-hibernate-gorm"
// Use Tomcat connection pool
runtime 'org.apache.tomcat:tomcat-jdbc'
// Use H2 database driver
runtime 'com.h2database:h2'You can now use the same configuration properties described in the GORM documentation. For example:
Configuring GORM for Hibernate
dataSource:
pooled: true
dbCreate: create-drop
url: jdbc:h2:mem:devDb
driverClassName: org.h2.Driver
username: sa
password:
hibernate:
cache:
queries: false
use_second_level_cache: true
use_query_cache: false
region.factory_class: org.hibernate.cache.ehcache.EhCacheRegionFactoryThe following should be noted regarding using GORM for Hibernate in Micronaut:
-
Each class you wish to be a GORM entity should be annotated with the
grails.gorm.annotation.Entityannotation. -
Each method that interacts with GORM should be annotated with GORM’s
grails.gorm.transactions.Transactionalto ensure a session is present. You can also add the@Transactionalannotation to the class. -
By default Micronaut will scan for entities relative to your
Applicationclass. If you wish to customize this specify additional packages via the ApplicationContextBuilder when starting your application.
12.1.3 Configuring MongoDB
Setting up the Native MongoDB Driver
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features mongo-reactive |
Micronaut includes a configuration to automatically configure the native MongoDB Java driver. To use this configuration, add the following dependency to your application:
build.gradle
compile "io.micronaut.configuration:micronaut-mongo-reactive"Then configure the URI of the MongoDB server in application.yml:
Configuring a MongoDB server
mongodb:
uri: mongodb://username:password@localhost:27017/databaseName
The mongodb.uri follows the MongoDB Connection String format.
|
A non-blocking Reactive Streams MongoClient is then available for dependency injection.
To use the blocking driver, add a dependency to your application to the mongo-java-driver.
compile "org.mongodb:mongo-java-driver"Then the blocking MongoClient will be available for injection.
Configuring the MongoDB Driver
The configuration options for the blocking client and the non-blocking client differ at the driver level.
To configure the blocking client options you can use the mongodb.options setting which allows you to configure any property of the MongoClientOptions.Builder class. For example in application.yml:
Configuring Blocking Driver Options
mongodb:
...
options:
maxConnectionIdleTime: 10000
readConcern: majoritySee the API for DefaultMongoConfiguration for more information on the available configuration options.
For the Reactive driver, the ReactiveMongoConfiguration exposes options to configure the Reactive Streams driver. For example:
Configuring the Reactive Streams Driver
mongodb:
...
cluster:
maxWaitQueueSize: 5
connectionPool:
maxSize: 20Using Embedded MongoDB for Testing
For testing you can add a dependency on Embedded MongoDB and if the MongoDB server is not available on the configured port for the test environment an embedded MongoDB will be bootstrapped and made available for testing:
Add Embedded MongoDB
testCompile "de.flapdoodle.embed:de.flapdoodle.embed.mongo:2.0.1"Multiple MongoDB Drivers
You can create multiple MongoDB connections using the mongodb.servers setting. For example in application.yml:
Configuring Multiple MongoDB Drivers
mongodb:
servers:
another:
uri: mongodb://localhost:27018With the above configuration in place you can inject a MongoClient using the name another:
import com.mongodb.reactivestreams.client.*;
import javax.inject.*;
...
@Inject @Named("another") MongoClient mongoClient;MongoDB Health Checks
When the mongo-reactive module is activated a MongoHealthIndicator is activated resulting in the /health endpoint and CurrentHealthStatus interface resolving the health of the MongoDB connection.
See the section on the Health Endpoint for more information.
Using GORM for MongoDB
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features mongo-gorm |
For Groovy users and users familiar with Grails, special support has been added to Micronaut for using GORM for MongoDB.
To add support for GORM for MongoDB, first configure the MongoDB connection as per instructions earlier in the guide, then add the following dependency to your application:
build.gradle
compile "io.micronaut.configuration:micronaut-mongo-gorm"
For GORM for MongoDB you will need to configure the database name separately as the grails.mongodb.datataseName property in application.yml.
|
The following should be noted regarding using GORM for MongoDB in Micronaut:
-
Each class you wish to be a GORM entity should be annotated with the
grails.gorm.annotation.Entityannotation. -
Each method that interacts with GORM should be annotated with GORM’s
grails.gorm.transactions.Transactionalto ensure a session is present. You can also add the@Transactionalannotation to the class. -
By default Micronaut will scan for entities relative to your
Applicationclass. If you wish to customize this specify additional packages via the ApplicationContextBuilder when starting your application.
12.1.4 Configuring Neo4j
Micronaut features dedicated support for automatically configuring the Neo4j Bolt Driver for the popular Neo4j Graph Database.
Configuring Neoj4 Bolt
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features neo4j-bolt |
To configure the Neo4j Bolt driver you should first add the neo4j-bolt module to your classpath:
build.gradle
compile "io.micronaut.configuration:micronaut-neo4j-bolt"You should then configure the URI of the Neo4j server you wish to communicate with in application.yml:
Configuring
neo4j.urineo4j:
uri: bolt://localhost
The neo4j.uri setting should be in the format as described in the Connection URIs section of the Neo4j documentation
|
Once you have the above configuration in place you can inject an instance of the org.neo4j.driver.v1.Driver bean, which features both a synchronous blocking API and a non-blocking API based on CompletableFuture.
Customizing Neo4j Configuration
The configuration can be further customized with all the options available using the Neo4jBoltConfiguration class.
The Neo4jBoltConfiguration also exposes all the options for the org.neo4j.driver.v1.Config.ConfigBuilder class.
Below represents an example configuration:
Customizing the Bolt Configuration
neo4j:
uri: bolt://localhost
maxConnectionPoolSize: 50
connectionAcquisitionTimeout: 30s| You can also create a BeanCreatedEventListener bean and listen for the creation of the Neo4jBoltConfiguration to further programmatically customize configuration |
Embedding Neo4j for Testing
You can embed Neo4j for testing by including a dependency on the Neo4j test harness:
build.gradle
testRuntime "org.neo4j.test:neo4j-harness:3.3.3"If the Neo4j server is not already running on the configured port an embedded version will be started.
You can configure the options for the embedded Neo4j server using the neo4j.embedded settings exposed by Neo4jBoltConfiguration.
One useful option is ephemeral which ensures the data is cleaned up between test runs. For example in application-test.yml:
Using ephemeral
neo4j:
embedded:
ephemeral: trueNeo4j Health Checks
When the neo4j-bolt module is activated a Neo4jHealthIndicator is activated resulting in the /health endpoint and CurrentHealthStatus interface resolving the health of the Neo4j connection.
See the section on the Health Endpoint for more information.
Using GORM for Neo4j
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features neo4j-gorm |
For Groovy users and users familiar with Grails, special support has been added to Micronaut for using GORM for Neo4j.
To add support for GORM for Neo4j, first configure the Neo4j connection as per instructions earlier in the guide, then add the following dependency to your application:
build.gradle
compile "io.micronaut.configuration:micronaut-neo4j-gorm"The following should be noted regarding using GORM for Neo4j in Micronaut:
-
Each class you wish to be a GORM entity should be annotated with the
grails.gorm.annotation.Entityannotation. -
Each method that interacts with GORM should be annotated with GORM’s
grails.gorm.transactions.Transactionalto ensure a session is present. You can also add the@Transactionalannotation to the class. -
By default Micronaut will scan for entities relative to your
Applicationclass. If you wish to customize this specify additional packages via the ApplicationContextBuilder when starting your application.
12.1.5 Configuring Postgres
Micronaut supports reactive and non-blocking client to connect to Postgres using reactive-pg-client, allowing to handle many database connections with a single thread.
Configuring the Reactive Postgres Client
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features postgres-reactive |
To configure the Reactive Postgres client you should first add postgres-reactive module to your classpath:
build.gradle
compile "io.micronaut.configuration:micronaut-postgres-reactive"You should then configure the URI or PoolOptions of the Postgres server you wish to communicate with in application.yml:
application.yml
postgres:
reactive:
client:
port: 5432
host: the-host
database: the-db
user: test
password: test
maxSize: 5
You can also connect to Postgres using uri instead of the other properties.
|
Once you have the above configuration in place then you can inject the io.reactiverse.reactivex.pgclient.PgPool bean. The following is the simplest way to connect:
result = client.rxQuery('SELECT * FROM pg_stat_database').map({ PgRowSet pgRowSet -> (1)
int size = 0
PgIterator iterator = pgRowSet.iterator()
while (iterator.hasNext()) {
iterator.next()
size++
}
return "Size: ${size}"
}).blockingGet()| 1 | client is an instance of the io.reactiverse.reactivex.pgclient.PgPool bean. |
For more information on running queries on Postgres using the reactive client please read the "Running queries" section in the documentation of reactive-pg-client.
Postgres Health Checks
When the postgres-reactive module is activated a PgPoolHealthIndicator is activated resulting in the /health endpoint and CurrentHealthStatus interface resolving the health of the Postgres connection.
The only configuration option supported is to enable or disable the indicator by the endpoints.health.postgres.reactive.enabled key.
See the section on the Health Endpoint for more information.
12.1.6 Configuring Redis
Micronaut features automatic configuration of the Lettuce driver for Redis via the redis-lettuce module.
Configuring Lettuce
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features redis-lettuce |
To configure the Lettuce driver you should first add the redis-lettuce module to your classpath:
build.gradle
compile "io.micronaut.configuration:micronaut-redis-lettuce"You should then configure the URI of the Redis server you wish to communicate with in application.yml:
Configuring
redis.uriredis:
uri: redis://localhost
The redis.uri setting should be in the format as described in the Connection URIs section of the Lettuce wiki
|
You can also specify multiple Redis URIs using redis.uris in which case a RedisClusterClient is created instead.
Available Lettuce Beans
Once you have the above configuration in place you can inject one of the following beans:
-
io.lettuce.core.RedisClient- The main client interface -
io.lettuce.core.api.StatefulRedisConnection- A connection interface that features synchronous, reactive (based on Reactor) and async APIs that operate onStringvalues -
io.lettuce.core.pubsub.StatefulRedisPubSubConnection- A connection interface for dealing with Redis Pub/Sub
The following example demonstrates the use of the StatefulRedisConnection interface’s synchronous API:
Using StatefulRedisConnection
@Inject StatefulRedisConnection<String, String> connection
...
RedisCommands<String, String> commands = connection.sync()
commands.set("foo", "bar")
commands.get("foo") == "bar"
The Lettuce driver’s StatefulRedisConnection interface is designed to be long-lived and there is no need to close the connection. It will be closed automatically when the application shuts down.
|
Customizing The Redis Configuration
You can customize the Redis configuration using any properties exposed by the DefaultRedisConfiguration class. For example, in application.yml:
Customizing Redis Configuration
redis:
uri: redis://localhost
ssl: true
timeout: 30sMultiple Redis Connections
You can configure multiple Redis connections using the redis.servers setting. For example:
Customizing Redis Configuration
redis:
servers:
foo:
uri: redis://foo
bar:
uri: redis://barIn which case the same beans will be created for each entry under redis.servers but exposed as @Named beans.
Using StatefulRedisConnection
@Inject @Named("foo") StatefulRedisConnection<String, String> connection;The above example will inject the connection named foo.
Embedding Redis for Testing
You can run an embedded version of Redis for testing and CI scenarios by adding a dependency on the Embedded Redis project:
build.gradle
testCompile "com.github.kstyrc:embedded-redis:0.6"If Redis is unavailable for the configured Redis URI an embedded instance of Redis will be automatically be started and then shutdown at the end of the test (when stop is called on the ApplicationContext).
Redis Health Checks
When the redis-lettuce module is activated a RedisHealthIndicator is activated resulting in the /health endpoint and CurrentHealthStatus interface resolving the health of the Redis connection or connections.
See the section on the Health Endpoint for more information.
Using Redis as a Cache
You can use Redis as a cache implementation, see the section on Cache Advice for how to configure Redis backed caches.
Using Redis for HTTP Sessions
You can use Redis as a backing implementation for storing HTTP sessions. See the section on HTTP Sessions for more information on how to configure Redis backed sessions.
12.1.7 Configuring Cassandra
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features cassandra |
To enable the Cassandra configuration, add the following dependency to your application:
build.gradle
compile "io.micronaut.configuration:micronaut-cassandra"Micronaut supports Cassandra configuration by using the Datastax Java Driver. Configuration values can be supplied a property source such as below. The property name is derived from the builder methods in Cluster.Builder (without the prefix). Micronaut will create a Cluster bean. This bean can be then injected into any other Micronaut bean.
Supply Single Configuration
ApplicationContext applicationContext = new DefaultApplicationContext("test")
applicationContext.environment.addPropertySource(MapPropertySource.of(
'test',
['cassandra.default.clusterName': "ociCluster",
'cassandra.default.contactPoint': "localhost",
'cassandra.default.port': 9042,
'cassandra.default.maxSchemaAgreementWaitSeconds': 20,
'cassandra.default.ssl': true]
))
applicationContext.start()Multiple Cluster instances can be configured as follows:
Supply Multiple Configuration
ApplicationContext applicationContext = new DefaultApplicationContext("test")
applicationContext.environment.addPropertySource(MapPropertySource.of(
'test',
['cassandra.default.contactPoint': "localhost",
'cassandra.default.port': 9042,
'cassandra.secondary.contactPoint': "127.0.0.2",
'cassandra.secondary.port': 9043]
))
applicationContext.start()12.2 Other Configurations
This section covers other configurations available for use in Micronaut applications.
12.2.1 RabbitMQ
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features rabbitmq |
To get started with RabbitMQ in Micronaut, add the following dependency:
build.gradle
compile "io.micronaut.configuration:micronaut-rabbitmq"pom.xml
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-rabbitmq</artifactId>
</dependency>A RabbitMQ connection factory bean will be provided based on the configuration values supplied under the rabbitmq configuration key. All setter methods on ConnectionFactory are available to be configured.
For example:
rabbitmq:
uri: amqp://user:pass@host:10000/vhost
requestedFrameMax: 10
requestedChannelMax: 10
connectionTimeout: 500013 Language Support
Micronaut supports any JVM language that implements the Java Annotation Processor API.
Although Groovy, does not in fact support this API, special support has been built via an AST transformation. The current list of supported languages is: Java, Groovy and Kotlin (via the kapt tool).
| Theoretically any language that supports a way to analyze the AST at compile time could be supported. The io.micronaut.inject.writer package includes classes that are language neutral and are used to build BeanDefinition classes at compile time using the ASM tool. |
The following sections cover language specific features and considerations for using Micronaut.
13.1 Micronaut for Java
For Java, Micronaut uses a Java BeanDefinitionInjectProcessor annotation processor to process classes at compile time and produce BeanDefinition classes.
The major advantage here is that you pay a slight cost at compile time, but at runtime Micronaut is largely reflection-free, fast and consumes very little memory.
Using Micronaut with Java 9+
Micronaut is built with Java 8, however works fine with Java 9/10 and above as well. The classes that Micronaut generates sit along side existing classes within the same package, hence do not violate anything regarding the Java module system.
There are some considerations to take into account when using Java 9/10 with Micronaut.
The javax.annotation package
|
Using the CLI
If you are creating your project using the Micronaut CLI, the |
The javax.annotation, which includes @PostConstruct, @PreDestroy etc. is no longer part of the core JDK but instead a module. If you run under Java 9+ you will need to import the module or add the dependency to your classpath:
Adding the
javax.annotation dependencycompile 'javax.annotation:javax.annotation-api:1.3.2'Using Project Lombok
Project Lombok is a popular java library that adds a number of useful AST transformations to the Java language via annotation processors.
Since both Micronaut and Lombok use annotation processors, special care needs to be taken when configuring Lombok to ensure that the Lombok processor runs before Micronaut’s processor.
For example in Gradle adding the following dependencies to the dependencies block:
Configuring Lombok in Gradle
compileOnly 'org.projectlombok:lombok:1.16.20'
annotationProcessor "org.projectlombok:lombok:1.16.20"
...
// Micronaut processor define after Lombok
annotationProcessor "io.micronaut:micronaut-inject-java"Or when using Maven:
Configuring Lombok in Maven
<annotationProcessorPaths>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.0</version>
</path>
<path>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-inject-java</artifactId>
<version>${micronaut.version}</version>
</path>
</annotationProcessorPaths>| In both cases (Gradle and Maven) the Micronaut processor should be configured after the Lombok processor, reversing the order of the declared dependencies will not work. |
Configuring an IDE
You can use any IDE to develop Micronaut applications, if you depend on your configured build tool (Gradle or Maven) to build the application.
However, if you wish to run tests within the IDE that is currently possible with IntelliJ IDEA or Eclipse 4.9 M2 or above.
See the section on IDE Setup in the Quick start for more information on how to configure IntelliJ or Eclipse.
Retaining Parameter Names
By default with Java, the parameter name data for method parameters is not retained at compile time. This can be a problem for Micronaut if you do not define parameter names explicitly and depend on an external JAR that is already compiled.
Consider this interface:
Client Interface
interface HelloOperations {
@Get("/hello/{name}")
String hello(String name);
}At compile time the parameter name name is lost and becomes simply arg0 when compiled against or read via reflection later. To avoid this problem you have two options. You can either declare the parameter name explicitly:
Client Interface
interface HelloOperations {
@Get("/hello/{name}")
String hello(@QueryValue("name") String name);
}Or alternatively it is recommended that you compile all byte code with -parameters flag to javac. See Obtaining Names of Method Parameters. For example in build.gradle:
build.gradle
compileJava.options.compilerArgs += '-parameters'13.2 Micronaut for Groovy
The Groovy language has first class support in Micronaut.
Groovy Specific Modules
Additional modules exist specific to Groovy that improve the overall experience. These are detailed in the table below:
| Dependency | Description |
|---|---|
|
Includes AST transformations to generate bean definitions. Should be |
|
Adds the ability to specify configuration placed in |
|
Includes AST transforms that make it easier to write Functions for AWS Lambda |
The most common module you will need is micronaut-inject-groovy, which enables DI and AOP for classes written in Groovy.
Groovy Support in the CLI
The Command Line Interface for Micronaut includes special support for Groovy. To create a Groovy application use the groovy lang option. For example:
Create a Micronaut Groovy application
$ mn create-app hello-world --lang groovyThe above will generate a Groovy project, built with Gradle. You can use the -build maven flag to generate a project built with Maven instead.
Once you have created an application with the groovy feature commands like create-controller, create-client etc. will generate Groovy files instead of Java. The following example demonstrates this action when using interactive mode of the CLI:
Create a bean
$ mn
| Starting interactive mode...
| Enter a command name to run. Use TAB for completion:
mn>
create-bean create-client create-controller
create-job help
mn> create-bean helloBean
| Rendered template Bean.groovy to destination src/main/groovy/hello/world/HelloBean.groovyThe above example demonstrates creating a Groovy bean that looks like the following:
Micronaut Bean
package hello.world
import javax.inject.Singleton
@Singleton
class HelloBean {
}
Groovy automatically imports groovy.lang.Singleton which can be confusing as it conflicts with javax.inject.Singleton. Make sure you use javax.inject.Singleton when declaring a Micronaut singleton bean to avoid surprising behavior.
|
We can also create a client - don’t forget Micronaut can act as a client or a server!
Create a client
mn> create-client helloClient
| Rendered template Client.groovy to destination src/main/groovy/hello/world/HelloClient.groovyMicronaut Client
package hello.world
import io.micronaut.http.client.annotation.Client
import io.micronaut.http.annotation.Get
import io.micronaut.http.HttpStatus
@Client("hello")
interface HelloClient {
@Get
HttpStatus index()
}Now let’s create a controller:
Create a controller
mn> create-controller helloController
| Rendered template Controller.groovy to destination src/main/groovy/hello/world/HelloController.groovy
| Rendered template ControllerSpec.groovy to destination src/test/groovy/hello/world/HelloControllerSpec.groovy
mn>Micronaut Controller
package hello.world
import io.micronaut.http.annotation.Controller
import io.micronaut.http.annotation.Get
import io.micronaut.http.HttpStatus
@Controller("/hello")
class HelloController {
@Get
HttpStatus index() {
return HttpStatus.OK
}
}As you can see from the output from the CLI a Spock test was also generated for you demonstrating how to test the controller:
HelloControllerSpec.groovy
...
void "test index"() {
given:
HttpResponse response = client.toBlocking().exchange("/hello")
expect:
response.status == HttpStatus.OK
}
...Notice how you use Micronaut both as client and as a server to test itself.
Programmatic Routes with GroovyRouterBuilder
If you prefer to build your routes programmatically (similar to Grails UrlMappings) then a special io.micronaut.web.router.GroovyRouteBuilder exists that has some enhancements to make the DSL better.
The following example shows GroovyRouteBuilder in act:
Using GroovyRouteBuilder
@Singleton
static class MyRoutes extends GroovyRouteBuilder {
MyRoutes(ApplicationContext beanContext) {
super(beanContext)
}
@Inject
void bookResources(BookController bookController, AuthorController authorController) {
GET(bookController) {
POST("/hello{/message}", bookController.&hello) (1)
}
GET(bookController, ID) { (2)
GET(authorController)
}
}
}| 1 | You can use injected controllers to create routes by convention and Groovy method references to create routes to methods |
| 2 | The ID property can be used to reference include an {id} URI variable |
The above example results in the following routes:
-
/book- Maps toBookController.index() -
/book/hello/{message}- Maps toBookController.hello(String) -
/book/{id}- Maps toBookController.show(String id) -
/book/{id}/author- Maps toAuthorController.index
Using GORM in a Groovy application
GORM is a data access toolkit originally created as part of Grails framework. It supports multiple database types. The following table summarizes the modules needed to use GORM and links to documentation.
| Dependency | Description |
|---|---|
|
Configures GORM for Hibernate for Groovy applications. See the Hibernate Support docs |
|
Configures GORM for MongoDB for Groovy applications. See the Mongo Support docs. |
|
Configures GORM for Neo4j for Groovy applications. See the Neo4j Support docs. |
Once you have configured a GORM implementation per the instructions linked in the table above you can use all features of GORM.
GORM Data Services can also participate in dependency injection and life cycle methods:
GORM Data Service VehicleService.groovy
@Service(Vehicle)
abstract class VehicleService {
@PostConstruct
void init() {
// do something on initialization
}
abstract Vehicle findVehicle(@NotBlank String name)
abstract Vehicle saveVehicle(@NotBlank String name)
}You can also define the service as an interface instead of an abstract class if you want GORM to do all of the work and you don’t want to add your own behaviors.
Serverless Functions with Groovy
A microservice application is just one way to use Micronaut. You can also use it for serverless functions like on AWS Lambda.
With the function-groovy module, Micronaut features enhanced support for functions written in Groovy.
See the section on Serverless Functions for more information.
13.3 Micronaut for Kotlin
The Command Line Interface for Micronaut includes special support for Kotlin. To create a Kotlin application use the kotlin lang option. For example:
|
Create a Micronaut Kotlin application
$ mn create-app hello-world --lang kotlinSupport for Kotlin in Micronaut is built upon the Kapt compiler plugin, which includes support for Java annotation processors. To use Kotlin in your Micronaut application, you will simply need to add the proper dependencies to configure and run kapt on your kt source files. Kapt will create Java "stub" classes for each of your Kotlin classes, which can then be processed by Micronaut’s Java annotation processor. The stubs are not included in the final compiled application.
| Learn more about kapt and its features from the official documentation. |
The Micronaut annotation processors are declared in the kapt scope when using Gradle. For example:
Example build.gradle
dependencies {
compile "org.jetbrains.kotlin:kotlin-stdlib-jdk8:$kotlinVersion" (1)
compile "org.jetbrains.kotlin:kotlin-reflect:$kotlinVersion"
kapt "io.micronaut:micronaut-inject-java" (2)
kaptTest "io.micronaut:micronaut-inject-java" (3)
...
}| 1 | Add the Kotlin standard libraries |
| 2 | Add the micronaut-inject-java dependency under the kapt scope, so classes in src/main are processed |
| 3 | Add the micronaut-inject-java dependency under the kaptTest scope, so classes in src/test are processed. |
With a build.gradle file similar to the above, you can now run your Micronaut application using the run task (provided by the Application plugin):
$ ./gradlew runAn example controller written in Kotlin can be seen below:
src/main/kotlin/example/HelloController.kt
package example
import io.micronaut.http.annotation.*
@Controller("/")
class HelloController {
@Get("/hello/{name}")
fun hello(name: String): String {
return "Hello $name"
}
}13.3.1 Kotlin, Kapt and IntelliJ
As of this writing IntelliJ’s built-in compiler does not directly support Kapt and annotation processing. You must instead configure Intellij to run Gradle (or Maven) compilation as a build step before running your tests or application class.
First edit the run configuration for tests or for the application and select "Run Gradle task" as a build step:
Then add the classes task as task to execute for the application or for tests the testClasses task:
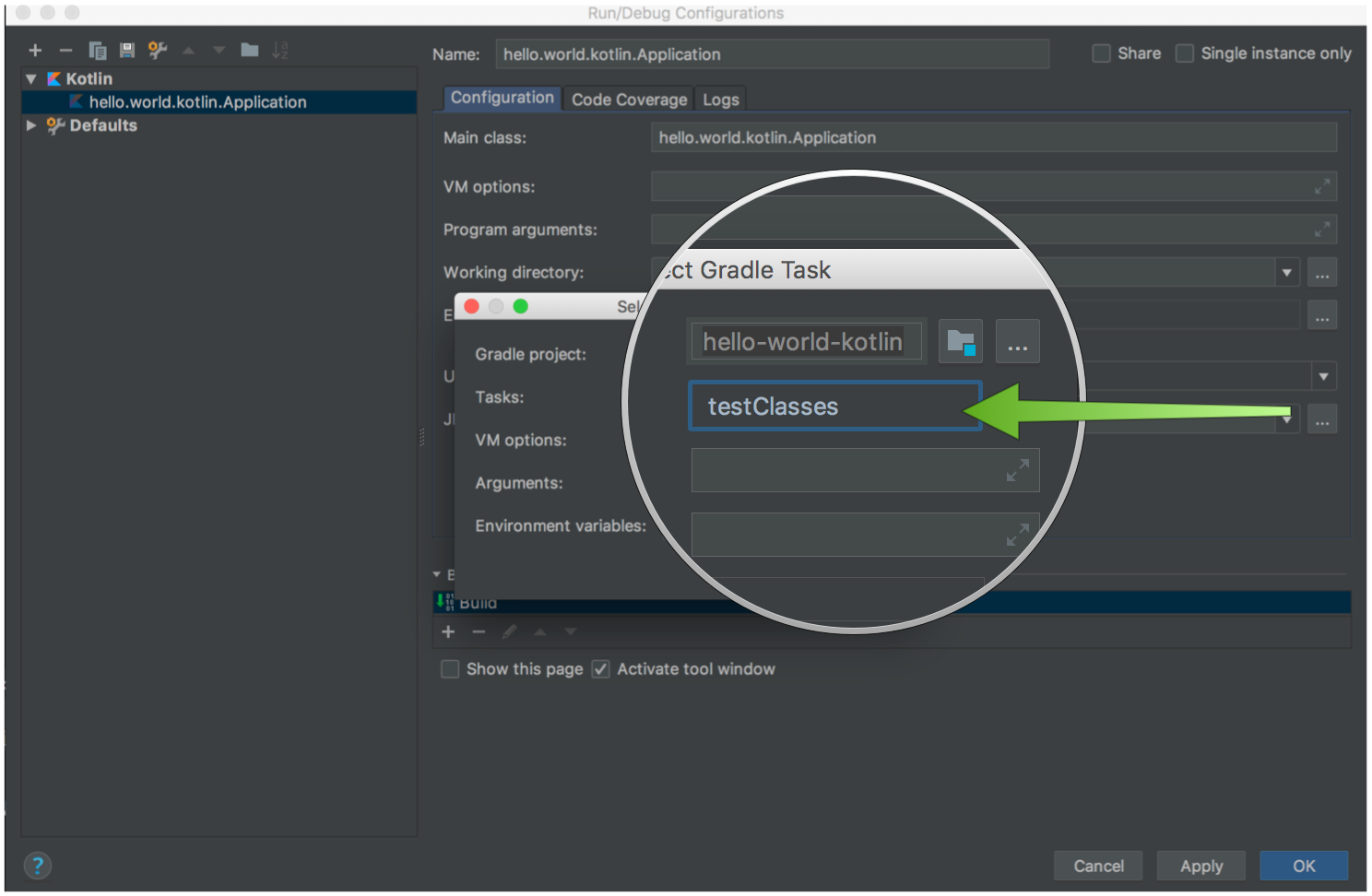
Now whenever you run tests or the application Micronaut classes will be generated at compilation time.
Alternatively, you can delegate IntelliJ build/run actions to Gradle completely:
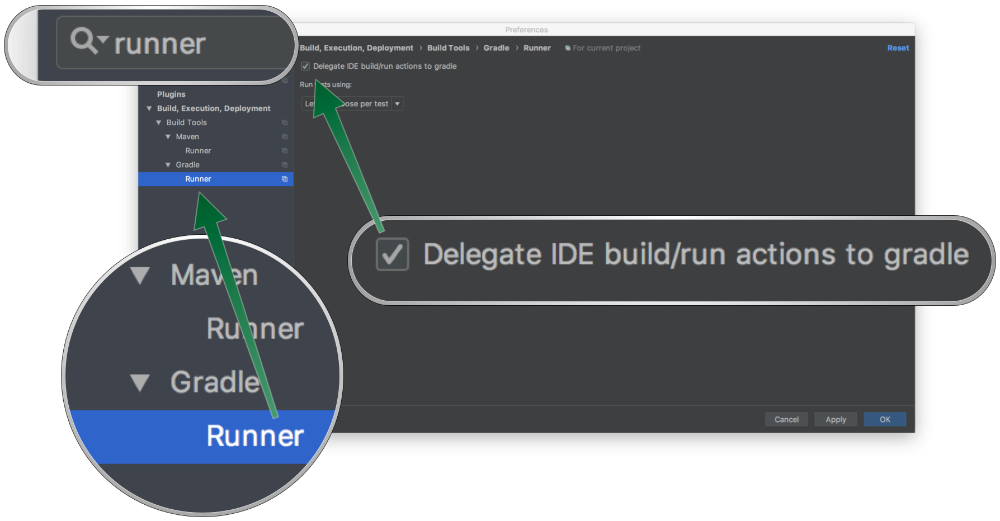
13.3.2 Kotlin and AOP Advice
Micronaut provides a compile-time AOP API that does not use reflection. When you use any Micronaut’s AOP Advice,
it creates a subclass at compile-time to provide the AOP behaviour. This can be a problem because Kotlin classes are final by default. If the application was created with the Micronaut CLI, then the Kotlin all-open plugin is configured for you to automatically change your classes to open when an AOP annotation is used. To configure it yourself, simply add the Around class to the list of supported annotations.
If you prefer not to or cannot use the all-open plugin, you must declare the classes that are annotated with an AOP annotation to be open:
import io.micronaut.http.annotation.Controller
import io.micronaut.http.annotation.Get
import io.micronaut.http.HttpStatus
import io.micronaut.validation.Validated
import javax.validation.constraints.NotBlank
@Validated
@Controller("/email")
open class EmailController { (1)
@Get("/send")
fun index(@NotBlank recipient: String, (1)
@NotBlank subject: String): HttpStatus {
return HttpStatus.OK
}
}| 1 | if you use @Validated AOP Advice, you need to use open at class and method level. |
The all-open plugin does not handle methods. If you declare an AOP annotation on a method, you must manually declare it as open.
|
13.3.3 Kotlin and Retaining Parameter Names
Like with Java, the parameter name data for method parameters is not retained at compile time when using Kotlin. This can be a problem for Micronaut if you do not define parameter names explicitly and depend on an external JAR that is already compiled.
To enable the retention of parameter name data with Kotlin you should set the javaParameters option to true in your build.gradle:
build.gradle
compileTestKotlin {
kotlinOptions {
jvmTarget = '1.8'
javaParameters = true
}
}13.4 Micronaut for GraalVM
GraalVM is a new universal virtual machine from Oracle that supports a polyglot runtime environment and the ability to compile Java applications down to native machine code.
Any Micronaut application can be run using the GraalVM JVM, however special support has been added to Micronaut to support running Micronaut applications using GraalVM’s nativeimage tool.
Experimental Status
| GraalVM support (like GraalVM itself) is still in the incubating phase. Third-party library support is hit and miss and the Micronaut team are still ironing out all of the potential issues. Don’t hesitate to report issues however and gradually over time the support will become more stable. |
So far Micronaut’s HTTP server, HTTP client, function support and service discovery module have been verified as working on GraalVM 1.0 RC6 or above. Support for other modules is still evolving and will improve over time.
Getting Started
Use of GraalVM’s nativeimage tool is only supported in Java or Kotlin projects. Groovy relies heavily on reflection which is only partially supported by GraalVM.
|
To start using GraalVM you should first install the GraalVM SDK via the Getting Started.
| As of this writing, GraalVM is currently only available for Linux and Mac OS X systems. |
To compile Micronaut and Graal applications you need to make the substrate VM dependency available to your application. The easiest way to make it available is via Docker:
Using Docker to Obtain the SVM Dependency
docker run oracle/graalvm-ce:1.0.0-rc7 cat /usr/java/latest/jre/lib/svm/builder/svm.jar > svm.jarOnce you have obtained the svm.jar from the latest Graal Docker images you can install it into your local Maven cache:
Installing the SVM Dependency Locally
$ mvn install:install-file -Dfile=svm.jar \
-DgroupId=com.oracle.substratevm \
-DartifactId=svm \
-Dversion=GraalVM-1.0.0-rc7 \
-Dpackaging=jar13.4.1 Microservices as GraalVM native images
Getting Started with Micronaut and Graal
To get started creating a Microservice that can be compiled into a native image, use the graal-native-image feature when creating the application with the CLI:
Creating a Graal Native Microservice
$ mn create-app hello-world --features graal-native-imageThe graal-native-image feature adds 3 important items:
-
A
MicronautSubstitutions.javafile needed to recompute Netty and Caffeine’s use ofUnsafe. -
The
svmandgraaldependencies to yourbuild.gradle(orpom.xmlif--build mavenis used). -
A
Dockerfilewhich can be used to construct the native image.
To build your native image using Docker simply run:
$ docker build . -t hello-world
$ docker run hello-worldUnderstanding Micronaut and Graal
Although Micronaut Dependency Injection does not use reflection, Micronaut does heavily rely on dynamic class loading. GraalVM needs to know ahead of time all the classes that are to be dynamically loaded.
So before you can build a native image Micronaut needs to compute your application’s classloading requirements. The Dockerfile does this automatically for you, but you can also run the logic to generate Graal’s reflect.json file manually:
Computing Class Loading Requirements
$ ./gradlew assemble
$ java -cp build/libs/hello-world-0.1-all.jar io.micronaut.graal.reflect.GraalClassLoadingAnalyzerThe GraalClassLoadingAnalyzer will write out a reflect.json file computing the classloading requirements of the application.
The default is to write this file to the build directory for Gradle and the target directory for Maven. You can alter the destination by specifying an argument:
Writing
reflect.json to a custom location$ java -cp build/libs/hello-world-0.1-all.jar io.micronaut.graal.reflect.GraalClassLoadingAnalyzer somelocation/myreflect.jsonThe generated reflect.json file contains the classes that were dynamically loaded by the application when started up. See GraalVM documentation for information on the JSON format.
If you wish you can use this file as a template and copy it to the source tree, making modifications as necessary and then altering the Dockerfile template to point to the new location.
|
Once the reflect.json file is ready you can run the native-image command. The script runs the following native-image command:
The
native-image commandnative-image --class-path build/libs/hello-world-0.1-all.jar \ (1)
-H:ReflectionConfigurationFiles=build/reflect.json \ (2)
-H:EnableURLProtocols=http \ (3)
-H:IncludeResources="logback.xml|application.yml|META-INF/services/*.*" \ (4)
-H:Name=hello-world \ (5)
-H:Class=hello.world.Application \ (6)
-H:+ReportUnsupportedElementsAtRuntime \ (7)
-H:+AllowVMInspection \
--rerun-class-initialization-at-runtime='sun.security.jca.JCAUtil$CachedSecureRandomHolder,javax.net.ssl.SSLContext' \
--delay-class-initialization-to-runtime=io.netty.handler.codec.http.HttpObjectEncoder,io.netty.handler.codec.http.websocketx.WebSocket00FrameEncoder,io.netty.handler.ssl.util.ThreadLocalInsecureRandom (8)| 1 | The class-path argument is used to refer to the Micronaut shaded JAR |
| 2 | The -H:ReflectionConfigurationFiles points GraalVM to the reflect.json file needed to run the application |
| 3 | Micronaut uses the JVM’s default URL connection classes. The -H:EnableURLProtocols allows using them in GraalVM nativeimage. |
| 4 | The -H:IncludeResources argument specifies a regex to dictate which static resources should be included in the image. |
| 5 | The -H:Name argument specifies the name of the native image to be built |
| 6 | The -H:Class argument specifies the Java main class that is the entry point of the application. |
| 7 | The -H:+ReportUnsupportedElementsAtRuntime tells GraalVM to report any ClassNotFoundException errors at runtime instead of at build time. |
| 8 | The --delay-class-initialization-to-runtime specifies which classes static initializers should be delayed until runtime. GraalVM by default runs static initializers at build time. That is undesirable is certain cases (particularly with Netty). |
Once the image has been built you can run the application using the native image name:
Running the Native Application
$ ./hello-world
15:15:15.153 [main] INFO io.micronaut.runtime.Micronaut - Startup completed in 14ms. Server Running: http://localhost:8080As you can see the advantage of having a native image is startup completes in milliseconds and memory consumption does not include the overhead of the JVM (a native Micronaut application runs with just 20mb of memory).
13.4.2 GraalVM and Micronaut FAQ
How does Micronaut manage to run on GraalVM?
Micronaut features a Dependency Injection and Aspect-Oriented Programming runtime that uses no reflection. This makes it easier for Micronaut applications to run on GraalVM since there are limitations particularly around reflection on SubstrateVM.
What about Third-Party Libraries?
Micronaut cannot guarantee that third-party libraries work on GraalVM SubstrateVM, that is down to each individual library to implement support.
I Get a "Class XXX is instantiated reflectively…" Exception. What do I do?
If you get an error such as:
Class myclass.Foo[] is instantiated reflectively but was never registered. Register the class by using org.graalvm.nativeimage.RuntimeReflection
You may need to manually tweak the generated reflect.json file. For regular classes you need to add an entry into the array:
[
{
"name" : "myclass.Foo",
"allDeclaredConstructors" : true
},
...
]For arrays this needs to use the Java JVM internal array representation. For example:
[
{
"name" : "[Lmyclass.Foo;",
"allDeclaredConstructors" : true
},
...
]14 Management & Monitoring
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features management |
Inspired by Spring Boot and Grails, the Micronaut management dependency adds support for monitoring of your application via endpoints: special URIs that return details about the health and state of your application. The management endpoints are also integrated with Micronaut’s security dependency, allowing for sensitive data to be restricted to authenticated users in your security system (see Built-in Endpoints Access in the Security section).
To use the management features described in this section, add the dependency on your classpath. For example, in build.gradle
build.gradle
compile "io.micronaut:micronaut-management"14.1 Creating Endpoints
In addition to the Built-In Endpoints, the management dependency also provides support for creating custom endpoints. Custom endpoints can be enabled and configured identically to the built-in endpoints, and can be used to retrieve and return any metrics or other application data that you require.
14.1.1 The Endpoint Annotation
An Endpoint can be created by annotating a class with the Endpoint annotation, and supplying it with (at minimum) an endpoint id.
FooEndpoint.java
@Endpoint("foo")
class FooEndpoint {
...
}If a single String argument is supplied to the annotation, it will be used as the endpoint id.
It is possible to supply additional (named) arguments to the annotation. Other possible arguments to @Endpoint are described in the table below:
| Argument | Description | Endpoint Example |
|---|---|---|
|
The endpoint id (or name) |
|
|
Prefix used for configuring the endpoint (see Endpoint Configuration) |
|
|
Sets whether the endpoint is enabled when no configuration is set (see Endpoint Configuration) |
|
|
Sets whether the endpoint is sensitive if no configuration is set (see Endpoint Configuration) |
|
Example of custom Endpoint
The following example Endpoint class will create an endpoint accessible at /date:
CurrentDateEndpoint.groovy
import io.micronaut.management.endpoint.annotation.Endpoint
@Endpoint(id = "date",
prefix = "custom",
defaultEnabled = true,
defaultSensitive = false)
class CurrentDateEndpoint {
//.. endpoint methods
}14.1.2 Endpoint Methods
Endpoints respond to GET ("read"), POST ("write") and DELETE ("delete") requests. To return a response from an endpoint, annotate its public method/s with one of following annotations:
| Annotation | Description |
|---|---|
Responds to |
|
Responds to |
|
Responds to |
Read Methods
Annotating a method with the Read annotation will cause it to respond to GET requests.
CurrentDateEndpoint.groovy
import io.micronaut.management.endpoint.annotation.Endpoint
import io.micronaut.management.endpoint.annotation.Read
@Endpoint(id = "date",
prefix = "custom",
defaultEnabled = true,
defaultSensitive = false)
class CurrentDateEndpoint {
Date currentDate
@Read
Date currentDate() {
return currentDate
}
}The above method responds to the following request:
$ curl -X GET localhost:55838/date
1526085903689The Read annotation accepts an optional produces argument, which sets the media type returned from the method (default is application/json):
CurrentDateEndpoint.groovy
import io.micronaut.management.endpoint.annotation.Endpoint
import io.micronaut.management.endpoint.annotation.Read
@Endpoint(id = "date",
prefix = "custom",
defaultEnabled = true,
defaultSensitive = false)
class CurrentDateEndpoint {
Date currentDate
@Read(produces = MediaType.TEXT_PLAIN) (1)
String currentDatePrefix(@Selector String prefix) {
return "${prefix}: ${currentDate}"
}
}| 1 | Supported media types are represented by MediaType |
The above method responds to the following request:
$ curl -X GET localhost:8080/date/the_date_is
the_date_is: Fri May 11 19:24:21 CDTWrite Methods
Annotating a method with the Write annotation will cause it to respond to POST requests.
CurrentDateEndpoint.groovy
import io.micronaut.management.endpoint.annotation.Endpoint
import io.micronaut.management.endpoint.annotation.Write
import io.micronaut.http.MediaType
import io.micronaut.management.endpoint.annotation.Selector
@Endpoint(id = "date",
prefix = "custom",
defaultEnabled = true,
defaultSensitive = false)
class CurrentDateEndpoint {
Date currentDate
@Write
String reset() {
currentDate = new Date()
return "Current date reset"
}
}The above method responds to the following request:
$ curl -X POST http://localhost:39357/date
Current date resetThe Write annotation accepts an optional consumes argument, which sets the media type accepted by the method (default is application/json):
MessageEndpoint.groovy
import io.micronaut.management.endpoint.annotation.Endpoint
import io.micronaut.management.endpoint.annotation.Write
import io.micronaut.http.MediaType
@Endpoint(id = "message", defaultSensitive = false)
class MessageEndpoint {
String message
@Write(consumes = MediaType.APPLICATION_JSON)
String updateMessage(String newMessage) { (1)
message = newMessage
return "Message updated"
}
}The above method responds to the following request:
$ curl -X POST http://localhost:65013/message -H 'Content-Type: application/json' -d $'{"newMessage": "A new message"}'
Message updatedDelete Methods
Annotating a method with the Delete annotation will cause it to respond to DELETE requests.
MessageEndpoint.groovy
import io.micronaut.management.endpoint.annotation.Endpoint
import io.micronaut.management.endpoint.annotation.Delete
@Endpoint(id = "message", defaultSensitive = false)
class MessageEndpoint {
String message
@Delete
String deleteMessage() {
message = null
return "Message deleted"
}
}The above method responds to the following request:
$ curl -X DELETE http://localhost:65013/message
Message deleted14.1.3 Endpoint Configuration
Endpoints with the endpoints prefix can be configured through their default endpoint id. If an endpoint exists with the id of foo, it can be configured through endpoints.foo. In addition, default values can be provided through the all prefix.
For example, consider the following endpoint.
FooEndpoint.java
@Endpoint("foo")
class FooEndpoint {
...
}By default the endpoint will be enabled. To disable the endpoint, set endpoints.foo.enabled to false. If endpoints.foo.enabled is not set at all and endpoints.all.enabled is set to false, the endpoint will be disabled.
The configuration values for the endpoint override the ones for all. If endpoints.foo.enabled is explicitly set to true and endpoints.all.enabled is explicitly set to false, the endpoint will be enabled.
For all endpoints, the following configuration values can be set.
endpoints:
<any endpoint id>:
enabled: Boolean
sensitive: Boolean
id: StringIf the endpoint id is set through configuration, the URL where the endpoint is accessible also changes to reflect the value. For example if the foo endpoint id was changed to bar, the foo endpoint would be executed through http://localhost:<port>/bar.
The base path for all endpoints is / by default. If you prefer the endpoints to be available under a different base path, configure endpoints.all.path. For example, if the value is set to /endpoints, the foo endpoint will be accessible at /endpoints/foo.
|
14.2 Built-In Endpoints
When the management dependency is added to your project, the following built-in endpoints are enabled by default:
| Endpoint | URI | Description |
|---|---|---|
|
Returns information about the loaded bean definitions in the application (see BeansEndpoint) |
|
|
Returns static information from the state of the application (see InfoEndpoint) |
|
|
Returns information about the "health" of the application (see HealthEndpoint) |
|
|
Return the application metrics. Requires the |
|
|
Refreshes the application state (see RefreshEndpoint) |
|
|
Returns information about URIs available to be called for your application (see RoutesEndpoint) |
|
|
Returns information about available loggers and permits changing the configured log level (see LoggersEndpoint) |
In addition, the following built-in endpoint(s) are provided by the management dependency but are not enabled by default:
| Endpoint | URI | Description |
|---|---|---|
|
Shuts down the application server (see ServerStopEndpoint) |
JMX
Micronaut provides functionality to register endpoints with JMX. See the section on JMX to get started.
14.2.1 The Beans Endpoint
The beans endpoint returns information about the loaded bean definitions in the application. The bean data returned by default is an object where the key is the bean definition class name and the value is an object of properties about the bean.
To execute the beans endpoint, send a GET request to /beans.
Configuration
To configure the beans endpoint, supply configuration through endpoints.beans.
Beans Endpoint Configuration Example
endpoints:
beans:
enabled: Boolean
sensitive: Boolean
id: StringCustomization
The beans endpoint is composed of a bean definition data collector and a bean data implementation. The bean definition data collector (BeanDefinitionDataCollector) is responsible for returning a publisher that will return the data used in the response. The bean definition data (BeanDefinitionData) is responsible for returning data about an individual bean definition.
To override the default behavior for either of the helper classes, either extend the default implementations (RxJavaBeanDefinitionDataCollector, DefaultBeanDefinitionData), or implement the relevant interface directly. To ensure your implementation is used instead of the default, add the @Replaces annotation to your class with the value being the default implementation.
14.2.2 The Info Endpoint
The info endpoint returns static information from the state of the application. The info exposed can be provided by any number of "info sources".
To execute the info endpoint, send a GET request to /info.
Configuration
To configure the info endpoint, supply configuration through endpoints.info.
Info Endpoint Configuration Example
endpoints:
info:
enabled: Boolean
sensitive: Boolean
id: StringCustomization
The info endpoint consists of an info aggregator and any number of info sources. To add an info source, simply create a bean class that implements InfoSource. If your info source needs to retrieve data from Java properties files, you can extend the PropertiesInfoSource interface which provides a helper method for this purpose.
All of the info source beans will be collected together with the info aggregator. To provide your own implementation of the info aggregator, create a class that implements InfoAggregator and register it as a bean. To ensure your implementation is used instead of the default, add the @Replaces annotation to your class with the value being the default implementation.
The default info aggregator returns map containing the combined properties returned by all the info sources. This map is returned as JSON from the /info endpoint.
Provided Info Sources
Configuration Info Source
The ConfigurationInfoSource will return configuration properties under the info key. In addition to string, integer and boolean values, more complex properties can be exposed as maps in the JSON output (if the configuration format supports it).
Info Source Example (
application.groovy)info.demo.string = "demo string"
info.demo.number = 123
info.demo.map = [key: 'value', other_key: 123]The above config will result in the following JSON response from the info endpoint:
{
"demo": {
"string": "demo string",
"number": 123,
"map": {
"key": "value",
"other_key": 123
}
}
}Configuration
The configuration info source can be disabled using the endpoints.info.config.enabled property.
Git Info Source
If a git.properties file is available on the classpath, the GitInfoSource will expose the values in that file under the git key. Generating of a git.properties file will need to be configured as part of your build; for example, you may choose to use the Gradle Git Properties plugin.
plugins {
id "com.gorylenko.gradle-git-properties" version "1.4.21"
}Configuration
To specify an alternate path/name of the properties file, you can supply a custom value in the endpoints.info.git.location property.
The git info source can be disabled using the endpoints.info.git.enabled property.
Build Info Source
If a META-INF/build-info.properties file is available on the classpath, the BuildInfoSource will expose the values in that file under the build key. Generating of a build-info.properties file will need to be configured as part of your build.
Configuration
To specify an alternate path/name of the properties file, you can supply a custom value in the endpoints.info.build.location property.
The build info source can be disabled using the endpoints.info.build.enabled property.
14.2.3 The Health Endpoint
The health endpoint returns information about the "health" of the application. The application health is determined by any number of "health indicators".
To execute the health endpoint, send a GET request to /health.
Configuration
To configure the health endpoint, supply configuration through endpoints.health.
Health Endpoint Configuration Example
endpoints:
health:
enabled: Boolean
sensitive: Boolean
id: String
details-visible: String (1)
status:
http-mapping: Map<String, HttpStatus>| 1 | One of DetailsVisibility |
The details-visible setting is used to control whether health detail should be exposed to users who are not authenticated.
For example setting:
Using
details-visibleendpoints:
health:
details-visible: ANONYMOUSWill expose detailed information read from the various health indicators about the health status of the application to anonymous unauthenticated users.
The endpoints.health.status.http-mapping setting can be used to control what status codes are returned for each health status. The defaults are described in the table below:
| Status | HTTP Code |
|---|---|
OK (200) |
|
OK (200) |
|
SERVICE_UNAVAILABLE (503) |
You can provide custom mappings in application.yml:
Custom Health Status Codes
endpoints:
health:
status:
http-mapping:
DOWN: 200The above will return OK (200) even when the HealthStatus is DOWN.
Customization
The health endpoint consists of a health aggregator and any number of health indicators. To add a health indicator, simply create a bean class that implements HealthIndicator. A base class AbstractHealthIndicator has been provided for you to extend to make the process easier.
All of the health indicator beans will be collected together with the health aggregator. To provide your own implementation of the health aggregator, create a class that implements HealthAggregator and register it as a bean. To ensure your implementation is used instead of the default, add the @Replaces annotation to your class with the value being the default implementation.
The default health aggregator returns an overall status that is calculated based on the health statuses of the indicators. A health status consists of several pieces of information.
Name |
The name of the status |
Description |
The description of the status |
Operational |
Whether the functionality the indicator represents is functional |
Severity |
How severe the status is. A higher number is more severe |
The "worst" status will be returned as the overall status. A non operational status will be selected over an operational status. A higher severity will be selected over a lower severity.
Provided Indicators
Disk Space
A health indicator is provided that determines the health of the application based on the amount of free disk space. Configuration for the disk space health indicator can be provided under the endpoints.health.disk-space key.
Disk Space Indicator Configuration Example
endpoints:
health:
disk-space:
enabled: Boolean
path: String #The file path used to determine the disk space
threshold: String | Long #The minimum amount of free spaceThe threshold can be provided as a string like "10MB" or "200KB", or the number of bytes.
JDBC
The JDBC health indicator determines the health of your application based on the ability to successfully create connections to datasources in the application context. The only configuration option supported is to enable or disable the indicator by the endpoints.health.jdbc.enabled key.
Discovery Client
If your application is using service discovery, a health indicator will be included to monitor the health of the discovery client. The data returned can include a list of the services available.
14.2.4 The Metrics Endpoint
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply one of $ mn create-app my-app --features micrometer-atlas |
The metrics endpoint returns information about the "metrics" of the application. To execute the metrics endpoint, send a GET request to /metrics. This will return a list of the metric names registered with the MeterRegistry bean.
You can get specific metrics by using /metrics/[name] such as /metrics/jvm.memory.used. This would return something like:
Sample Metric Detail Json
{
"name": "jvm.memory.used",
"measurements": [
{
"statistic": "VALUE",
"value": 1.45397552E8
}
],
"availableTags": [
{
"tag": "area",
"values": [
"heap",
"nonheap"
]
},
{
"tag": "id",
"values": [
"Compressed Class Space",
"PS Survivor Space",
"PS Old Gen",
"Metaspace",
"PS Eden Space",
"Code Cache"
]
}
]
}You can further limit the metric by using a tag like /metrics/jvm.memory.used?tag=id:PS%20Old%20Gen.
Sample Metric Detail Json
{
"name": "jvm.memory.used",
"measurements": [
{
"statistic": "VALUE",
"value": 1.1434488E7
}
],
"availableTags": [
{
"tag": "area",
"values": [
"heap"
]
}
]
}You may even use multiple/nested tags like /metrics/jvm.memory.used?tag=id:PS%20Old%20Gen&tag=area:heap.
Sample Metric Detail Json
{
"name": "jvm.memory.used",
"measurements": [
{
"statistic": "VALUE",
"value": 1.1434488E7
}
]
}Configuration
Currently the metrics endpoint will only be enabled if you include the micrometer-core (or one of the typed registries such as micrometer-registry-statsd or micrometer-registry-graphite) AND the management dependencies. You will also need to have the global metrics flag enabled (true by default).
Property
micronaut:
metrics:
enabled: trueGradle
dependencies {
...
compile "io.micronaut.configuration:micronaut-micrometer-core"
// micrometer-registry-statsd also pulls in micrometer-core so included above to verbose example
compile "io.micronaut.configuration:micronaut-micrometer-registry-statsd"
// Also required to enable endpoint
compile "io.micronaut:micronaut-management"
...
}Maven
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-micrometer-core</artifactId>
<version>${micronaut.version}</version>
</dependency>
<!-- micrometer-registry-statsd also pulls in micrometer-core so included above to verbose example -->
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-micrometer-registry-statsd</artifactId>
<version>${micronaut.version}</version>
</dependency>
<!-- Also required to enable endpoint -->
<dependency>
<groupId>io.micronaut</groupId>
<artifactId>micronaut-management</artifactId>
<version>${micronaut.version}</version>
</dependency>To configure the metrics endpoint, supply configuration through endpoints.metrics.
Metrics Endpoint Configuration Example
endpoints:
metrics:
enabled: Boolean
sensitive: Boolean
id: StringMetric Concepts
Key Micrometer.io concepts include
a MeterRegistry to register and use
meters. A Meter is something that produces metrics.
A MeterRegistry can have some customizations automatically applied.
Meter Registry Configurer
-
Any bean that implements
MeterRegistryConfigurergets applied to every applicable MeterRegistry bean on creation -
The implementation of the MeterRegistryConfigurer
supports()method determines if the configurer is applied to a particular registry-
If you want all registries to get the customization, simply return return
true -
Otherwise, you can evaluate the registry for its class type, its class hierarchy, or other criteria.
-
Remember you only get one shot for autoconfiguration; i.e. when the bean context is started.
-
However, in code, you can apply additional customizations to the registry config
-
MeterRegistryConfigurer Interface
/*
* Copyright 2017-2018 original authors
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.micronaut.configuration.metrics.aggregator;
import io.micrometer.core.instrument.MeterRegistry;
/**
* Class that will configure meter registries. This is done on bean added event so that
* composite registry can be skipped and non-composite registries can be added to composite.
*
* @author Christian Oestreich
* @param <T> an instance of a meter registry that will be configured
* @since 1.0
*/
public interface MeterRegistryConfigurer<T extends MeterRegistry> {
/**
* Method to configure a meter registry with binders, filters, etc.
*
* @param meterRegistry Meter Registry
*/
void configure(T meterRegistry);
/**
* Method to determine if this configurer supports the meter registry type.
*
* @param meterRegistry a meter registry
* @return boolean whether is supported
*/
boolean supports(T meterRegistry);
}Example
package io.micronaut.docs;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.simple.SimpleMeterRegistry;
import io.micronaut.configuration.metrics.aggregator.MeterRegistryConfigurer;
public class SimpleMeterRegistryConfigurer implements MeterRegistryConfigurer {
@Override
public void configure(MeterRegistry meterRegistry) {
meterRegistry.config().commonTags("key", "value");
}
@Override
public boolean supports(MeterRegistry meterRegistry) {
return meterRegistry instanceof SimpleMeterRegistry;
}
}Meter Filter
-
A meter filter can be used to determine if a Meter is to be added to the registry. See Meter Filters
-
Any bean that implements MeterFilter will be applied to all registries when the registry is first created
You can create custom filters similar to the following inside your application. Micrometer’s MeterFilter class provides several convenience methods to help with the creation of these filters.
Example
package io.micronaut.docs;
import io.micrometer.core.instrument.Tag;
import io.micrometer.core.instrument.config.MeterFilter;
import io.micronaut.context.annotation.Bean;
import io.micronaut.context.annotation.Factory;
import javax.inject.Singleton;
import java.util.Arrays;
@Factory
public class MeterFilterFactory {
/**
* Exclude metrics starting with jvm
*
* @return meter filter
*/
@Bean
@Singleton
MeterFilter jvmExclusionFilter() {
return MeterFilter.denyNameStartsWith("jvm");
}
/**
* Add global tags to all metrics
*
* @return meter filter
*/
@Bean
@Singleton
MeterFilter addCommonTagFilter() {
return MeterFilter.commonTags(Arrays.asList(Tag.of("scope", "demo")));
}
/**
* Rename a tag key for every metric beginning with a given prefix.
* <p>
* This will rename the metric name http.server.requests tag value called `method` to `httpmethod`
* <p>
* OLD: http.server.requests ['method':'GET", ...]
* NEW: http.server.requests ['httpmethod':'GET", ...]
*
* @return meter filter
*/
@Bean
@Singleton
MeterFilter renameFilter() {
return MeterFilter.renameTag("http.server.requests", "method", "httpmethod");
}
}Meter Binder
Meter Binders get applied to Meter Registry to mix in metrics producers. Micrometer.io defines several of these for cross-cutting metrics related to JVM metrics, caches, classloaders, etc. These all extend a simple interface MeterBinder, but these are not auto wired as beans and manual wiring is required given how micrometer is currently implemented.
Provided Binders
The following metrics currently have binders and are enabled by default. The settings listed below can disable the specific metric binders if you do not with to collect or report the specific metrics.
Jvm Metrics
The JVM metrics bindings will provide several jvm metrics.
Control Property: micronaut.metrics.binders.jvm.enabled
Name |
jvm.buffer.count |
jvm.buffer.memory.used |
jvm.buffer.total.capacity |
jvm.classes.loaded |
jvm.classes.unloaded |
jvm.gc.live.data.size |
jvm.gc.max.data.size |
jvm.gc.memory.allocated |
jvm.gc.memory.promoted |
jvm.memory.committed |
jvm.memory.max |
jvm.memory.used |
jvm.threads.daemon |
jvm.threads.live |
jvm.threads.peak |
Web Metrics
There is a default web filter provided for web metrics. All routes, status codes, methods and exceptions will be timed and counted.
Control Property: micronaut.metrics.binders.web.enabled
Filter Path
If enabled, be default the path /** will be intercepted. If you wish to change which paths are run through the filter set the following property.
Control Property: micronaut.metrics.http.path
Name |
http.server.requests |
http.client.requests |
System Metrics
There are multiple metrics that can be separately toggled.
Uptime Metrics
The uptime metrics bindings will provide system uptime metrics.
Control Property: micronaut.metrics.binders.uptime.enabled
Name |
process.uptime |
process.start.time |
Processor Metrics
The processor metrics bindings will provide system processor metrics.
Control Property: micronaut.metrics.binders.processor.enabled
Name |
system.load.average.1m |
system.cpu.usage |
system.cpu.count |
process.cpu.usage |
File Descriptor Metrics
The file descriptor metrics bindings will provide system file descriptor metrics.
Control Property: micronaut.metrics.binders.files.enabled
Name |
process.files.open |
process.files.max |
Logback Metrics
The logging metrics bindings will provide logging metrics if using Logback.
Control Property: micronaut.metrics.binders.logback.enabled
Name |
logback.events |
Hibernate Metrics
You can enable metrics for Hibernate by setting the hibernate.generate_statistics property to true in configuration. For example for the default entity manager:
Enabling Hibernate Metrics
jpa:
default:
properties:
hibernate:
generate_statistics: trueMicrometer will automatically expose Hibernate statistics. See the source code for HibernateMetrics for the available metrics.
DataSource Metrics
The data source metrics bindings will provide data source pool metrics.
Control Property: micronaut.metrics.binders.jdbc.enabled
| There is a different set of pool metric names for HikariCP and other pool providers. |
If you are using io.micronaut.configuration:micronaut-jdbc-hikari you will get additional pool metrics as HikariCP has built in support for meter registries.
Name |
hikaricp.connections.idle |
hikaricp.connections.pending |
hikaricp.connections |
hikaricp.connections.active |
hikaricp.connections.creation |
hikaricp.connections.max |
hikaricp.connections.min |
hikaricp.connections.usage |
hikaricp.connections.timeout |
hikaricp.connections.acquire |
If you are using io.micronaut.configuration:micronaut-jdbc-tomcat or io.micronaut.configuration:micronaut-jdbc-dbcp you will get the following metrics
Name |
jdbc.connections.usage |
jdbc.connections.active |
jdbc.connections.max |
jdbc.connections.min |
Adding Custom Metrics
To add metrics to your application you can inject a MeterRegistry bean to your class and use the provided methods to access counters, timers, etc.
See the Micrometer.io docs at https://micrometer.io/docs for more information.
Custom Metrics Example
package io.micronaut.docs;
import io.micrometer.core.instrument.MeterRegistry;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Get;
import io.reactivex.Single;
import javax.validation.constraints.NotBlank;
@Controller("/")
public class IndexController {
private MeterRegistry meterRegistry;
public IndexController(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
}
@Get("/hello/{name}")
public Single hello(@NotBlank String name) {
meterRegistry
.counter("web.access", "controller", "index", "action", "hello")
.increment();
return Single.just("Hello " + name);
}
}Metrics Registries & Reporters
By default there a metrics endpoint wired up and metrics are provided to it for viewing or retrieving via http. If you want to register a specific type of reporter you will need to include a typed registry configuration. The following are the currently supported libraries for reporting metrics.
Statsd Registry
You can include the statsd reporter via io.micronaut.configuration:micronaut-micrometer-registry-statsd:${micronaut.version}
Maven
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-micrometer-registry-statsd</artifactId>
<version>${micronaut.version}</version>
</dependency>You can configure this reporter using micronaut.metrics.export.statsd. The most commonly changed configuration properties are listed below, but see StatdsConfig for more options
Name |
Description |
enabled |
Whether to enable the reporter. Could disable to local dev for example. Default: |
flavor |
The type of metric to use (datadog, etsy or telegraf). Default: |
step |
How frequently to report metrics. Default: |
host |
The host to communicate to statsd on. Default: |
port |
The port to communicate to statsd on. Default: |
Example Statsd Config
micronaut:
metrics:
enabled: true
export:
statsd:
enabled: true
flavor: datadog
step: PT1M
host: localhost
port: 8125Graphite Registry
You can include the graphite reporter via io.micronaut.configuration:micronaut-micrometer-registry-graphite:${micronaut.version}
Maven
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-micrometer-registry-graphite</artifactId>
<version>${micronaut.version}</version>
</dependency>You can configure this reporter using micronaut.metrics.export.graphite. The most commonly changed configuration properties are listed below, but see GraphiteConfig for more options
Name |
Description |
enabled |
Whether to enable the reporter. Could disable to local dev for example. Default: |
step |
How frequently to report metrics. Default: |
host |
The host to communicate with graphite. Default: |
port |
The port to communicate with graphite. Default: |
Example Graphite Config
micronaut:
metrics:
enabled: true
export:
graphite:
enabled: true
step: PT1M
host: localhost
port: 2004Atlas Registry
You can include the atlas reporter via io.micronaut.configuration:micronaut-micrometer-registry-atlas:${micronaut.version}
Maven
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-micrometer-registry-atlas</artifactId>
<version>${micronaut.version}</version>
</dependency>You can configure this reporter using micronaut.metrics.export.atlas. The most commonly changed configuration properties are listed below, but see AtlasConfig for more options
Name |
Description |
enabled |
Whether to enable the reporter. Could disable to local dev for example. Default: |
step |
How frequently to report metrics. Default: |
uri |
The uri for the atlas backend. Default: |
Example Atlas Config
micronaut:
metrics:
enabled: true
export:
atlas:
enabled: true
uri: http://localhost:7101/api/v1/publish
step: PT1MPrometheus Registry
You can include the prometheus reporter via io.micronaut.configuration:micronaut-micrometer-registry-prometheus:${micronaut.version}
Maven
<dependency>
<groupId>io.micronaut.configuration</groupId>
<artifactId>micronaut-micrometer-registry-prometheus</artifactId>
<version>${micronaut.version}</version>
</dependency>You can configure this reporter using micronaut.metrics.export.prometheus. The most commonly changed configuration properties are listed below, but see PrometheusConfig for more options
Name |
Description |
enabled |
Whether to enable the reporter. Could disable to local dev for example. Default: |
step |
How frequently to report metrics. Default: |
descriptions |
Boolean if meter descriptions should be sent to Prometheus. Turn this off to minimize the amount of data sent on each scrape. Default: |
Example Prometheus Config
micronaut:
metrics:
enabled: true
export:
prometheus:
enabled: true
step: PT1M
descriptions: true14.2.5 The Refresh Endpoint
The refresh endpoint will refresh the application state, causing all Refreshable beans in the context to be destroyed and reinstantiated upon further requests. This is accomplished by publishing a RefreshEvent in the Application Context.
To execute the refresh endpoint, send a POST request to /refresh.
$ curl -X POST http://localhost:8080/refreshWhen executed without a body, the endpoint will first refresh the Environment and perform a diff to detect any changes, and will then only perform the refresh if changes are detected. To skip this check and refresh all @Refreshable beans regardless of environment changes (e.g., to force refresh of cached responses from third-party services), you can supply a force parameter in the POST request body.
$ curl -X POST http://localhost:8080/refresh -H 'Content-Type: application/json' -d '{"force": true}'Configuration
To configure the refresh endpoint, supply configuration through endpoints.refresh.
Beans Endpoint Configuration Example
endpoints:
refresh:
enabled: Boolean
sensitive: Boolean
id: String14.2.6 The Routes Endpoint
The routes endpoint returns information about URIs available to be called for your application. By default the data returned includes the URI, allowed method, content types produced, and information about the method that would be executed.
To execute the routes endpoint, send a GET request to /routes.
Configuration
To configure the routes endpoint, supply configuration through endpoints.routes.
Routes Endpoint Configuration Example
endpoints:
routes:
enabled: Boolean
sensitive: Boolean
id: StringCustomization
The routes endpoint is composed of a route data collector and a route data implementation. The route data collector (RouteDataCollector) is responsible for returning a publisher that will return the data used in the response. The route data (RouteData) is responsible for returning data about an individual route.
To override the default behavior for either of the helper classes, either extend the default implementations (RxJavaRouteDataCollector, DefaultRouteData), or implement the relevant interface directly. To ensure your implementation is used instead of the default, add the @Replaces annotation to your class with the value being the default implementation.
14.2.7 The Loggers Endpoint
The loggers endpoint returns information about the available loggers in the application and permits configuring the their log level.
To get a collection of all loggers by name with their configured and effective log levels, send a GET request to /loggers. This will also provide a list of the available log levels.
$ curl http://localhost:8080/loggers
{
"levels": [
"ALL", "TRACE", "DEBUG", "INFO", "WARN", "ERROR", "OFF", "NOT_SPECIFIED"
],
"loggers": {
"ROOT": {
"configuredLevel": "INFO",
"effectiveLevel": "INFO"
},
"io": {
"configuredLevel": "NOT_SPECIFIED",
"effectiveLevel": "INFO"
},
"io.micronaut": {
"configuredLevel": "NOT_SPECIFIED",
"effectiveLevel": "INFO"
},
// etc...
}
}To get the log levels of a particular logger, include the logger name in your GET request. For example, to access the log levels of the logger 'io.micronaut.http':
$ curl http://localhost:8080/loggers/io.micronaut.http
{
"configuredLevel": "NOT_SPECIFIED",
"effectiveLevel": "INFO"
}If the named logger does not exist, it will be created with an unspecified (i.e. NOT_SPECIFIED)
configured log level. (It’s effective log level will usually be that of the root logger.)
To update the log level of a single logger, send a POST request to the named logger URL and include a body providing the log level to configure.
$ curl -i -X POST
-H "Content-Type: application/json" \
-d '{ "configuredLevel": "ERROR" }' \
http://localhost:8080/loggers/ROOT
HTTP/1.1 200 OK
$ curl http://localhost:8080/loggers/ROOT
{
"configuredLevel": "ERROR",
"effectiveLevel": "ERROR"
}Configuration
To configure the loggers endpoint, supply configuration through endpoints.loggers.
Loggers Endpoint Configuration Example
endpoints:
loggers:
enabled: Boolean
sensitive: Boolean
id: StringCustomization
The loggers endpoint is composed of two customizable parts: a loggers manager and a logging system.
The loggers manager (LoggersManager) is responsible for returning a Publisher that will return data collected and transformed for the response, and it is also responsible for updating a logger with a new log level.
To override the default behavior for the loggers manager, either extend the default implementation (DefaultLoggersManager) or implement the LoggersManager interface directly. To ensure your implementation is used instead of the default, add the @Replaces annotation to your class with the value being the default implementation.
The logging system (LoggingSystem) is responsible for processing requests from the loggers manager against a particular logging library (e.g. logback, log4j, etc.)
The current default implementation for the logging system is LogbackLoggingSystem, which works with the logback logging framework. Additional logging systems will be implemented in future revisions of Micronaut. For custom logging system behavior, implement the LoggingSystem interface directly. To ensure your implementation is used instead of the default, add the @Replaces annotation to your class with the value being the default implementation.
@Singleton
@Replaces(LogbackLoggingSystem.class)
public class CustomLoggingSystem implements LoggingSystem {
// ...
}14.2.8 The Server Stop Endpoint
The stop endpoint shuts down the application server.
To execute the stop endpoint, send a POST request to /stop.
Configuration
To configure the stop endpoint, supply configuration through endpoints.stop.
Stop Endpoint Configuration Example
endpoints:
stop:
enabled: Boolean
sensitive: Boolean
id: String| By default, the stop endpoint is disabled and needs to be explicitly enabled to be used. |
15 Security
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply either the $ mn create-app my-app --features security-jwt |
To use the Micronaut’s security capabilities you must have the security dependency on your classpath. For example in build.gradle:
build.gradle
annotationProcessor "io.micronaut:micronaut-security"
compile "io.micronaut:micronaut-security"Enable security capabilities with:
| Property | Type | Description |
|---|---|---|
|
boolean |
If Security is enabled. Default value false |
|
java.util.List |
Map that defines the interception patterns. |
|
java.util.List |
Allowed IP patterns. Default value (["0.0.0.0"]) |
Once you enable security, Micronaut returns HTTP Status Unauthorized (401) for any endpoint invocation.

15.1 Authentication Providers
To authenticate users you must provide implementations of AuthenticationProvider.
The following code snippet illustrates a naive implementation:
@Singleton
public class AuthenticationProviderUserPassword implements AuthenticationProvider {
@Override
public Publisher<AuthenticationResponse> authenticate(AuthenticationRequest authenticationRequest) {
if (authenticationRequest.getIdentity().equals("user") && authenticationRequest.getSecret().equals("password")) {
return Flowable.just(new UserDetails("user", new ArrayList<>()));
}
return Flowable.just(new AuthenticationFailed());
}
}The built-in Login Controller uses every available authentication provider. Authentication strategies, such as basic auth, where the credentials are present in the request use the available authentication providers too.
Micronaut ships with DelegatingAuthenticationProvider which can be typically used in environments such as the one described in the following diagram.

DelegatingAuthenticationProvider is not enabled unless you provide implementations for UserFetcher,
PasswordEncoder and AuthoritiesFetcher
| Read the LDAP and Database authentication providers to learn more. |
15.2 Security Rules
The decision to allow access to a particular endpoint to anonymous or authenticated users is determined by a collection of Security Rules. Micronaut ships with several built-in security rules. If they don’t fulfil your needs, you can implement your own SecurityRule.
15.2.1 IP Pattern Rule
When you turn on security, traffic coming from any ip address is allowed by default.
You can however reject traffic not coming from a white list of IP Patterns as illustrated below:
micronaut:
security:
enabled: true
ipPatterns:
- 127.0.0.1
- 192.168.1.*In the previous code, the IpPatternsRule rejects traffic not coming
either 127.0.0.1 or 192.168.1.* range.
15.2.2 Secured Annotation
As illustrated below, you can use Secured annotation to configure access at Controller or Controller’s Action level.
@Controller("/example")
@Secured(SecurityRule.IS_AUTHENTICATED) (1)
public class ExampleController {
@Produces(MediaType.TEXT_PLAIN)
@Get("/admin")
@Secured({"ROLE_ADMIN", "ROLE_X"}) (2)
public String withroles() {
return "You have ROLE_ADMIN or ROLE_X roles";
}
@Produces(MediaType.TEXT_PLAIN)
@Get("/anonymous")
@Secured(SecurityRule.IS_ANONYMOUS) (3)
public String anonymous() {
return "You are anonymous";
}
@Produces(MediaType.TEXT_PLAIN)
@Get("/authenticated") (1)
public String authenticated(Authentication authentication) {
return authentication.getName() + " is authenticated";
}
}| 1 | Authenticated users are able to access authenticated Controller’s action. |
| 2 | Users granted role ROLE_ADMIN or ROLE_X roles can access withroles Controller’s action. |
| 3 | Anonymous users (authenticated and not authenticated users) can access anonymous Controller’s action. |
Alternatively, you could use JSR_250 annotations (javax.annotation.security.PermitAll, javax.annotation.security.RolesAllowed, javax.annotation.security.DenyAll):
@Controller("/example")
public class ExampleController {
@Produces(MediaType.TEXT_PLAIN)
@Get("/admin")
@RolesAllowed({"ROLE_ADMIN", "ROLE_X"}) (1)
public String withroles() {
return "You have ROLE_ADMIN or ROLE_X roles";
}
@Produces(MediaType.TEXT_PLAIN)
@Get("/anonymous")
@PermitAll (2)
public String anonymous() {
return "You are anonymous";
}
}| 1 | Users granted role ROLE_ADMIN or ROLE_X roles can access withroles Controller’s action. |
| 2 | Anonymous users (authenticated and not authenticated users) can access anonymous Controller’s action. |
15.2.3 Intercept URL Map
Moreover, you can configure endpoint authentication and authorization access with an Intercept URL Map:
micronaut:
security:
enabled: true
interceptUrlMap:
-
pattern: /images/*
httpMethod: GET
access:
- isAnonymous() (1)
-
pattern: /books
access:
- isAuthenticated() (2)
-
pattern: /books/grails
httpMethod: GET
access:
- ROLE_GRAILS (3)
- ROLE_GROOVY| 1 | Enable access to authenticated and not authenticated users |
| 2 | Enable access for everyone authenticated |
| 3 | Enable access for users who are granted any of the specified roles. |
As you see in the previous code listing, any endpoint is identified by a combination of pattern and an optional HTTP Method
15.2.4 Built-In Endpoints Security
When you turn on security, Built-in endpoints are secured depending on their sensitive value.
endpoints:
beans:
enabled: true
sensitive: true (1)
info:
enabled: true
sensitive: false (2)| 1 | /beans endpoint is secured |
| 2 | /info endpoint is open for unauthenticated access. |
15.3 Authentication Strategies
15.3.1 Basic Auth
Out-of-the-box, Micronaut supports RFC7617 which defines the "Basic" Hypertext Transfer Protocol (HTTP) authentication scheme, which transmits credentials as user-id/password pairs, encoded using Base64.
Once you enable Micronaut security, Basic Auth is enabled by default.
micronaut:
security:
enabled: trueThe following sequence illustrates the authentication flow:

Below is a sample of a cURL command using basic auth:
cURL command using Basic Auth
curl "http://localhost:8080/info" \
-u 'user:password'After credentials are read from the HTTP Header, they are feed into an Authenticator which attempts to validate them.
The following configuration properties are available to customize basic authentication behaviour:
| Property | Type | Description |
|---|---|---|
|
boolean |
Enables BasicAuthTokenReader. Default value true. |
|
java.lang.String |
Http Header name. Default value "Authorization". |
|
java.lang.String |
Http Header value prefix. Default value "Basic". |
| Read the Basic Authentication Micronaut Guide to learn more. |
15.3.2 Session Authentication
Micronaut supports Session based authentication.
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply either the $ mn create-app my-app --features security-session |
To use the Micronaut’s session based authentication capabilities you must have the security-session dependency on your classpath. For example in build.gradle:
build.gradle
annotationProcessor "io.micronaut:micronaut-security"
compile "io.micronaut:micronaut-security-session"The following sequence illustrates the authentication flow:

The following configuration properties are available to customize session based authentication behaviour:
| Property | Type | Description |
|---|---|---|
|
java.lang.String |
Sets the login success target URL. Default value ("/"). |
|
java.lang.String |
Sets the login failure target URL. Default value ("/"). |
|
java.lang.String |
Sets the logout target URL. Default value ("/"). |
|
java.lang.String |
Sets the unauthorized target URL. |
|
java.lang.String |
Sets the forbidden target URL. |
|
boolean |
Sets whether the session config is enabled. Default value (false). |
Example of Session-Based Authentication configuration
micronaut:
security:
enabled: true
endpoints:
login:
enabled: true
logout:
enabled: true
session:
enabled: true
loginFailureTargetUrl: /login/authFailed| Read the Session-Based Authentication Micronaut Guide to learn more. |
15.3.3 JSON Web Token
The following configuration properties are available to customize token based authentication:
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets whether the configuration is enabled. Default value true. |
|
java.lang.String |
Name of the roles property. Default value "roles". |
Micronaut ships with security capabilities based on Json Web Token (JWT). JWT is an IETF standard which defines a secure way to encapsulate arbitrary data that can be sent over unsecure URL’s.
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply either the $ mn create-app my-app --features security-jwt |
To use the Micronaut’s JWT based authentication capabilities you must have the security-jwt dependency on your classpath. For example in build.gradle:
build.gradle
annotationProcessor "io.micronaut:micronaut-security"
compile "io.micronaut:micronaut-security-jwt"The following configuration properties are available to customize JWT based authentication behaviour:
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets whether JWT security is enabled. Default value (false). |
What does a JWT look like?

Header
A base64-encoded JSON like:
JWT header
{
"alg": "HS256",
"typ": "JWT"
}Claims
A base64-encoded JSON like:
JWT claims
{
"exp": 1422990129,
"sub": "jimi",
"roles": [
"ROLE_ADMIN",
"ROLE_USER"
],
"iat": 1422986529
}Signature
Depends on the algorithm specified on the header, it can be a digital signature of the base64-encoded header and claims, or an encryption of them.
15.3.3.1 Reading JWT Token
15.3.3.1.1 Bearer Token Reader
Micronaut supports RFC 6750 Bearer Token specification out-of-the-box.
It is enabled by default but requires JWT Authentication to be enabled.
The following sequence illustrates the authentication flow:

The following configuration properties are available to customize Bearer Token read:
| Property | Type | Description |
|---|---|---|
|
boolean |
Set whether to enable basic auth. Default value true |
|
java.lang.String |
Sets the header name to use. Default value "Authorization". |
|
java.lang.String |
Sets the prefix to use for the auth token. Default value "Bearer" |
Sending tokens in the request
The following code snippet illustrates how to send a JWT token in the Authorization request header:
Accessing a protected resource using Authorization request header
GET /protectedResource HTTP/1.1
Host: micronaut.example
Authorization: Bearer eyJhbGciOiJIUzI1NiJ9.eyJleHAiOjE0MjI5OTU5MjIsInN1YiI6ImppbWkiLCJyb2xlcyI6WyJST0xFX0FETUlOIiwiUk9MRV9VU0VSIl0sImlhdCI6MTQyMjk5MjMyMn0.rA7A2Gwt14LaYMpxNRtrCdO24RGrfHtZXY9fIjV8x8o| Read the Micronaut JWT Authentication to learn more. |
15.3.3.1.2 Cookie Token Reader
You can send/read a JWT token from a Cookie too.
The following sequence illustrates the authentication flow:

Reading tokens from Cookies is disabled by default. Note that using JWT tokens from cookies requires JWT Authentication to be enabled.
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets whether JWT cookie based security is enabled. Default value (false). |
|
java.lang.String |
Sets the logout target URL. Default value ("/"). |
|
java.lang.String |
Sets the cookie name to use. Default value ("JWT"). |
|
java.lang.String |
Sets the login success target URL. Default value ("/"). |
|
java.lang.String |
Sets the login failure target URL. Default value ("/"). |
| Read the Micronaut JWT Authentication with Cookies to learn more. |
15.3.3.2 JWT Token Generation
Micronaut relies on Nimbus JOSE + JWT library to provide JWT token signature and encryption.
The following configuration options are available:
| Property | Type | Description |
|---|---|---|
|
java.lang.Integer |
Refresh token expiration. By default refresh tokens, do not expire. |
|
java.lang.Integer |
Access token expiration. Default value (3600). |
15.3.3.2.1 JWT Signature
Micronaut security capabilities use signed JWT’s as specified by the JSON Web Signature specification.
To enable a JWT signature in token generation, you need to have in your app a bean of type RSASignatureGeneratorConfiguration,
ECSignatureGeneratorConfiguration,
SecretSignatureConfiguration qualified with name generator.
To verify signed JWT tokens, you need to have in your app a bean of type RSASignatureConfiguration, RSASignatureGeneratorConfiguration, ECSignatureGeneratorConfiguration, ECSignatureConfiguration, or SecretSignatureConfiguration.
You can setup a SecretSignatureConfiguration named generator easily via configuration properties:
micronaut:
security:
enabled: true
token:
jwt:
enabled: true
signatures:
secret:
generator:
secret: pleaseChangeThisSecretForANewOne (1)
jws-algorithm: HS256 (2)| 1 | Change this for your own secret and keep it safe. |
| 2 | Json Web Token Signature name. In this example, HMAC using SHA-256 hash algorithm. |
You can supply the secret with Base64 encoding.
micronaut:
security:
enabled: true
token:
jwt:
enabled: true
signatures:
secret:
generator:
secret: 'cGxlYXNlQ2hhbmdlVGhpc1NlY3JldEZvckFOZXdPbmU=' (1)
base64: true (2)
jws-algorithm: HS256| 1 | Secret Base64 encoded |
| 2 | Signal that the secret is Base64 encoded |
15.3.3.2.2 Encrypted JWTs
Signed claims prevents an attacker to tamper its contents to introduce malicious data or try a privilege escalation by adding more roles. However, the claims can be decoded just by using Base 64.
If the claims contains sensitive information, you can use a JSON Web Encryption algorithm to prevent them to be decoded.
To enable a JWT encryption in token generation, you need to have in your app a bean of type RSAEncryptionConfiguration,
ECEncryptionConfiguration,
SecretEncryptionConfiguration qualified with name generator.
Example of JWT Signed with Secret and Encrypted with RSA
Setup a SecretSignatureConfiguration through configuration properties
micronaut:
security:
enabled: true
token:
jwt:
enabled: true
signatures:
secret:
generator:
secret: pleaseChangeThisSecretForANewOne (1)
jws-algorithm: HS256 (2)
pem:
path: /home/user/rsa-2048bit-key-pair.pem (2)| 1 | Name the Signature configuration generator to make it participate in JWT token generation. |
| 2 | Location of PEM file |
Generate a 2048-bit RSA private + public key pair:
openssl genrsa -out rsa-2048bit-key-pair.pem 2048@Named("generator") (1)
@Singleton
class RSAOAEPEncryptionConfiguration implements RSAEncryptionConfiguration {
private RSAPrivateKey rsaPrivateKey
private RSAPublicKey rsaPublicKey
JWEAlgorithm jweAlgorithm = JWEAlgorithm.RSA_OAEP_256
EncryptionMethod encryptionMethod = EncryptionMethod.A128GCM
RSAOAEPEncryptionConfiguration(@Value('${pem.path}') String pemPath) {
Optional<KeyPair> keyPair = KeyPairProvider.keyPair(pemPath)
if (keyPair.isPresent()) {
this.rsaPublicKey = (RSAPublicKey) keyPair.get().getPublic()
this.rsaPrivateKey = (RSAPrivateKey) keyPair.get().getPrivate()
}
}
@Override
RSAPublicKey getPublicKey() {
return rsaPublicKey
}
@Override
RSAPrivateKey getPrivateKey() {
return rsaPrivateKey
}
@Override
JWEAlgorithm getJweAlgorithm() {
return jweAlgorithm
}
@Override
EncryptionMethod getEncryptionMethod() {
return encryptionMethod
}
}| 1 | Name Bean generator to designate this bean as participant in the JWT Token Generation. |
To parse the PEM key, use a collaborator as described in OpenSSL key generation.
@Slf4j
class KeyPairProvider {
/**
*
* @param pemPath Full path to PEM file.
* @return returns KeyPair if successfully for PEM files.
*/
static Optional<KeyPair> keyPair(String pemPath) {
// Load BouncyCastle as JCA provider
Security.addProvider(new BouncyCastleProvider())
// Parse the EC key pair
PEMParser pemParser
try {
pemParser = new PEMParser(new InputStreamReader(new FileInputStream(pemPath)))
PEMKeyPair pemKeyPair = (PEMKeyPair) pemParser.readObject()
// Convert to Java (JCA) format
JcaPEMKeyConverter converter = new JcaPEMKeyConverter()
KeyPair keyPair = converter.getKeyPair(pemKeyPair)
pemParser.close()
return Optional.of(keyPair)
} catch (FileNotFoundException e) {
log.warn("file not found: {}", pemPath)
} catch (PEMException e) {
log.warn("PEMException {}", e.getMessage())
} catch (IOException e) {
log.warn("IOException {}", e.getMessage())
}
return Optional.empty()
}
}15.3.3.3 JWT Token Validation
Micronaut’s JWT validation support multiple Signature and Encryption configurations.
Any beans of type RSASignatureConfiguration, ECSignatureConfiguration, SecretSignatureConfiguration participate as signature configurations in the JWT validation.
Any beans of type RSAEncryptionConfiguration, ECEncryptionConfiguration, SecretEncryptionConfiguration participate as encryption configurations in the JWT validation.
15.3.3.4 Claims Generation
If the built-in JWTClaimsSetGenerator, does not fulfil your needs you can provide your own replacement of ClaimsGenerator.
For example, if you want to add the email address of the user to the JWT Claims you could create a class which extends UserDetails:
public class EmailUserDetails extends UserDetails {
private String email;
public EmailUserDetails(String username, Collection<String> roles) {
super(username, roles);
}
public EmailUserDetails(String username, Collection<String> roles, String email) {
super(username, roles);
this.email = email;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}Configure your AuthenticationProvider to respond such a class:
@Singleton
public class CustomAuthenticationProvider implements AuthenticationProvider {
@Override
public Publisher<AuthenticationResponse> authenticate(AuthenticationRequest authenticationRequest) {
return Flowable.just(new EmailUserDetails("sherlock", Collections.emptyList(), "sherlock@micronaut.example"));
}
}And then replace JWTClaimsSetGenerator with a bean that overrides the method populateWithUserDetails:
@Singleton
@Replaces(bean = JWTClaimsSetGenerator.class)
public class CustomJWTClaimsSetGenerator extends JWTClaimsSetGenerator {
public CustomJWTClaimsSetGenerator(TokenConfiguration tokenConfiguration,
@Nullable JwtIdGenerator jwtIdGenerator,
@Nullable ClaimsAudienceProvider claimsAudienceProvider,
@Nullable ApplicationConfiguration applicationConfiguration) {
super(tokenConfiguration, jwtIdGenerator, claimsAudienceProvider, applicationConfiguration);
}
@Override
protected void populateWithUserDetails(JWTClaimsSet.Builder builder, UserDetails userDetails) {
super.populateWithUserDetails(builder, userDetails);
if (userDetails instanceof EmailUserDetails) {
builder.claim("email", ((EmailUserDetails)userDetails).getEmail());
}
}
}15.3.3.5 Token Render
When you use JWT authentication and the built-in LoginController, the JWT tokens are returned to the client as part of an OAuth 2.0 RFC6749 access token response.
An example of such a response is:
HTTP/1.1 200 OK
Content-Type: application/json;charset=UTF-8
Cache-Control: no-store
Pragma: no-cache
{
"access_token":"eyJhbGciOiJIUzI1NiJ9...",
"token_type":"Bearer",
"expires_in":3600,
"refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA...",
"username": "euler",
"roles": [
"ROLE_USER"
],
}If you wish to customize the previous JSON payload, you may want to provide a bean replacement for BearerTokenRenderer. If that is not enough, check the AccessRefreshTokenLoginHandler to accommodate it to your needs.
15.3.4 LDAP Authentication
Micronaut supports authentication with LDAP out of the box. To get started, add the security-ldap dependency to your application.
build.gradle
compile "io.micronaut.configuration:micronaut-security-ldap"| Read the LDAP and Database authentication providers to see an example. |
15.3.4.1 Configuration
The LDAP authentication in Micronaut supports configuration of one or more LDAP servers to authenticate with. Each server has it’s own settings and can be enabled or disabled.
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets whether this configuration is enabled. Default true. |
| Property | Type | Description |
|---|---|---|
|
java.lang.String |
Sets the server URL. |
|
java.lang.String |
Sets the manager DN. |
|
java.lang.String |
Sets the manager password. |
|
java.lang.String |
Sets the context factory class. Default "com.sun.jndi.ldap.LdapCtxFactory" |
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets if the subtree should be searched. Default true |
|
java.lang.String |
Sets the base DN to search. |
|
java.lang.String |
Sets the search filter. Default "(uid={0})" |
|
java.lang.String[] |
Sets the attributes to return. Default all |
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets if group search is enabled. Default false |
|
boolean |
Sets if the subtree should be searched. Default true |
|
java.lang.String |
Sets the base DN to search from. |
|
java.lang.String |
Sets the group search filter. Default "uniquemember={0}" |
|
java.lang.String |
Sets the group attribute name. Default "cn" |
15.3.4.2 Extending Default Behavior
This section will outline some common requirements that will require custom code to implement and describe what to do in those cases.
Authentication Data
The authentication object returned from a successful authentication request is by default an instance of UserDetails, which only contains the username and any roles associated with the user. To store additional data in the authentication, extend UserDetails with your own implementation that has fields for the additional data you wish to store.
To use this new implementation, you must override the DefaultContextAuthenticationMapper and provide your own implementation.
MyContextAuthenticationMapper.java
@Singleton
@Replaces(DefaultContextAuthenticationMapper.class) (1)
public class MyContextAuthenticationMapper implements ContextAuthenticationMapper {
@Override
public AuthenticationResponse map(ConvertibleValues<Object> attributes, String username, Set<String> groups) {
// return an extended UserDetails or an AuthenticationFailed object
}
}| 1 | The usage of @Replaces will allow your bean to replace the default implementation in the context |
Groups
By default the groups found in LDAP, if enabled, will be returned as is without any processing. No additional groups from any other sources will be added to the list. It is a common requirement to retrieve additional groups from other sources, or to normalize the names of the groups in a specific format.
To extend this behavior, it is necessary to create your own implementation of LdapGroupProcessor. Likely it will be desired to extend the default implementation because it has the logic for querying the groups from LDAP and executes the other methods to process the groups and query for additional groups.
MyLdapGroupProcessor.java
@Singleton
@Replaces(DefaultLdapGroupProcessor.class) (1)
public class MyLdapGroupProcessor extends DefaultLdapGroupProcessor {
Set<String> getAdditionalGroups(LdapSearchResult result) { (2)
//Use the result to query another source for additional groups (database, etc)
}
Optional<String> processGroup(String group) { (3)
//convert "Admin" to "ROLE_ADMIN" for example
//return an empty optional to exclude the group
}
}| 1 | The usage of @Replaces will allow your bean to replace the default implementation in the context |
| 2 | The getAdditionalGroups method allows you to add groups from other sources |
| 3 | The processGroup method allows you to transform the name of the group, or exclude it |
Search Logic
To customize how LDAP searches are done, replace the default implementation with your own. See LdapSearchService.
MyLdapSearchService.java
@Singleton
@Replaces(DefaultLdapSearchService.class)
public class MyLdapSearchService implements LdapSearchService {
}Context Building
To customize how the LDAP context is built, replace the default implementation with your own. See ContextBuilder.
MyContextBuilder.java
@Singleton
@Replaces(DefaultContextBuilder.class)
public class MyContextBuilder implements ContextBuilder {
}15.4 Token Propagation
Imagine you have a Gateway microservice which consumes three other microservices:

If the incoming request localhost:8080/api/books contains a valid JWT token, you may want to propagate
that token to other requests in your network.
You can configure token propagation to achieve that.
micronaut:
application:
name: gateway
security:
enabled: true
token:
jwt:
enabled: true
signatures:
secret:
generator:
secret: "pleaseChangeThisSecretForANewOne"
jws-algorithm: HS256
writer:
header:
enabled: true
headerName: "Authorization"
prefix: "Bearer "
propagation:
enabled: true
service-id-regex: "http://localhost:(8083|8081|8082)"The previous configuration, configures a HttpHeaderTokenWriter and a and a propagation filter, TokenPropagationHttpClientFilter, which will propagate the security token seamlessly.
If you use Service Discovery features, you can use the service id in your service id regular expression:
micronaut.security.token.propagation.service-id-regex="catalogue|recommendations|inventory"| Read the Token Propagation tutorial to learn more. |
15.5 Built-In Security Controllers
15.5.1 Login Controller
You can enable LoginController with configuration property:
| Property | Type | Description |
|---|---|---|
|
boolean |
Enables LoginController. Default value false |
|
java.lang.String |
Path to the LoginController. Default value "/login" |
The response of the Login Endpoint is handled by a bean instance of LoginHandler.
Login Endpoint invocation example
Login Endpoint invocation example
curl -X "POST" "http://localhost:8080/login" \
-H 'Content-Type: application/json; charset=utf-8' \
-d $'{
"username": "euler",
"password": "password"
}'15.5.2 Logout Controller
You can enable LogoutController with configuration property:
| Property | Type | Description |
|---|---|---|
|
boolean |
Enables LogoutController. Default value false. |
|
java.lang.String |
Path to the LogoutController. Default value "/logout". |
Each bean of type LogoutHandler gets invoked.
If you are using JWT authentication, you may not need to invoke the /logout endpoint. Since logging out normally means simply deleting access, refresh JWT tokens at the client side.
|
Logout Endpoint invocation example
Login Endpoint invocation example
curl -X "POST" "http://localhost:8080/logout"15.5.3 Refresh Controller
| This controller can only be enabled if you are using JWT authentication. |
By default, issued access tokens expire after a period of time, and they are paired with refresh tokens. To ease the refresh, you can enable OauthController, with configuration property:
| Property | Type | Description |
|---|---|---|
|
boolean |
Sets whether the OauthController is enabled. Default value (false). |
|
java.lang.String |
Sets the path to map the OauthController to. Default value ("/oauth/access_token"). |
The controller exposes an endpoint as defined by section 6 of the OAuth 2.0 spec - Refreshing an Access Token.
By default, issued Refresh tokens never expire, and can be used to obtain a new access token by sending a POST request to the /oauth/access_token endpoint:
Sample HTTP request to obtain an access token
POST /myApp/oauth/access_token HTTP/1.1
Host: micronaut.example
Content-Type: application/x-www-form-urlencoded
grant_type=refresh_token&refresh_token=eyJhbGciOiJSU0EtT0FFUCIsImVuYyI6IkEyNTZHQ00ifQ....As you can see, is a form request with 2 parameters:
grant_type: must be refresh_token always.
refresh_token: the refresh token obtained previously.
| By default refresh tokens never expire, they must be securely stored in your client application. See section 10.4 of the OAuth 2.0 spec for more information. |
15.6 Retrieve the authenticated user
Often you may want to retrieve the authenticated user.
You can bind java.security.Principal as a method’s parameter in a controller.
import io.micronaut.context.annotation.Requires;
import io.micronaut.core.util.CollectionUtils;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Get;
import io.micronaut.security.annotation.Secured;
import javax.annotation.Nullable;
import java.security.Principal;
@Controller("/user")
public class UserController {
@Secured("isAnonymous()")
@Get("/myinfo")
public Map myinfo(@Nullable Principal principal) {
if (principal == null) {
return Collections.singletonMap("isLoggedIn", false);
}
return CollectionUtils.mapOf("isLoggedIn", true, "username", principal.getName());
}
}If you need a greater level of detail, you can bind Authentication as a method’s parameter in a controller.
import io.micronaut.context.annotation.Requires;
import io.micronaut.core.util.CollectionUtils;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Get;
import io.micronaut.security.annotation.Secured;
import io.micronaut.security.authentication.Authentication;
import javax.annotation.Nullable
@Controller("/user")
public class UserController {
@Secured("isAnonymous()")
@Get("/myinfo")
public Map myinfo(@Nullable Authentication authentication) {
if (authentication == null) {
return Collections.singletonMap("isLoggedIn", false);
}
return CollectionUtils.mapOf("isLoggedIn", true,
"username", authentication.getName(),
"roles", authentication.getAttributes().get("roles")
);
}
}15.7 Security Events
Micronaut security classes generate several ApplicationEvents which you can subscribe to.
Event Name |
Description |
Triggered when an unsuccessful login takes place. |
|
Triggered when a successful login takes place. |
|
Triggered when the user logs out. |
|
Triggered when a token is validated. |
|
Triggered when a JWT access token is generated. |
|
Triggered when a JWT refresh token is generated. |
To learn how to listen for events, see the Context Events section of the documentation.
16 Multi-Tenancy
Multi-Tenancy, as it relates to software development, is when a single instance of an application is used to service multiple clients (tenants) in a way that each tenants' data is isolated from the other.
To use the Micronaut’s multitenancy capabilities you must have the multitenancy dependency on your classpath. For example in build.gradle:
build.gradle
compile "io.micronaut:micronaut-multitenancy"A common requirement for supporting Multi-tenancy is the ability to resolve the current tenant. Micronaut ships with the following built-in TenantResolvers:
name |
description |
Resolves the current tenant from an HTTP cookie. See CookieTenantResolver Configuration Properties. |
|
Resolves against a fixed tenant id. See FixTenantResolver Configuration Properties. |
|
Resolves the current tenant from the request HTTP Header. See FixTenantResolver Configuration Properties. |
|
Resolves the current tenant from the authenticated username. See PrincipalTenantResolver Configuration Properties. |
|
Resolves the current tenant from the HTTP session. See SessionTenantResolver Configuration Properties. |
|
Resolves the tenant id from the subdomain. See SubdomainTenantResolver Configuration Properties. |
|
Resolves the tenant id from a system property. See SystemPropertyTenantResolver Configuration Properties. |
Micronaut supports tenant propagation. As an example, take the following scenario:

You want incoming requests to the gateway microservice to resolve the tenant id via subdomain. However, you want
your requests to other internal microservices to include the tenant Id as an HTTP Header.
Your configuration in the gateway microservice will look like:
micronaut:
multitenancy:
propagation:
enabled: true
service-id-regex: 'catalogue'
tenantresolver:
subdomain:
enabled: true
tenantwriter:
httpheader:
enabled: trueIn the catalogue microservice the configuration will look like:
micronaut:
multitenancy:
tenantresolver:
httpheader:
enabled: trueTo propagate the tenant you will need to write the resolved tenant ID to the outgoing requests.
Currently, Micronaut ships with two built-in implementations for TenantWriter:
name |
description |
Writes the current tenant to a Cookie in your outgoing requests. See CookieTenantWriter Configuration Properties. |
|
Writes the current tenant to a HTTP Header. See HttpHeaderTenantWriter Configuration Properties. |
16.1 Multi-Tenancy GORM
GORM supports Multi-tenancy and integrates with Micronaut.
To use Micronaut and GORM multitenancy capabilities you must have the multitenancy-gorm dependency on your classpath. For example in build.gradle:
build.gradle
compile "io.micronaut.configuration:micronaut-multitenancy-gorm"GORM is a powerful Groovy-based data access toolkit for the JVM with implementations several data access technologies (Hibernate, Neo4j, MongoDB, GraphQL …).
GORM supports the following different multitenancy modes:
-
DATABASE- A separate database with a separate connection pool is used to store each tenants data. -
SCHEMA- The same database, but different schemas are used to store each tenants data. -
DISCRIMINATOR- The same database is used with a discriminator used to partition and isolate data.
In order to use GORM - Multitenancy you will need to configure the following properties: grails.gorm.multiTenancy.mode and grails.gorm.multiTenancy.tenantResolverClass.
Micronaut support for Multi-tenancy integrates with GORM.
The following table contains all of the TenantResolver implementations that ship with `multitenancy-gorm module and are usable out of the box.
name |
description |
Resolves the current tenant from an HTTP cookie. |
|
Resolves against a fixed tenant id |
|
Resolves the current tenant from the request HTTP Header. |
|
Resolves the current tenant from the authenticated username. |
|
Resolves the current tenant from the HTTP session. |
|
Resolves the tenant id from the subdomain. |
|
Resolves the tenant id from a system property. |
You will need to add something like the following snippet to your app configuration:
grails:
gorm:
multiTenancy:
mode: DISCRIMINATOR
tenantResolverClass: 'io.micronaut.multitenancy.gorm.PrincipalTenantResolver'Please, read GORM Multi-tenancy documentation to learn more.
17 Micronaut CLI
The Micronaut CLI is the recommended way to create new Micronaut projects. The CLI includes commands for generating specific categories of projects, allowing you to choose between build tools, test frameworks, and even pick the language you wish to use in your application. The CLI also provides commands for generating artifacts such as controllers, client interfaces, and serverless functions.
When Micronaut is installed on your computer, you can call the CLI with the mn command.
$ mn create-app my-appA Micronaut CLI project can be identified by the micronaut-cli.yml file, which will be included at the root of the project (if it was generated via the CLI). This file will include the project’s profile, default package, and other variables. The project’s default package is evaluated based on the project name, for example:
$ mn create-app my-demo-appWill result in the following micronaut-cli-yml.
micronaut-cli.yml
profile: service
defaultPackage: my.demo.app
---
testFramework: junit
sourceLanguage: javaYou can supply your own default package when creating the application by prefixing the application name with the package:
$ mn create-app example.my-demo-appWill result in the following micronaut-cli-yml.
micronaut-cli.yml
profile: service
defaultPackage: example
---
testFramework: junit
sourceLanguage: java| Throughout the user guide, references to CLI features/commands have been provided as applicable. |
Definitions
Projects created with the CLI are based on one of several profiles, which consist of a project template (or skeleton), optional features, and profile-specific commands. Commands from a profile typically are specific to the profile application type; for example, the service profile (designed for creation of web service applications) provides the create-controller and create-client commands.
CLI commands typically accept at least one argument, such as the name of the project or controller to generate.
CLI commands can accept optional flags to control their behavior. Some flags accept multiple arguments, which are separated by commas.
Interactive Mode
If you run mn without any arguments, the Micronaut CLI will launch in interactive mode. This is a shell-like mode which allows you to run multiple CLI commands without re-initializing the CLI runtime, and is especially suitable when you are making use of code-generation commands (such as create-controller), creating multiple projects, or simply exploring the features included in the CLI. Tab-completion is enabled in the CLI, enabling you to hit the TAB key to see possible options for a given command or flag.
$ mn
| Starting interactive mode...
| Enter a command name to run. Use TAB for completion:
mn>Help and Info
General usage information can be viewed using the help command.
mn> help create-app
Usage: mn create-app [-hinvVx] [-b=BUILD-TOOL] [-l=LANG] [-p=PROFILE] [-f=FEATURE[,FEATURE...]]...
[NAME]
Creates an application
[NAME] The name of the application to create.
-b, --build=BUILD-TOOL Which build tool to configure. Possible values: gradle, maven.
-f, --features=FEATURE[,FEATURE...]
The features to use
-h, --help Show this help message and exit.
-i, --inplace Create a service using the current directory
-l, --lang=LANG Which language to use. Possible values: java, groovy, kotlin.
...For details about a specific command, supply the command name after the help command.
mn> help create-app
| Command: create-app
| Description:
Creates an application
| Usage:
create-app [NAME]
...A list of available profiles can be viewed using the list-profiles command.
mn> list-profiles
| Available Profiles
--------------------
base The base profile
cli The cli profile
federation The federation profile
function The function profile
function-aws The function profile for AWS Lambda
kafka The Kafka messaging profile
profile A profile for creating new Micronaut profiles
service The service profileTo view details on a specific profile, use the profile-info command, followed by the profile name.
mn> profile-info service
| Profile: service
--------------------
The service profile
| Provided Commands:
--------------------
create-bean Creates a singleton bean
create-client Creates a client interface
create-controller Creates a controller and associated test
create-job Creates a job with scheduled method
help Prints help information for a specific command
| Provided Features:
--------------------
annotation-api Adds Java annotation API
config-consul Adds support for Distributed Configuration with Consul (https://www.consul.io)
discovery-consul Adds support for Service Discovery with Consul (https://www.consul.io)
discovery-eureka Adds support for Service Discovery with Eureka
groovy Creates a Groovy application
...17.1 Creating a Project
Creating a project is the primary usage of the CLI. There are two primary commands for creating new projects: create-app and create-function. Both of these commands will generate a project based upon an associated profile (which can be overridden), and will set the micronaut.application.name configuration property in src/main/resources/application.yml.
In addition, there are specialty commands for creating a "federation" of multiple Micronaut services (create-federation) and for creating new profiles for the CLI (create-profile).
| Command | Description | Options | Example |
|---|---|---|---|
|
Creates a basic Micronaut application, using the |
|
|
|
Creates a command-line Micronaut application, using the |
|
|
|
Creates a Micronaut serverless function, using the |
|
|
|
Creates a federation of Micronaut services with shared profile/features. |
|
|
|
Creates a Micronaut profile |
|
|
Create-App
The create-app command will generate a basic Micronaut project, with optional flags to specify features, profile, and build tool. The project will include a default Application class for starting the application.
| Flag | Description | Example |
|---|---|---|
|
Build tool (one of |
|
|
Profile to use for the project (default is |
|
|
Features to use for the project, comma-separated |
or |
|
If present, generates the project in the current directory (project name is optional if this flag is set) |
|
Once created, the application can be started using the Application class, or the appropriate build tool task.
Starting a Gradle project
$ ./gradlew runStarting a Maven project
$ ./mvnw compile exec:execLanguage/Test Features
By default, create-app will generate a Java application, with JUnit configured as the test framework. The language and test framework settings for a given project are stored as the testFramework and sourceLanguage properties in the micronaut-cli.yml file, as shown below:
micronaut-cli.yml
profile: service
defaultPackage: my.demo.app
---
testFramework: junit
sourceLanguage: java
The values in micronaut-cli.yml are used by the CLI for code generation purposes. After a project has been generated, you can edit these values to change the project defaults, however you will still need to supply the required dependencies and/or configuration in order to use your chosen language/framework. E.g, you could edit the testFramework property to spock to cause the CLI to generate Spock tests when running commands (such as create-controller), but you will still need to add the Spock dependency to your project.
|
Groovy
To create an app with Groovy & Spock support, supply the appropriate features via the feature flag:
$ mn create-app my-groovy-app --features groovy,spockThis will include the Groovy & Spock dependencies in your project, and write the appropriates values in micronaut-cli.yml.
Kotlin
To create an app with Kotlin & Spek support, supply the appropriate features via the feature flag:
$ mn create-app my-kotlin-app --features kotlin,spekThis will include the Kotlin & Spek dependencies in your project, and write the appropriates values in micronaut-cli.yml.
Build Tool
By default create-app will create a Gradle project, with a build.gradle file at the root of the project directory. To create an app using the Maven build tool, supply the appropriate option via the build flag:
$ mn create-app my-maven-app --build mavenCreate-Cli-App
The create-cli-app command will generate a Micronaut command line application project,
with optional flags to specify language, test framework, features, profile, and build tool.
By default the project will have the picocli feature to support command line option parsing, and the cli profile to easily create additional commands.
The project will include a *Command class (based on the project name - e.g., hello-world will generate HelloWorldCommand),
and an associated test which will instantiate the command and verify that it can parse command line options.
| Flag | Description | Example |
|---|---|---|
|
Language to use for the command (one of |
|
|
Test framework to use for the command (one of |
|
|
Build tool (one of |
|
|
Profile to use for the project (default is |
|
|
Features to use for the project, comma-separated (picocli is included by default) |
or |
|
If present, generates the project in the current directory (project name is optional if this flag is set) |
|
Once created, the application can be started using the *Command class, or the appropriate build tool task.
Starting a Gradle project
$ ./gradlew runStarting a Maven project
$ ./mvnw compile exec:execLanguage/Test Features
By default, create-cli-app will generate a Java application, with JUnit configured as the test framework.
The language and test framework settings for a given project are stored as the testFramework and sourceLanguage properties in the micronaut-cli.yml file, as shown below:
micronaut-cli.yml
profile: cli
defaultPackage: my.demo.app
---
testFramework: junit
sourceLanguage: javaGroovy
To create an app with Groovy & Spock support, supply the appropriate features via the lang and test flags:
$ mn create-cli-app my-groovy-app --lang=groovy --test=spockThis will include the Groovy & Spock dependencies in your project, and write the appropriates values in micronaut-cli.yml.
Kotlin
To create an app with Kotlin & Spek support, supply the appropriate features via the lang and test flags:
$ mn create-cli-app my-kotlin-app --lang=kotlin --test=spekThis will include the Kotlin & Spek dependencies in your project, and write the appropriates values in micronaut-cli.yml.
Build Tool
By default create-cli-app will create a Gradle project, with a build.gradle file at the root of the project directory. To create an app using the Maven build tool, supply the appropriate option via the build flag:
$ mn create-cli-app my-maven-app --build mavenCreate-Function
The create-function command will generate a Micronaut function project, optimized for serverless environments, with optional flags to specify language, test framework, features and build tool. The project will include a *Function class (based on the project name - e.g., hello-world will generate HelloWorldFunction), and an associated test which will instantiate the function and verify that it can receive requests.
| Currently AWS Lambda is the only supported cloud provider for Micronaut functions, so some of the information below will be specific to that platform. Other cloud providers will be added soon and this section will be updated accordingly. |
| Flag | Description | Example |
|---|---|---|
|
Language to use for the function (one of |
|
|
Test framework to use for the function (one of |
|
|
Build tool (one of |
|
|
Features to use for the function, comma-separated |
or |
|
Provider to use for the function (currently the only supported provider is |
|
|
If present, generates the function in the current directory (function name is optional if this flag is set) |
|
Language
Setting the language using the lang flag will generate a *Function file in the appropriate language. For Java/Kotlin, this will generate a class annotated with @FunctionBean. For Groovy, a Groovy function script will be generated. See Writing Functions for more details on how to write and test Micronaut functions.
Depending on language choice, an appropriate test will also be generated. By default, a Java function will include a JUnit test, a Groovy function will include a Spock test, and a Kotlin function will include a Spek test. However, you can override the chosen test framework with the test flag.
$ mn create-function hello-world --lang java --test spockBuild Tool
Depending upon the build tool selected, the project will include various tasks for building/deploying the function.
Gradle
Functions with a Gradle build are preconfigured with the Gradle AWS Plugin. The configuration can be seen in the build.gradle file (see the section on Deploying Functions to AWS Lambda). Assuming valid AWS credentials under ~/.aws/credentials, the application can be deployed using the deploy task.
$ ./gradlew deployMaven
Functions with a Maven build are preconfigured with the Maven Shade Plugin, which will generate an executable JAR suitable for uploading to AWS Lambda. The JAR file can be built using the package phase.
$ ./mvnw packageFor further details, consult the AWS Lambda Documentation.
Create-Federation
The create-federation command accepts the same flags as the create-app command, and follows mostly the same behavior. The key difference is that this command accepts multiple project names following the services flag, and will generate a project (with the specified profile and features) for each name supplied. The [NAME] argument will be used to create the top-level multi-project build for the federation.
| Flag | Description | Example |
|---|---|---|
|
Comma-separated list of services (applications) to create |
|
|
Build tool (one of |
|
|
Profile to use for all projects in the federation (default is |
|
|
Features to use for all projects in the federation, comma-separated |
or |
|
If present, generates the project in the current directory (project name is optional if this flag is set) |
|
When creating a federation, a top-level project file will be generated (using the chosen build tool), and subprojects/modules will be created for each service in the federation.
Create-Profile
The create-profile command is used to generate new profiles for the Micronaut CLI.
| Flag | Description | Example |
|---|---|---|
|
Language to use for the profile (one of |
|
|
Build tool (one of |
|
|
Profile to extend |
|
|
Features to use, comma-separated |
|
|
If present, generates the profile in the current directory (profile name is optional if this flag is set) |
|
17.2 Profiles
Profiles are essentially project templates, consisting of a "skeleton" project structure with default configuration, build dependencies and other assets, along with a set of commands for generating appropriate artifacts (such as controllers, client interfaces, etc).
Profiles can inherit from other profiles, augmenting/overriding defaults set in their parent. All profiles inherit from the base profile, which provides the bare minimum required to set up a Micronaut application.
Many Micronaut apps (including projects generated by the create-app command) will use the service profile, which augments the base profile to add HTTP client/server libraries, create-controller and create-client commands, and other features that are appropriate for web service applications.
Other Micronaut apps (including projects generated by the create-cli-app command) may be interested in the cli profile, which adds the create-command command and the picocli library for command line parsing.
Profiles can be chosen using the profile flag on the create-app, create-cli-app, and create-federation commands.
$ mn create-app my-project17.2.1 Comparing Versions
The easiest way to see changes made to a fresh new app for a given profile between Micronaut versions is to use the next Github Repositories to generate a diff.
Application Profile |
service Default profile used by |
function profile used by |
17.3 Features
Features consist of additional dependencies and configuration to enable specific functionality in your application. The Micronaut profiles define a large number of features, including features for many of the configurations provided by Micronaut, such as the Data Access Configurations
$ mn create-app my-demo-app --features mongo-reactiveThis will add the necessary dependencies and configuration for the MongoDB Reactive Driver in your application. You can view all the available features using the profile-info command.
$ mn profile-info service
Profile: service
------------------
The service profile
...
Provided Features:
------------------
annotation-api Adds Java annotation API
config-consul Adds support for Distributed Configuration with Consul (https://www.consul.io)
discovery-consul Adds support for Service Discovery with Consul (https://www.consul.io)
discovery-eureka Adds support for Service Discovery with Eureka
groovy Creates a Groovy application
hibernate-gorm Adds support for GORM persistence framework
hibernate-jpa Adds support for Hibernate/JPA
http-client Adds support for creating HTTP clients
http-server Adds support for running a Netty server
java Creates a Java application
jdbc-dbcp Configures SQL DataSource instances using Commons DBCP
jdbc-hikari Configures SQL DataSource instances using Hikari Connection Pool
jdbc-tomcat Configures SQL DataSource instances using Tomcat Connection Pool
jrebel Adds support for class reloading with JRebel (requires separate JRebel installation)
junit Adds support for the JUnit testing framework
kafka Adds support for Kafka
kotlin Creates a Kotlin application
mongo-gorm Configures GORM for MongoDB for Groovy applications
mongo-reactive Adds support for the Mongo Reactive Streams Driver
neo4j-bolt Adds support for the Neo4j Bolt Driver
neo4j-gorm Configures GORM for Neo4j for Groovy applications
picocli Adds support for command line parsing (http://picocli.info)
redis-lettuce Configures the Lettuce driver for Redis
security-jwt Adds support for JWT (JSON Web Token) based Authentication
security-session Adds support for Session based Authentication
spek Adds support for the Spek testing framework
spock Adds support for the Spock testing framework
springloaded Adds support for class reloading with Spring-Loaded
tracing-jaeger Adds support for distributed tracing with Jaeger (https://www.jaegertracing.io)
tracing-zipkin Adds support for distributed tracing with Zipkin (https://zipkin.io)17.4 Commands
Profiles can include commands for generating common code artifacts. Not all commands are supported by all profiles; the available commands for a given profile can be viewed using the profile-info command.
$ mn profile-info service
Profile: service
------------------
The service profile
Provided Commands:
------------------
create-bean Creates a singleton bean
create-client Creates a client interface
create-controller Creates a controller and associated test
create-job Creates a job with scheduled method
help Prints help information for a specific command
Provided Features:
------------------
...All of the code-generation commands will honor the values written in micronaut-cli.yml. For example, assume the following micronaut-cli.yml file.
micronaut-cli.yml
profile: service
defaultPackage: example
---
testFramework: spock
sourceLanguage: javaWith the above settings, the create-controller command will (by default) generate Java controllers with an associated Spock test, under the example package. Commands accept arguments and these defaults can be overriden on a per-command basis.
Base Profile Commands
Commands in the base profile are inherited by all other profiles and are always available.
Create-Bean
| Flag | Description | Example |
|---|---|---|
|
The language used for the bean class |
|
|
Whether to overwrite existing files |
|
The create-bean command generates a simple Singleton class. It does not create an associated test.
$ mn create-bean EmailService
| Rendered template Bean.java to destination src/main/java/example/EmailService.javaCreate-Job
| Flag | Description | Example |
|---|---|---|
|
The language used for the job class |
|
|
Whether to overwrite existing files |
|
The create-job command generates a simple Scheduled class. It follows a *Job convention for generating the class name. It does not create an associated test.
$ mn create-job UpdateFeeds --lang groovy
| Rendered template Job.groovy to destination src/main/groovy/example/UpdateFeedsJob.groovyService Profile Commands
The service profile includes commands that are dependent upon the HTTP server and client dependencies (which are not included in the base profile).
Create-Controller
| Flag | Description | Example |
|---|---|---|
|
The language used for the controller |
|
|
Whether to overwrite existing files |
|
The create-controller command generates a Controller class. It follows a *Controller convention for generating the class name. It creates an associated test that will run the application and instantiate an HTTP client, which can make requests against the controller.
$ mn create-controller Book
| Rendered template Controller.java to destination src/main/java/example/BookController.java
| Rendered template ControllerTest.java to destination src/test/java/example/BookControllerTest.javaCreate-Client
| Flag | Description | Example |
|---|---|---|
|
The language used for the client |
|
|
Whether to overwrite existing files |
|
The create-client command generates a simple Client interface. It follows a *Client convention for generating the class name. It does not create an associated test.
$ mn create-client Book
| Rendered template Client.java to destination src/main/java/example/BookClient.javaCreate-Websocket-Server
| Flag | Description | Example |
|---|---|---|
|
The language used for the server |
|
|
Whether to overwrite existing files |
|
The create-websocket-server command generates a simple WebSocketServer class. It follows a *Server convention for generating the class name. It does not create an associated test.
$ mn create-websocket-server MyChat
| Rendered template WebsocketServer.java to destination src/main/java/example/MyChatServer.javaCreate-Websocket-Client
| Flag | Description | Example |
|---|---|---|
|
The language used for the client |
|
|
Whether to overwrite existing files |
|
The create-websocket-client command generates a simple WebSocketClient abstract class. It follows a *Client convention for generating the class name. It does not create an associated test.
$ mn create-websocket-client MyChat
| Rendered template WebsocketClient.java to destination src/main/java/example/MyChatClient.javaCLI Profile Commands
The cli profile lets you generate CLI commands to control your application.
Create-Command
| Flag | Description | Example |
|---|---|---|
|
The language used for the command |
|
|
Whether to overwrite existing files |
|
The create-command command generates a standalone application that can be executed as a
picocli Command.
It follows a *Command convention for generating the class name.
It creates an associated test that will run the application and verify that a command line option was set.
$ mn create-command print
| Rendered template Command.java to destination src/main/java/example/PrintCommand.java
| Rendered template CommandTest.java to destination src/test/java/example/PrintCommandTest.java17.5 Reloading
Reloading (or "hot-loading") refers to the framework reinitializing classes (and parts of the application) when changes to the source files are detected. Micronaut does not include specific support for reloading of changed classes at runtime. Since Micronaut prioritizes startup time and most Micronaut apps can start up within a couple seconds, a productive workflow can often be had by restarting the application as changes are made; for example, by running a test class within an IDE.
However, reloading support is available through the use of third-party JVM agents, along with automatic recompilation on file changes via a supporting build tool (such as Gradle) or IDE (such as Eclipse).
The following sections document how to configure agent-reloading.
17.5.1 JRebel
JRebel is a proprietary reloading solution that involves an agent library, as well as sophisticated IDE support. The JRebel documentation includes detailed steps for IDE integration and usage of the tool. In this section, we will simply show how to install and configure the agent for Maven and Gradle projects.
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features jrebel |
Install/configure JRebel Agent
The simplest way to install JRebel is to download the "standalone" installation package from the JRebel download page. Unzip the downloaded file to a convenient location within your user’s directory - for example, ~/bin/jrebel
The installation directory will contain a lib directory containing the agent files. The appropriate agent based on your operating system, following the table below:
| OS | Agent |
|---|---|
Windows 64-bit JDK |
|
Windows 32-bit JDK |
|
Mac OS X 64-bit JDK |
|
Mac OS X 32-bit JDK |
|
Linux 64-bit JDK |
|
Linux 32-bit JDK |
|
Note the path to the appropriate agent, and add the value to your project build.
Gradle
Add the path to gradle.properties (create the file if necessary), as the rebelAgent property.
gradle.properties
#Assuming installation path of ~/bin/jrebel/
rebelAgent= -agentpath:~/bin/jrebel/lib/libjrebel64.dylibAdd the appropriate JVM arg to build.gradle (not necessary if using the CLI feature)
run.dependsOn(generateRebel)
if (project.hasProperty('rebelAgent')) {
run.jvmArgs += rebelAgent
}You can start the application with ./gradlew run, and it will include the agent. See the section on Gradle Reloading or IDE Reloading to set up the recompilation.
Maven
Add the path to pom.xml as a build profile (if using the CLI feature, the profile jrebel is already provided - simply update the path to the agent JAR).
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<!-- ... -->
<profiles>
<profile>
<id>jrebel</id>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<configuration>
<executable>java</executable>
<arguments>
<argument>-noverify</argument>
<argument>-XX:TieredStopAtLevel=1</argument>
<argument>-agentpath:~/bin/jrebel/lib/jrebel6/lib/libjrebel64.dylib</argument>
<argument>-classpath</argument>
<classpath/>
<argument>${exec.mainClass}</argument>
</arguments>
</configuration>
</plugin>
</plugins>
</build>
</profile>
</profiles>
</project>17.5.2 Spring-Loaded
"Spring Loaded is a JVM agent for reloading class file changes whilst a JVM is running." (via the official README).
| Spring-Loaded is not actively maintained and currently only supports Java versions < 9. |
|
Using the CLI
If you are creating your project using the Micronaut CLI, supply the $ mn create-app my-app --features springloaded You can start the application with |
Configuration
Configuring Spring-Loaded requires the agent JAR file to be downloaded on your system, and configured to be loaded as a javaagent by the build tool (or IDE).
Gradle build.gradle example
run.jvmArgs('-noverify', '-javaagent:/usr/local/libs/springloaded/springloaded-1.2.8.RELEASE.jar')Maven pom.xml example
<project>
<!-- -->
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<configuration>
<executable>java</executable>
<arguments>
<argument>-noverify</argument> <!-- 1 -->
<argument>-javaagent:/usr/local/libs/springloaded/springloaded-1.2.8.RELEASE.jar</argument> <!-- 2 -->
</arguments>| 1 | Add noverify argument |
| 2 | Add javaagent argument |
You can now start the application with ./gradlew run (Gradle) or ./mvnw compile exec:exec (Maven).
17.5.3 Reloading with Gradle
Gradle supports continuous builds, allowing you to run a task that will be rerun every time the source files change. In order to make use of this with a reloading agent (configured as described above), you will run the application normally (with the agent), and then run a recompilation task in a separate terminal with continuous mode enabled.
Run the app
$ ./gradlew runRun the recompilation
$ ./gradlew -t classesThe classes task will be rerun every time a source file is modified, allowing the reloading agent to pick up the change.
17.5.4 Reloading with an IDE
If you are using a build tool such as Maven, which does not support automatic recompilation on file changes, you may choose to use your IDE to recompile classes in combination with a reloading agent (as configured in the above sections).
IntelliJ
IntelliJ unfortunately does not have an automatic rebuild option that works for a running application. However, you can trigger a "rebuild" of the project with CMD-F9 (Mac) or CTRL-F9 (Windows).
Eclipse
Under the Project menu, check the Build Automatically option. This will trigger a recompilation of the project whenever file changes are saved to disk.
17.6 Proxy Configuration
To configure the CLI to use an HTTP proxy there are two steps. Configuration options can be passed to the cli through the MN_OPTS environment variable.
For example on *nix systems:
export MN_OPTS="-Dhttps.proxyHost=127.0.0.1 -Dhttps.proxyPort=3128 -Dhttp.proxyUser=test -Dhttp.proxyPassword=test"The profile dependencies are resolved over HTTPS so the proxy port and host are configured with https., however the user and password are specified with http..
For Windows systems the environment variable can be configured under My Computer/Advanced/Environment Variables.
18 Appendices
18.1 Frequently Asked Questions (FAQ)
The following section covers frequently asked questions that you may find yourself asking while considering to use or using Micronaut.
Does Micronaut modify my byte code?
No. Your classes are your classes. Micronaut does not transform classes or modify the Java byte code you write. Micronaut at compile will produce an additional set of classes that sit next to your original untouched classes.
Why Doesn’t Micronaut use Spring?
When asking why Micronaut doesn’t use Spring, it is typically in reference to the Spring Dependency Injection container.
| The Spring ecosystem is very broad and there are many Spring libraries you can use directly in Micronaut without requiring the Spring container. |
The reason Micronaut features its own native JSR-305 compliant dependency injection is that the cost of these features in Spring (and any reflection based DI/AOP container) is too great in terms of memory consumption and the impact on startup time. In order to support dependency injection at runtime Spring:
-
Reads the byte code of every bean it finds at runtime.
-
Synthesizes new annotations for each annotation on each bean method, constructor, field etc. to support Annotation metadata.
-
Builds Reflective Metadata for each bean for every method, constructor, field etc.
The result is a progressive degradation of startup time and memory consumption as your application incorporates more features.
For Microservices and Serverless functions where it is critical that startup time and memory consumption remain low the above behaviour is an undesirable reality of using the Spring container, hence the designers of Micronaut chose not to use Spring.
Does Micronaut support Scala?
Micronaut supports any JVM language that supports the Annotation Processor API. Scala currently does not support this API. However, Groovy also doesn’t support this API and special support has been built that processes the Groovy AST. It may be technically possible to support Scala future if a similar module to inject-groovy is built, but as of this writing Scala is not supported.
Can Micronaut be used for purposes other than Microservices?
Yes. Micronaut is very modular and you can choose to use just the Dependency Injection and AOP implementation if you want simply by including only the micronaut-inject-java (or micronaut-inject-groovy for Groovy) dependency in your application.
In fact Micronaut’s support for Serverless Computing uses this exact approach.
What are the advantages of Micronaut’s Dependency Injection and AOP implementation?
Micronaut processes your classes at compile time and produces all metadata at compile time. This eliminates the need for reflection, cached reflective metadata and the requirement to analyze your classes at runtime all of which leads to slower startup performance and greater memory consumption.
In addition, Micronaut will build AOP proxies at compile time that are completely reflection free, which improves performances, reduces stack trace sizes and reduces memory consumption.
Why does Micronaut have its own Consul and Eureka client implementations?
The majority of Consul and Eureka clients that exist are blocking and include a mountain of external dependencies that inflate your JAR files.
Micronaut’s DiscoveryClient uses Micronaut’s native HTTP client thus greatly reducing the need for external dependencies and providing a reactive API onto both discovery servers.
Why am I encountering a NoSuchMethodError occurs loading my beans (Groovy)?
Groovy by default imports the groovy.lang package which includes a class called @Singleton that is an AST transformation that makes your class a singleton (adding a private constructor and static retrieval method). This annotation is easily confused with the javax.inject.Singleton annotation used to define singleton beans in Micronaut. Make sure you are using the correct annotation in your Groovy classes.
Why is it taking much longer than it should to start the application
Micronaut’s startup time is typically very fast. At the application level, however, it is possible to block startup time so if you are seeing slow startup, review if you have any application startup listeners or @Context scope beans that are slowing startup.
Some network issues can, also cause slow startup. On the Mac for example misconfiguration of your /etc/hosts file can cause issues. See the following stackoverflow answer.
18.2 Using Snapshots
Micronaut milestone and stable releases are distributed to Bintray.
The following snippet shows how to use Micronaut BUILD-SNAPSHOT with Gradle:
ext {
micronautVersion = '1.0.0.BUILD-SNAPSHOT'
}
repositories {
mavenLocal()
mavenCentral()
jcenter() (1)
maven { url "https://oss.sonatype.org/content/repositories/snapshots/" } (2)
}
dependencyManagement {
imports {
mavenBom "io.micronaut:micronaut-bom:$micronautVersion"
}
}| 1 | Micronaut releases are available on jcenter |
| 2 | Micronaut snapshots are available on sonatype |
18.3 Common Problems
The following section covers common problems folks stumble upon when using Micronaut.
Dependency injection is not working
The most common reason that Dependency Injection fails to work is when you either don’t have the appropriate annotation processor configured or your IDE is incorrectly configured. See the section on Language Support for how to get setup in your language.
A NoSuchMethodError occurs loading beans (Groovy)
Groovy by default imports the groovy.lang package which includes a class called @Singleton that is an AST transformation that makes your class a singleton (adding a private constructor and static retrieval method). This annotation is easily confused with the javax.inject.Singleton annotation used to define singleton beans in Micronaut. Make sure you are using the correct annotation in your Groovy classes.
It is taking much longer to start my application than it should (MacOS)
This is likely due to a bug in MacOS that has to do with executions of java.net.InetAddress.getLocalHost() causing a long delay. The solution is to edit your /etc/hosts file to add an entry that contains your host name. To find your host name, simply enter hostname in the terminal and the value will be output. Then edit your /etc/hosts file to add or change entries like the example below, replacing <hostname> with your host name.
127.0.0.1 localhost <hostname> ::1 localhost <hostname>
To learn more about this issue, see this stackoverflow answer
18.4 Breaking Changes
This section will document breaking changes that may happen during milestone or release candidate releases, as well as major releases eg (1.x.x → 2.x.x).
1.0.0.RC3
-
All Micronaut modules have been renamed to include
micronaut-prefix to make it easier to manage dependencies. If you are upgrading rename all references modules. Examplebom→micronaut-bom,inject→micronaut-injectetc. -
Methods for JWT signature generation have been removed from RSASignatureConfiguration or ECSignatureConfiguration. Those beans should be used in microservices where you need only signature verification and not generation.
To enable a RSA or EC JWT signature generation, you need to have in your app a bean of type RSASignatureGeneratorConfiguration or ECSignatureGeneratorConfiguration.
1.0.0.RC2
-
io.micronaut.security.authentication.Authenticator::authenticatemethod signature has changed from:
public Publisher<AuthenticationResponse> authenticate(UsernamePasswordCredentials credentials)
to:
public Publisher<AuthenticationResponse> authenticate(AuthenticationRequest authenticationRequest)
1.0.0.RC1
-
The default port if no port is specified is now port 8080 instead of a random port, except in the test environment. A random port can be obtained by setting the port to -1.
-
The configuration for static resource has been changed to allow multiple mappings, each with their own set of paths. This will allow accessing resources at multiple URLs. Previously the configuration might have looked like:
micronaut: router: static: resources: enabled: true mapping: /static/** paths: - classpath:staticAnd now the equivalent configuration would be:
micronaut: router: static-resources: default: enabled: true mapping: /static/** paths: - classpath:staticThe word
defaultin that example is arbitrary and can be replaced with any name that is appropriate to describe the category of resources that will be served.Notice the change from static.resourcestostatic-resources. -
The CLI feature for Netflix Archaius was incorrectly named
netflix-archius. The feature has now been renamed to reflect the correct name,netflix-archaius. -
The intercept url map security rule now no longer considers the query part of the request when determining if the request matches. Previously
/?value=truewould not match/. -
Several APIs surrounding route URI matching and template parsing have changed to allow more information to be retrieved from the parsing process.
-
The following packages have been renamed:
io.micronaut.http.server.binding -> io.micronaut.http.bind
-
The following annotations have been moved to new locations:
io.micronaut.http.client.Client -> io.micronaut.http.client.annotation.Client io.micronaut.security.Secured -> io.micronaut.security.annotation.Secured
-
The jackson deserialization features ACCEPT_SINGLE_VALUE_AS_ARRAY and UNWRAP_SINGLE_VALUE_ARRAYS are now enabled by default. To revert to the previous behavior, see the section on Jackson Configuration for information on how to customize deserialization features.
1.0.0.M4
-
Libraries compiled against earlier versions of Micronaut are not binary compatible with this release.
-
The Java module names generated in previous versions were invalid because they contained a
-. Module names with dashes were converted to an underscore. For example:io.micronaut.inject-java→io.micronaut.inject_java. -
The annotation metadata API has been changed to no longer use reflective proxies for annotations. The methods that used to return the proxies now return an
AnnotationValuethat contains all of the data that existed in the proxy. The methods to create the proxies now exist undersynthesize... -
Many classes no longer implement
AnnotatedElement. -
AnnotationUtilhas seen significant changes and is now marked as an internal class. -
BeanContext.getBeanRegistrationshas been renamed toBeanContext.getActiveBeanRegistrations. -
Endpoint annotations have moved packages:
io.micronaut.management.endpoint→io.micronaut.management.endpoint.annotation. -
Endpoint method arguments were previously included in the route URI by default. Now endpoint arguments are not included in the route URI by default. An annotation,
@Selectorhas been added to indicate an endpoint argument should be included in the URI. -
The
@Controllerannotation now requires a value. Previously a convention was used to determine the URI. -
The
HttpMethodMappingannotations (@Get,@Put, etc) have changed their default behavior. They no longer use a convention based off the method name if the URI was not provided. The URI is still not required, however it now defaults to/. The new default means the method will be accessible from the controller URI.
1.0.0.M3
-
The contract for
io.micronaut.http.codec.MediaTypeCodechas changed to support multiple media types. -
To reduce confusion around
@Parameter, it can no longer be used to denote an argument should be bound from the request url. Its sole purpose is defining arguments for parameterized beans. Use@QueryValueinstead. -
The health endpoint will now only report details when the user is authenticated. To revert to the previous behavior, set
endpoints.health.detailsVisible: ANONYMOUS. -
The CLI options have been standardized to use two leading dashes for long options (like
--stacktrace) and one for shortcuts (like-h). That means that some options no longer work. For example, this command used to work with M2:create-app -lang groovy myapp. From M3, you will see this error:Could not convert 'ang' to SupportedLanguage for option '--lang'. Specifying either-l LANGor--lang LANGworks as expected. -
The following packages have been renamed:
-
io.micronaut.configurations.ribbon→io.micronaut.configuration.ribbon -
io.micronaut.configurations.hystrix→io.micronaut.configuration.hystrix -
io.micronaut.configurations.aws→io.micronaut.configuration.aws -
io.micronaut.http.netty.buffer→io.micronaut.buffer.netty
-
-
The default Consul configuration prefix has been changed to reflect changes in the latest version of Consul. Previously a leading slash was expected and the default value was
/config/. The new default value isconfig/. To restore the previous behavior, setconsul.client.config.path = /config/ -
The
sessionmodule will now serialize POJOs to JSON using Jackson by default instead of Java Serialization. This change is because Java serialization will be removed and deprecated in a future version of the JDK.
1.0.0.M2
-
The constructor signature for DefaultHttpClient has changed to include an extra argument. This change should not impact existing uses.
-
Libraries compiled against M1 are not binary compatible with M2.
-
For Java 9+ automatic module name has been set to
<groupId>.<name>. Previously if you have been using the "inject-java" module, the module is now named "io.micronaut.inject-java". -
When an HttpClientResponseException is thrown, the body of the response will be set to the exception message for responses with a text media type. Previously the status description was returned.
-
Mongo configurations were updated to a new version of the driver (3.6.1 → 3.7.1), which may break existing uses. See their upgrading page for more information.
-
The
routerconfiguration key was changed to bemicronaut.router. Static resource configuration is affected by this change. Please update your configuration:router.static.resources→micronaut.router.static.resources.